 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Throughput LLM inference on Heterogeneous Clusters
Apr 18, 2025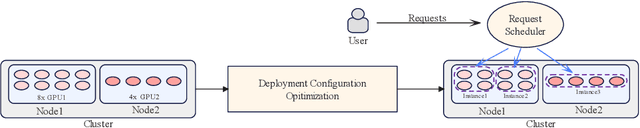
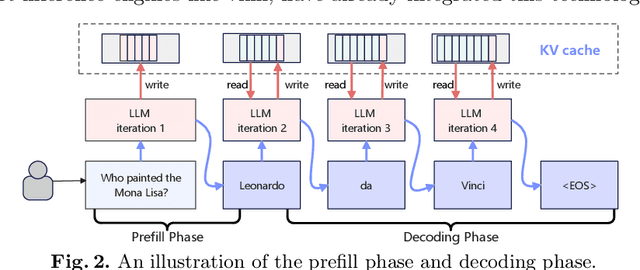


Nowadays, many companies possess various types of AI accelerators, forming heterogeneous clusters. Efficiently leveraging these clusters for high-throughput large language model (LLM) inference services can significantly reduce costs and expedite task processing. However, LLM inference on heterogeneous clusters presents two main challenges. Firstly, different deployment configurations can result in vastly different performance. The number of possible configurations is large, and evaluating the effectiveness of a specific setup is complex. Thus, finding an optimal configuration is not an easy task. Secondly, LLM inference instances within a heterogeneous cluster possess varying processing capacities, leading to different processing speeds for handling inference requests. Evaluating these capacities and designing a request scheduling algorithm that fully maximizes the potential of each instance is challenging. In this paper, we propose a high-throughput inference service system on heterogeneous clusters. First, the deployment configuration is optimized by modeling the resource amount and expected throughput and using the exhaustive search method. Second, a novel mechanism is proposed to schedule requests among instances, which fully considers the different processing capabilities of various instances. Extensive experiments show that the proposed scheduler improves throughput by 122.5% and 33.6% on two heterogeneous clusters, respectively.