 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePulseMind: A Multi-Modal Medical Model for Real-World Clinical Diagnosis
Jan 12, 2026Recent advances in medical multi-modal models focus on specialized image analysis like dermatology, pathology, or radiology. However, they do not fully capture the complexity of real-world clinical diagnostics, which involve heterogeneous inputs and require ongoing contextual understanding during patient-physician interactions. To bridge this gap, we introduce PulseMind, a new family of multi-modal diagnostic models that integrates a systematically curated dataset, a comprehensive evaluation benchmark, and a tailored training framework. Specifically, we first construct a diagnostic dataset, MediScope, which comprises 98,000 real-world multi-turn consultations and 601,500 medical images, spanning over 10 major clinical departments and more than 200 sub-specialties. Then, to better reflect the requirements of real-world clinical diagnosis, we develop the PulseMind Benchmark, a multi-turn diagnostic consultation benchmark with a four-dimensional evaluation protocol comprising proactiveness, accuracy, usefulness, and language quality. Finally, we design a training framework tailored for multi-modal clinical diagnostics, centered around a core component named Comparison-based Reinforcement Policy Optimization (CRPO). Compared to absolute score rewards, CRPO uses relative preference signals from multi-dimensional com-parisons to provide stable and human-aligned training guidance. Extensive experiments demonstrate that PulseMind achieves competitive performance on both the diagnostic consultation benchmark and public medical benchmarks.
Cross-View Geo-Localization with Street-View and VHR Satellite Imagery in Decentrality Settings
Dec 16, 2024Cross-View Geo-Localization tackles the problem of image geo-localization in GNSS-denied environments by matching street-view query images with geo-tagged aerial-view reference images. However, existing datasets and methods often assume center-aligned settings or only consider limited decentrality (i.e., the offset of the query image from the reference image center). This assumption overlooks the challenges present in real-world applications, where large decentrality can significantly enhance localization efficiency but simultaneously lead to a substantial degradation in localization accuracy. To address this limitation, we introduce CVSat, a novel dataset designed to evaluate cross-view geo-localization with a large geographic scope and diverse landscapes, emphasizing the decentrality issue. Meanwhile, we propose AuxGeo (Auxiliary Enhanced Geo-Localization), which leverages a multi-metric optimization strategy with two novel modules: the Bird's-eye view Intermediary Module (BIM) and the Position Constraint Module (PCM). BIM uses bird's-eye view images derived from street-view panoramas as an intermediary, simplifying the cross-view challenge with decentrality to a cross-view problem and a decentrality problem. PCM leverages position priors between cross-view images to establish multi-grained alignment constraints. These modules improve the performance of cross-view geo-localization with the decentrality problem. Extensive experiments demonstrate that AuxGeo outperforms previous methods on our proposed CVSat dataset, mitigating the issue of large decentrality, and also achieves state-of-the-art performance on existing public datasets such as CVUSA, CVACT, and VIGOR.
HomoMatcher: Dense Feature Matching Results with Semi-Dense Efficiency by Homography Estimation
Nov 11, 2024
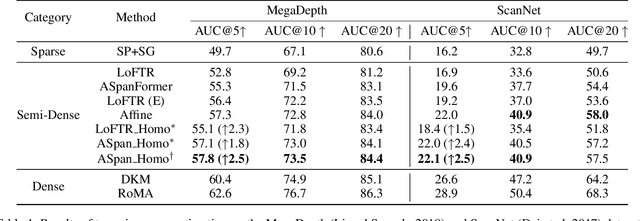
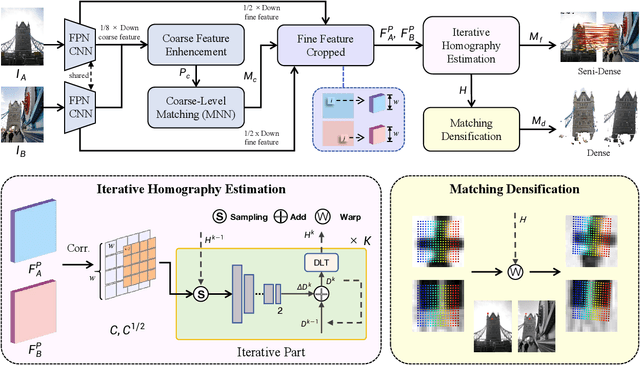
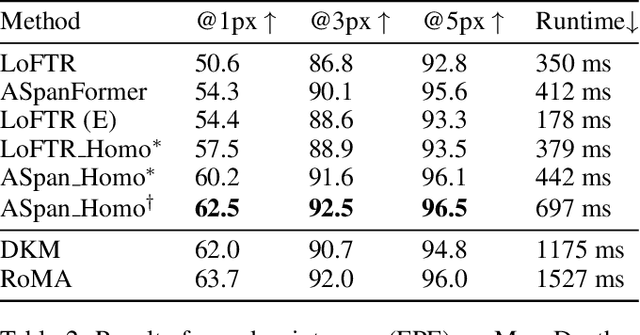
Feature matching between image pairs is a fundamental problem in computer vision that drives many applications, such as SLAM. Recently, semi-dense matching approaches have achieved substantial performance enhancements and established a widely-accepted coarse-to-fine paradigm. However, the majority of existing methods focus on improving coarse feature representation rather than the fine-matching module. Prior fine-matching techniques, which rely on point-to-patch matching probability expectation or direct regression, often lack precision and do not guarantee the continuity of feature points across sequential images. To address this limitation, this paper concentrates on enhancing the fine-matching module in the semi-dense matching framework. We employ a lightweight and efficient homography estimation network to generate the perspective mapping between patches obtained from coarse matching. This patch-to-patch approach achieves the overall alignment of two patches, resulting in a higher sub-pixel accuracy by incorporating additional constraints. By leveraging the homography estimation between patches, we can achieve a dense matching result with low computational cost. Extensive experiments demonstrate that our method achieves higher accuracy compared to previous semi-dense matchers. Meanwhile, our dense matching results exhibit similar end-point-error accuracy compared to previous dense matchers while maintaining semi-dense efficiency.
POA: Pre-training Once for Models of All Sizes
Aug 02, 2024



Large-scale self-supervised pre-training has paved the way for one foundation model to handle many different vision tasks. Most pre-training methodologies train a single model of a certain size at one time. Nevertheless, various computation or storage constraints in real-world scenarios require substantial efforts to develop a series of models with different sizes to deploy. Thus, in this study, we propose a novel tri-branch self-supervised training framework, termed as POA (Pre-training Once for All), to tackle this aforementioned issue. Our approach introduces an innovative elastic student branch into a modern self-distillation paradigm. At each pre-training step, we randomly sample a sub-network from the original student to form the elastic student and train all branches in a self-distilling fashion. Once pre-trained, POA allows the extraction of pre-trained models of diverse sizes for downstream tasks. Remarkably, the elastic student facilitates the simultaneous pre-training of multiple models with different sizes, which also acts as an additional ensemble of models of various sizes to enhance representation learning. Extensive experiments, including k-nearest neighbors, linear probing evaluation and assessments on multiple downstream tasks demonstrate the effectiveness and advantages of our POA. It achieves state-of-the-art performance using ViT, Swin Transformer and ResNet backbones, producing around a hundred models with different sizes through a single pre-training session. The code is available at: https://github.com/Qichuzyy/POA.
SkySenseGPT: A Fine-Grained Instruction Tuning Dataset and Model for Remote Sensing Vision-Language Understanding
Jun 14, 2024Remote Sensing Large Multi-Modal Models (RSLMMs) are developing rapidly and showcase significant capabilities in remote sensing imagery (RSI) comprehension. However, due to the limitations of existing datasets, RSLMMs have shortcomings in understanding the rich semantic relations among objects in complex remote sensing scenes. To unlock RSLMMs' complex comprehension ability, we propose a large-scale instruction tuning dataset FIT-RS, containing 1,800,851 instruction samples. FIT-RS covers common interpretation tasks and innovatively introduces several complex comprehension tasks of escalating difficulty, ranging from relation reasoning to image-level scene graph generation. Based on FIT-RS, we build the FIT-RSFG benchmark. Furthermore, we establish a new benchmark to evaluate the fine-grained relation comprehension capabilities of LMMs, named FIT-RSRC. Based on combined instruction data, we propose SkySenseGPT, which achieves outstanding performance on both public datasets and FIT-RSFG, surpassing existing RSLMMs. We hope the FIT-RS dataset can enhance the relation comprehension capability of RSLMMs and provide a large-scale fine-grained data source for the remote sensing community. The dataset will be available at https://github.com/Luo-Z13/SkySenseGPT
Enhancing DETRs Variants through Improved Content Query and Similar Query Aggregation
May 06, 2024
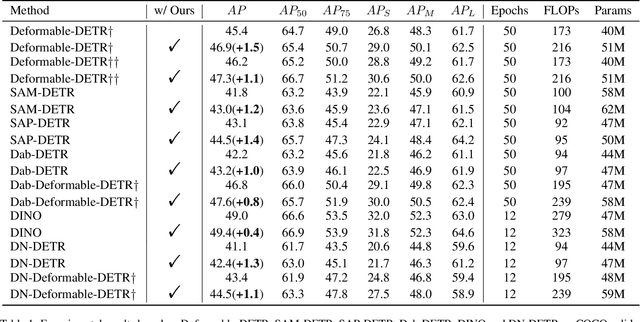
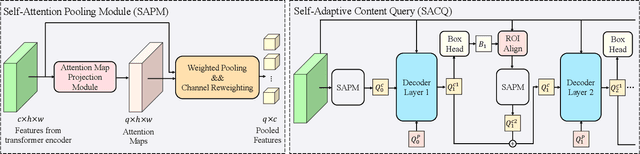
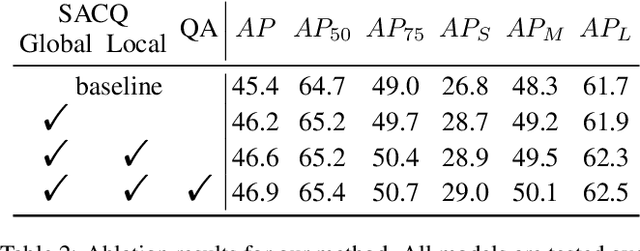
The design of the query is crucial for the performance of DETR and its variants. Each query consists of two components: a content part and a positional one. Traditionally, the content query is initialized with a zero or learnable embedding, lacking essential content information and resulting in sub-optimal performance. In this paper, we introduce a novel plug-and-play module, Self-Adaptive Content Query (SACQ), to address this limitation. The SACQ module utilizes features from the transformer encoder to generate content queries via self-attention pooling. This allows candidate queries to adapt to the input image, resulting in a more comprehensive content prior and better focus on target objects. However, this improved concentration poses a challenge for the training process that utilizes the Hungarian matching, which selects only a single candidate and suppresses other similar ones. To overcome this, we propose a query aggregation strategy to cooperate with SACQ. It merges similar predicted candidates from different queries, easing the optimization. Our extensive experiments on the COCO dataset demonstrate the effectiveness of our proposed approaches across six different DETR's variants with multiple configurations, achieving an average improvement of over 1.0 AP.
SkySense: A Multi-Modal Remote Sensing Foundation Model Towards Universal Interpretation for Earth Observation Imagery
Dec 15, 2023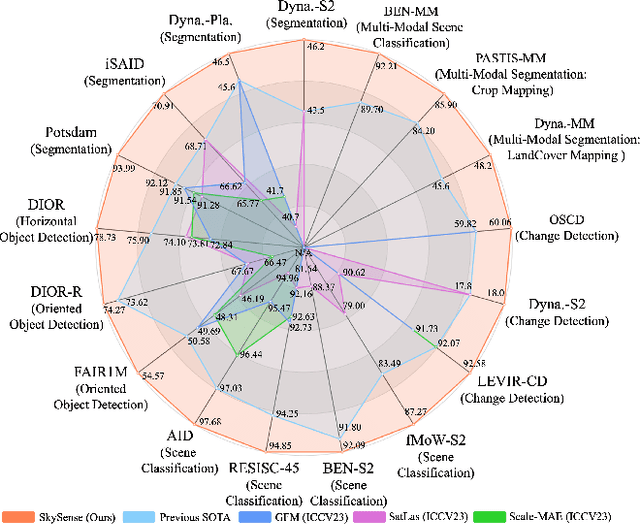
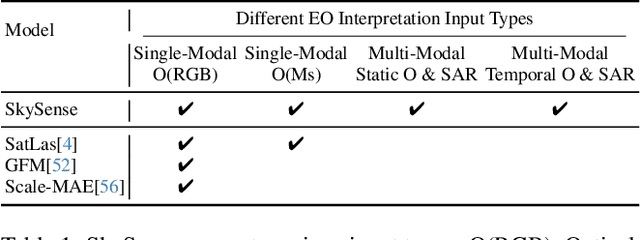
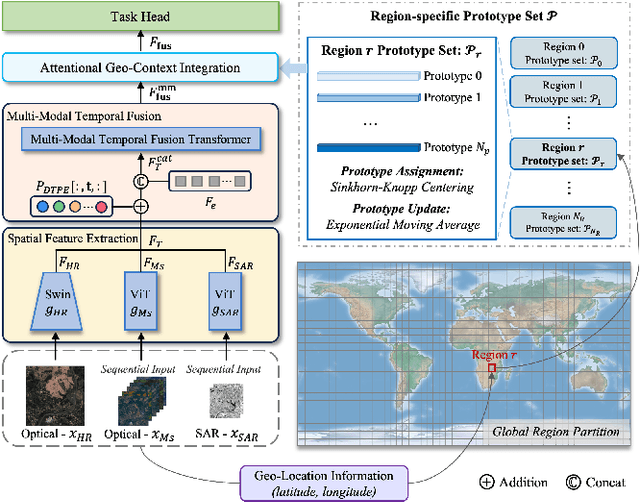
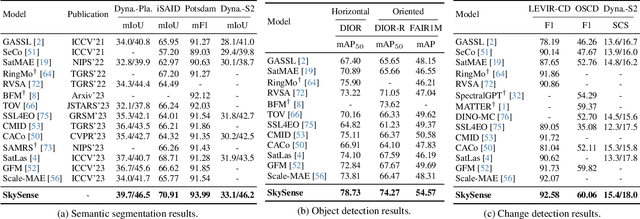
Prior studies on Remote Sensing Foundation Model (RSFM) reveal immense potential towards a generic model for Earth Observation. Nevertheless, these works primarily focus on a single modality without temporal and geo-context modeling, hampering their capabilities for diverse tasks. In this study, we present SkySense, a generic billion-scale model, pre-trained on a curated multi-modal Remote Sensing Imagery (RSI) dataset with 21.5 million temporal sequences. SkySense incorporates a factorized multi-modal spatiotemporal encoder taking temporal sequences of optical and Synthetic Aperture Radar (SAR) data as input. This encoder is pre-trained by our proposed Multi-Granularity Contrastive Learning to learn representations across different modal and spatial granularities. To further enhance the RSI representations by the geo-context clue, we introduce Geo-Context Prototype Learning to learn region-aware prototypes upon RSI's multi-modal spatiotemporal features. To our best knowledge, SkySense is the largest Multi-Modal RSFM to date, whose modules can be flexibly combined or used individually to accommodate various tasks. It demonstrates remarkable generalization capabilities on a thorough evaluation encompassing 16 datasets over 7 tasks, from single- to multi-modal, static to temporal, and classification to localization. SkySense surpasses 18 recent RSFMs in all test scenarios. Specifically, it outperforms the latest models such as GFM, SatLas and Scale-MAE by a large margin, i.e., 2.76%, 3.67% and 3.61% on average respectively. We will release the pre-trained weights to facilitate future research and Earth Observation applications.