 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrban Socio-Semantic Segmentation with Vision-Language Reasoning
Jan 15, 2026As hubs of human activity, urban surfaces consist of a wealth of semantic entities. Segmenting these various entities from satellite imagery is crucial for a range of downstream applications. Current advanced segmentation models can reliably segment entities defined by physical attributes (e.g., buildings, water bodies) but still struggle with socially defined categories (e.g., schools, parks). In this work, we achieve socio-semantic segmentation by vision-language model reasoning. To facilitate this, we introduce the Urban Socio-Semantic Segmentation dataset named SocioSeg, a new resource comprising satellite imagery, digital maps, and pixel-level labels of social semantic entities organized in a hierarchical structure. Additionally, we propose a novel vision-language reasoning framework called SocioReasoner that simulates the human process of identifying and annotating social semantic entities via cross-modal recognition and multi-stage reasoning. We employ reinforcement learning to optimize this non-differentiable process and elicit the reasoning capabilities of the vision-language model. Experiments demonstrate our approach's gains over state-of-the-art models and strong zero-shot generalization. Our dataset and code are available in https://github.com/AMAP-ML/SocioReasoner.
MapGlue: Multimodal Remote Sensing Image Matching
Mar 20, 2025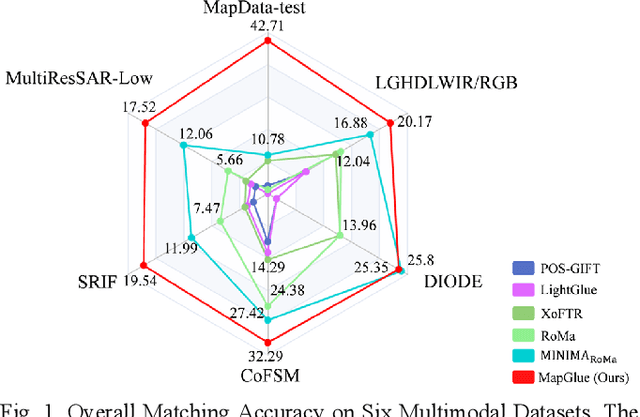
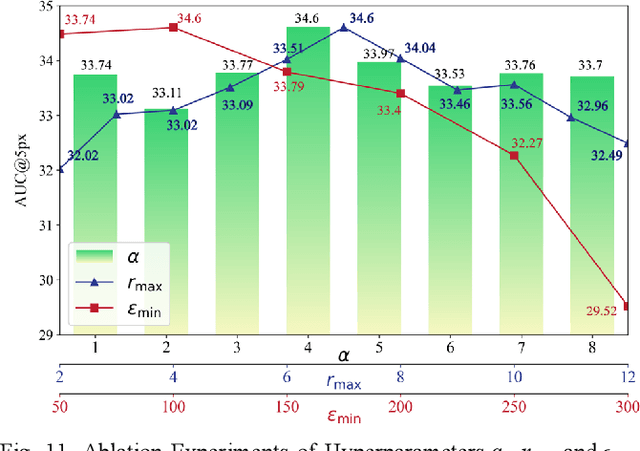
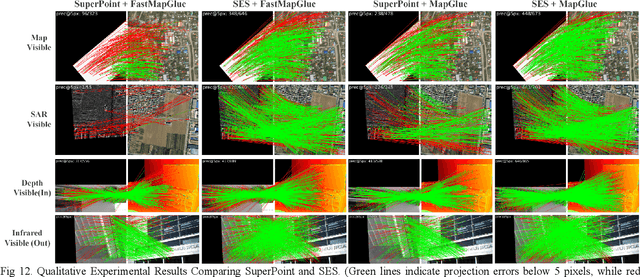

Multimodal remote sensing image (MRSI) matching is pivotal for cross-modal fusion, localization, and object detection, but it faces severe challenges due to geometric, radiometric, and viewpoint discrepancies across imaging modalities. Existing unimodal datasets lack scale and diversity, limiting deep learning solutions. This paper proposes MapGlue, a universal MRSI matching framework, and MapData, a large-scale multimodal dataset addressing these gaps. Our contributions are twofold. MapData, a globally diverse dataset spanning 233 sampling points, offers original images (7,000x5,000 to 20,000x15,000 pixels). After rigorous cleaning, it provides 121,781 aligned electronic map-visible image pairs (512x512 pixels) with hybrid manual-automated ground truth, addressing the scarcity of scalable multimodal benchmarks. MapGlue integrates semantic context with a dual graph-guided mechanism to extract cross-modal invariant features. This structure enables global-to-local interaction, enhancing descriptor robustness against modality-specific distortions. Extensive evaluations on MapData and five public datasets demonstrate MapGlue's superiority in matching accuracy under complex conditions, outperforming state-of-the-art methods. Notably, MapGlue generalizes effectively to unseen modalities without retraining, highlighting its adaptability. This work addresses longstanding challenges in MRSI matching by combining scalable dataset construction with a robust, semantics-driven framework. Furthermore, MapGlue shows strong generalization capabilities on other modality matching tasks for which it was not specifically trained. The dataset and code are available at https://github.com/PeihaoWu/MapGlue.
Towards Privacy-preserved Pre-training of Remote Sensing Foundation Models with Federated Mutual-guidance Learning
Mar 14, 2025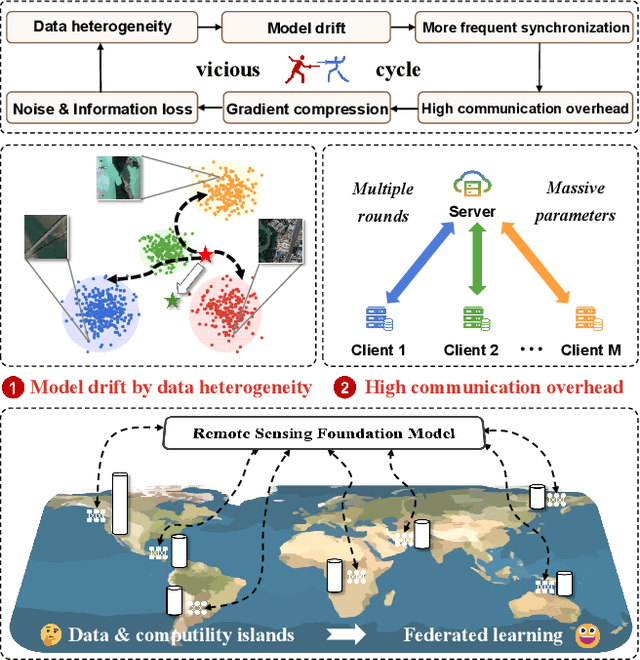
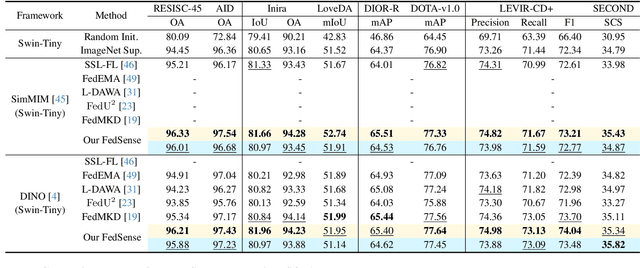
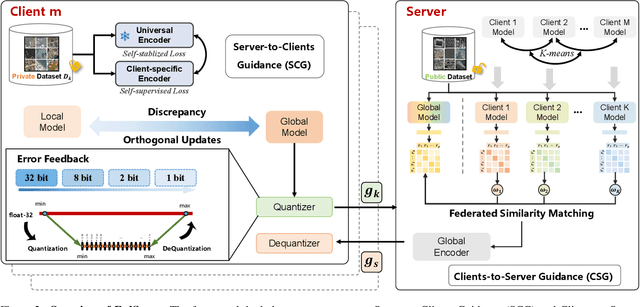
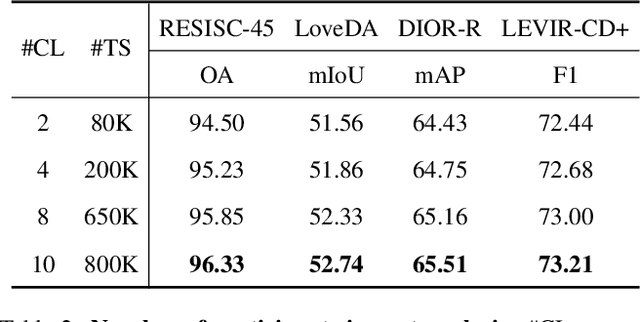
Traditional Remote Sensing Foundation models (RSFMs) are pre-trained with a data-centralized paradigm, through self-supervision on large-scale curated remote sensing data. For each institution, however, pre-training RSFMs with limited data in a standalone manner may lead to suboptimal performance, while aggregating remote sensing data from multiple institutions for centralized pre-training raises privacy concerns. Seeking for collaboration is a promising solution to resolve this dilemma, where multiple institutions can collaboratively train RSFMs without sharing private data. In this paper, we propose a novel privacy-preserved pre-training framework (FedSense), which enables multiple institutions to collaboratively train RSFMs without sharing private data. However, it is a non-trivial task hindered by a vicious cycle, which results from model drift by remote sensing data heterogeneity and high communication overhead. To break this vicious cycle, we introduce Federated Mutual-guidance Learning. Specifically, we propose a Server-to-Clients Guidance (SCG) mechanism to guide clients updates towards global-flatness optimal solutions. Additionally, we propose a Clients-to-Server Guidance (CSG) mechanism to inject local knowledge into the server by low-bit communication. Extensive experiments on four downstream tasks demonstrate the effectiveness of our FedSense in both full-precision and communication-reduced scenarios, showcasing remarkable communication efficiency and performance gains.
MEET: A Million-Scale Dataset for Fine-Grained Geospatial Scene Classification with Zoom-Free Remote Sensing Imagery
Mar 14, 2025Accurate fine-grained geospatial scene classification using remote sensing imagery is essential for a wide range of applications. However, existing approaches often rely on manually zooming remote sensing images at different scales to create typical scene samples. This approach fails to adequately support the fixed-resolution image interpretation requirements in real-world scenarios. To address this limitation, we introduce the Million-scale finE-grained geospatial scEne classification dataseT (MEET), which contains over 1.03 million zoom-free remote sensing scene samples, manually annotated into 80 fine-grained categories. In MEET, each scene sample follows a scene-inscene layout, where the central scene serves as the reference, and auxiliary scenes provide crucial spatial context for finegrained classification. Moreover, to tackle the emerging challenge of scene-in-scene classification, we present the Context-Aware Transformer (CAT), a model specifically designed for this task, which adaptively fuses spatial context to accurately classify the scene samples. CAT adaptively fuses spatial context to accurately classify the scene samples by learning attentional features that capture the relationships between the center and auxiliary scenes. Based on MEET, we establish a comprehensive benchmark for fine-grained geospatial scene classification, evaluating CAT against 11 competitive baselines. The results demonstrate that CAT significantly outperforms these baselines, achieving a 1.88% higher balanced accuracy (BA) with the Swin-Large backbone, and a notable 7.87% improvement with the Swin-Huge backbone. Further experiments validate the effectiveness of each module in CAT and show the practical applicability of CAT in the urban functional zone mapping. The source code and dataset will be publicly available at https://jerrywyn.github.io/project/MEET.html.
When Large Vision-Language Model Meets Large Remote Sensing Imagery: Coarse-to-Fine Text-Guided Token Pruning
Mar 10, 2025Efficient vision-language understanding of large Remote Sensing Images (RSIs) is meaningful but challenging. Current Large Vision-Language Models (LVLMs) typically employ limited pre-defined grids to process images, leading to information loss when handling gigapixel RSIs. Conversely, using unlimited grids significantly increases computational costs. To preserve image details while reducing computational complexity, we propose a text-guided token pruning method with Dynamic Image Pyramid (DIP) integration. Our method introduces: (i) a Region Focus Module (RFM) that leverages text-aware region localization capability to identify critical vision tokens, and (ii) a coarse-to-fine image tile selection and vision token pruning strategy based on DIP, which is guided by RFM outputs and avoids directly processing the entire large imagery. Additionally, existing benchmarks for evaluating LVLMs' perception ability on large RSI suffer from limited question diversity and constrained image sizes. We construct a new benchmark named LRS-VQA, which contains 7,333 QA pairs across 8 categories, with image length up to 27,328 pixels. Our method outperforms existing high-resolution strategies on four datasets using the same data. Moreover, compared to existing token reduction methods, our approach demonstrates higher efficiency under high-resolution settings. Dataset and code are in https://github.com/VisionXLab/LRS-VQA.
Wholly-WOOD: Wholly Leveraging Diversified-quality Labels for Weakly-supervised Oriented Object Detection
Feb 13, 2025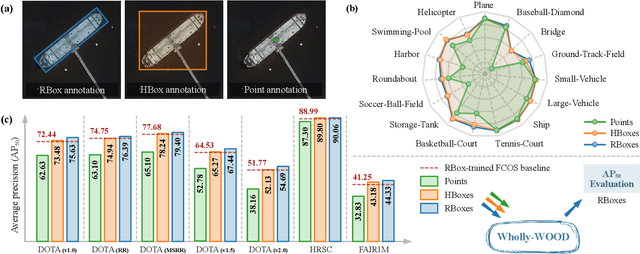
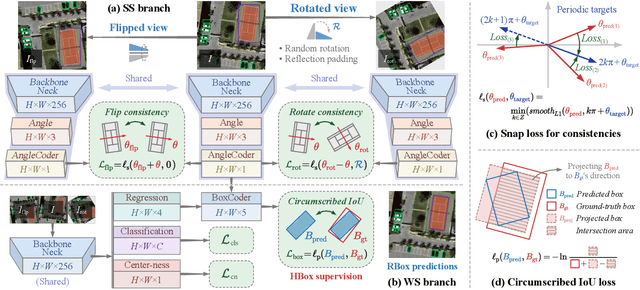
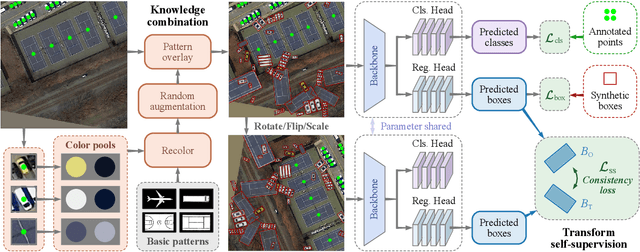
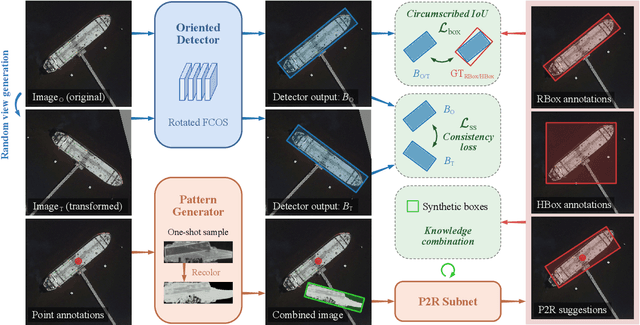
Accurately estimating the orientation of visual objects with compact rotated bounding boxes (RBoxes) has become a prominent demand, which challenges existing object detection paradigms that only use horizontal bounding boxes (HBoxes). To equip the detectors with orientation awareness, supervised regression/classification modules have been introduced at the high cost of rotation annotation. Meanwhile, some existing datasets with oriented objects are already annotated with horizontal boxes or even single points. It becomes attractive yet remains open for effectively utilizing weaker single point and horizontal annotations to train an oriented object detector (OOD). We develop Wholly-WOOD, a weakly-supervised OOD framework, capable of wholly leveraging various labeling forms (Points, HBoxes, RBoxes, and their combination) in a unified fashion. By only using HBox for training, our Wholly-WOOD achieves performance very close to that of the RBox-trained counterpart on remote sensing and other areas, significantly reducing the tedious efforts on labor-intensive annotation for oriented objects. The source codes are available at https://github.com/VisionXLab/whollywood (PyTorch-based) and https://github.com/VisionXLab/whollywood-jittor (Jittor-based).
Multi-Resolution SAR and Optical Remote Sensing Image Registration Methods: A Review, Datasets, and Future Perspectives
Feb 03, 2025



Synthetic Aperture Radar (SAR) and optical image registration is essential for remote sensing data fusion, with applications in military reconnaissance, environmental monitoring, and disaster management. However, challenges arise from differences in imaging mechanisms, geometric distortions, and radiometric properties between SAR and optical images. As image resolution increases, fine SAR textures become more significant, leading to alignment issues and 3D spatial discrepancies. Two major gaps exist: the lack of a publicly available multi-resolution, multi-scene registration dataset and the absence of systematic analysis of current methods. To address this, the MultiResSAR dataset was created, containing over 10k pairs of multi-source, multi-resolution, and multi-scene SAR and optical images. Sixteen state-of-the-art algorithms were tested. Results show no algorithm achieves 100% success, and performance decreases as resolution increases, with most failing on sub-meter data. XoFTR performs best among deep learning methods (40.58%), while RIFT performs best among traditional methods (66.51%). Future research should focus on noise suppression, 3D geometric fusion, cross-view transformation modeling, and deep learning optimization for robust registration of high-resolution SAR and optical images. The dataset is available at https://github.com/betterlll/Multi-Resolution-SAR-dataset-.
PointOBB-v3: Expanding Performance Boundaries of Single Point-Supervised Oriented Object Detection
Jan 23, 2025



With the growing demand for oriented object detection (OOD), recent studies on point-supervised OOD have attracted significant interest. In this paper, we propose PointOBB-v3, a stronger single point-supervised OOD framework. Compared to existing methods, it generates pseudo rotated boxes without additional priors and incorporates support for the end-to-end paradigm. PointOBB-v3 functions by integrating three unique image views: the original view, a resized view, and a rotated/flipped (rot/flp) view. Based on the views, a scale augmentation module and an angle acquisition module are constructed. In the first module, a Scale-Sensitive Consistency (SSC) loss and a Scale-Sensitive Feature Fusion (SSFF) module are introduced to improve the model's ability to estimate object scale. To achieve precise angle predictions, the second module employs symmetry-based self-supervised learning. Additionally, we introduce an end-to-end version that eliminates the pseudo-label generation process by integrating a detector branch and introduces an Instance-Aware Weighting (IAW) strategy to focus on high-quality predictions. We conducted extensive experiments on the DIOR-R, DOTA-v1.0/v1.5/v2.0, FAIR1M, STAR, and RSAR datasets. Across all these datasets, our method achieves an average improvement in accuracy of 3.56% in comparison to previous state-of-the-art methods. The code will be available at https://github.com/ZpyWHU/PointOBB-v3.
Fine-Grained Scene Graph Generation via Sample-Level Bias Prediction
Jul 27, 2024



Scene Graph Generation (SGG) aims to explore the relationships between objects in images and obtain scene summary graphs, thereby better serving downstream tasks. However, the long-tailed problem has adversely affected the scene graph's quality. The predictions are dominated by coarse-grained relationships, lacking more informative fine-grained ones. The union region of one object pair (i.e., one sample) contains rich and dedicated contextual information, enabling the prediction of the sample-specific bias for refining the original relationship prediction. Therefore, we propose a novel Sample-Level Bias Prediction (SBP) method for fine-grained SGG (SBG). Firstly, we train a classic SGG model and construct a correction bias set by calculating the margin between the ground truth label and the predicted label with one classic SGG model. Then, we devise a Bias-Oriented Generative Adversarial Network (BGAN) that learns to predict the constructed correction biases, which can be utilized to correct the original predictions from coarse-grained relationships to fine-grained ones. The extensive experimental results on VG, GQA, and VG-1800 datasets demonstrate that our SBG outperforms the state-of-the-art methods in terms of Average@K across three mainstream SGG models: Motif, VCtree, and Transformer. Compared to dataset-level correction methods on VG, SBG shows a significant average improvement of 5.6%, 3.9%, and 3.2% on Average@K for tasks PredCls, SGCls, and SGDet, respectively. The code will be available at https://github.com/Zhuzi24/SBG.
SkySenseGPT: A Fine-Grained Instruction Tuning Dataset and Model for Remote Sensing Vision-Language Understanding
Jun 14, 2024Remote Sensing Large Multi-Modal Models (RSLMMs) are developing rapidly and showcase significant capabilities in remote sensing imagery (RSI) comprehension. However, due to the limitations of existing datasets, RSLMMs have shortcomings in understanding the rich semantic relations among objects in complex remote sensing scenes. To unlock RSLMMs' complex comprehension ability, we propose a large-scale instruction tuning dataset FIT-RS, containing 1,800,851 instruction samples. FIT-RS covers common interpretation tasks and innovatively introduces several complex comprehension tasks of escalating difficulty, ranging from relation reasoning to image-level scene graph generation. Based on FIT-RS, we build the FIT-RSFG benchmark. Furthermore, we establish a new benchmark to evaluate the fine-grained relation comprehension capabilities of LMMs, named FIT-RSRC. Based on combined instruction data, we propose SkySenseGPT, which achieves outstanding performance on both public datasets and FIT-RSFG, surpassing existing RSLMMs. We hope the FIT-RS dataset can enhance the relation comprehension capability of RSLMMs and provide a large-scale fine-grained data source for the remote sensing community. The dataset will be available at https://github.com/Luo-Z13/SkySenseGPT