 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServing Large Language Models on Huawei CloudMatrix384
Jun 15, 2025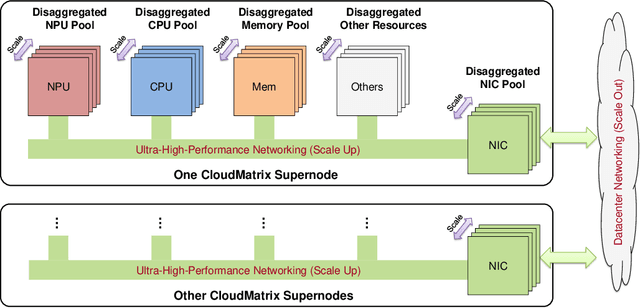
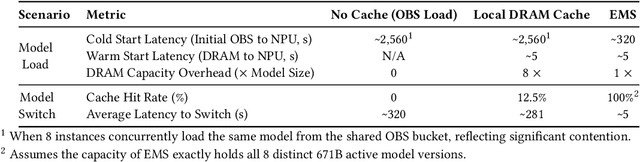
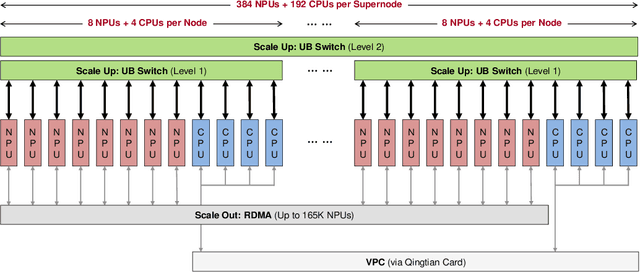
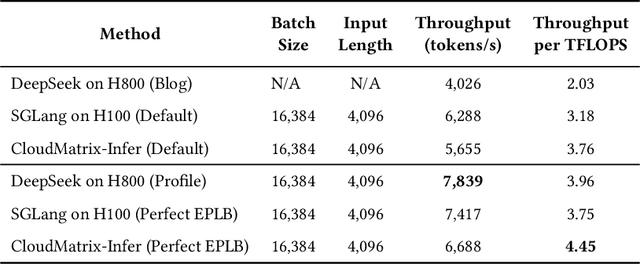
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
Injecting Adrenaline into LLM Serving: Boosting Resource Utilization and Throughput via Attention Disaggregation
Mar 26, 2025In large language model (LLM) serving systems, executing each request consists of two phases: the compute-intensive prefill phase and the memory-intensive decoding phase. To prevent performance interference between the two phases, current LLM serving systems typically adopt prefill-decoding disaggregation, where the two phases are split across separate machines. However, we observe this approach leads to significant resource underutilization. Specifically, prefill instances that are compute-intensive suffer from low memory utilization, while decoding instances that are memory-intensive experience low compute utilization. To address this problem, this paper proposes Adrenaline, an attention disaggregation and offloading mechanism designed to enhance resource utilization and performance in LLM serving systems. Adrenaline's key innovation lies in disaggregating part of the attention computation in the decoding phase and offloading them to prefill instances. The memory-bound nature of decoding-phase attention computation inherently enables an effective offloading strategy, yielding two complementary advantages: 1) improved memory capacity and bandwidth utilization in prefill instances, and 2) increased decoding batch sizes that enhance compute utilization in decoding instances, collectively boosting overall system performance. Adrenaline achieves these gains through three key techniques: low-latency decoding synchronization, resource-efficient prefill colocation, and load-aware offloading scheduling. Experimental results show that Adrenaline achieves 2.28x higher memory capacity and 2.07x better memory bandwidth utilization in prefill instances, up to 1.67x improvements in compute utilization for decoding instances, and 1.68x higher overall inference throughput compared to state-of-the-art systems.