 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasP: Improving Semi-Dense Feature Matching Pipeline Leveraging Cascaded Correspondence Priors for Guidance
Jul 23, 2025Semi-dense feature matching methods have shown strong performance in challenging scenarios. However, the existing pipeline relies on a global search across the entire feature map to establish coarse matches, limiting further improvements in accuracy and efficiency. Motivated by this limitation, we propose a novel pipeline, CasP, which leverages cascaded correspondence priors for guidance. Specifically, the matching stage is decomposed into two progressive phases, bridged by a region-based selective cross-attention mechanism designed to enhance feature discriminability. In the second phase, one-to-one matches are determined by restricting the search range to the one-to-many prior areas identified in the first phase. Additionally, this pipeline benefits from incorporating high-level features, which helps reduce the computational costs of low-level feature extraction. The acceleration gains of CasP increase with higher resolution, and our lite model achieves a speedup of $\sim2.2\times$ at a resolution of 1152 compared to the most efficient method, ELoFTR. Furthermore, extensive experiments demonstrate its superiority in geometric estimation, particularly with impressive cross-domain generalization. These advantages highlight its potential for latency-sensitive and high-robustness applications, such as SLAM and UAV systems. Code is available at https://github.com/pq-chen/CasP.
Cross-View Image Set Geo-Localization
Dec 25, 2024



Cross-view geo-localization (CVGL) has been widely applied in fields such as robotic navigation and augmented reality. Existing approaches primarily use single images or fixed-view image sequences as queries, which limits perspective diversity. In contrast, when humans determine their location visually, they typically move around to gather multiple perspectives. This behavior suggests that integrating diverse visual cues can improve geo-localization reliability. Therefore, we propose a novel task: Cross-View Image Set Geo-Localization (Set-CVGL), which gathers multiple images with diverse perspectives as a query set for localization. To support this task, we introduce SetVL-480K, a benchmark comprising 480,000 ground images captured worldwide and their corresponding satellite images, with each satellite image corresponds to an average of 40 ground images from varied perspectives and locations. Furthermore, we propose FlexGeo, a flexible method designed for Set-CVGL that can also adapt to single-image and image-sequence inputs. FlexGeo includes two key modules: the Similarity-guided Feature Fuser (SFF), which adaptively fuses image features without prior content dependency, and the Individual-level Attributes Learner (IAL), leveraging geo-attributes of each image for comprehensive scene perception. FlexGeo consistently outperforms existing methods on SetVL-480K and two public datasets, SeqGeo and KITTI-CVL, achieving a localization accuracy improvement of over 22% on SetVL-480K.
Cross-View Geo-Localization with Street-View and VHR Satellite Imagery in Decentrality Settings
Dec 16, 2024Cross-View Geo-Localization tackles the problem of image geo-localization in GNSS-denied environments by matching street-view query images with geo-tagged aerial-view reference images. However, existing datasets and methods often assume center-aligned settings or only consider limited decentrality (i.e., the offset of the query image from the reference image center). This assumption overlooks the challenges present in real-world applications, where large decentrality can significantly enhance localization efficiency but simultaneously lead to a substantial degradation in localization accuracy. To address this limitation, we introduce CVSat, a novel dataset designed to evaluate cross-view geo-localization with a large geographic scope and diverse landscapes, emphasizing the decentrality issue. Meanwhile, we propose AuxGeo (Auxiliary Enhanced Geo-Localization), which leverages a multi-metric optimization strategy with two novel modules: the Bird's-eye view Intermediary Module (BIM) and the Position Constraint Module (PCM). BIM uses bird's-eye view images derived from street-view panoramas as an intermediary, simplifying the cross-view challenge with decentrality to a cross-view problem and a decentrality problem. PCM leverages position priors between cross-view images to establish multi-grained alignment constraints. These modules improve the performance of cross-view geo-localization with the decentrality problem. Extensive experiments demonstrate that AuxGeo outperforms previous methods on our proposed CVSat dataset, mitigating the issue of large decentrality, and also achieves state-of-the-art performance on existing public datasets such as CVUSA, CVACT, and VIGOR.
HomoMatcher: Dense Feature Matching Results with Semi-Dense Efficiency by Homography Estimation
Nov 11, 2024
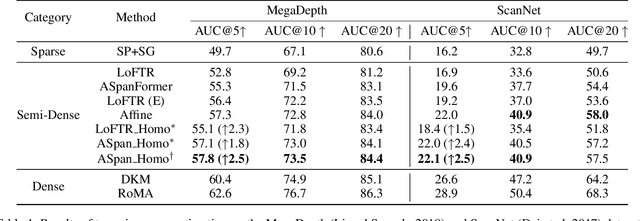
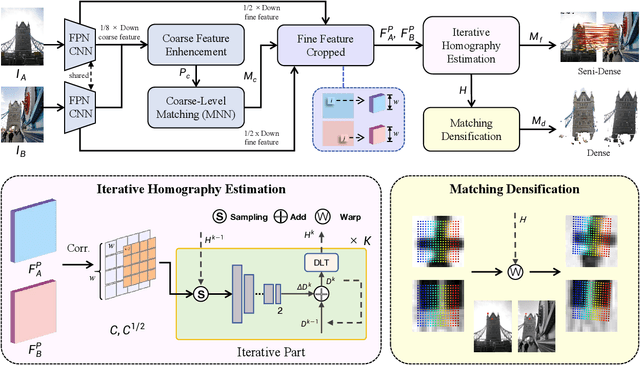
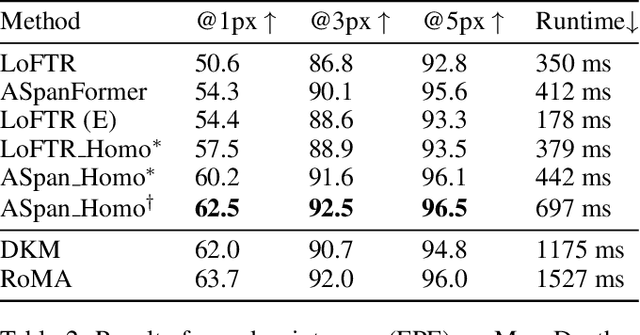
Feature matching between image pairs is a fundamental problem in computer vision that drives many applications, such as SLAM. Recently, semi-dense matching approaches have achieved substantial performance enhancements and established a widely-accepted coarse-to-fine paradigm. However, the majority of existing methods focus on improving coarse feature representation rather than the fine-matching module. Prior fine-matching techniques, which rely on point-to-patch matching probability expectation or direct regression, often lack precision and do not guarantee the continuity of feature points across sequential images. To address this limitation, this paper concentrates on enhancing the fine-matching module in the semi-dense matching framework. We employ a lightweight and efficient homography estimation network to generate the perspective mapping between patches obtained from coarse matching. This patch-to-patch approach achieves the overall alignment of two patches, resulting in a higher sub-pixel accuracy by incorporating additional constraints. By leveraging the homography estimation between patches, we can achieve a dense matching result with low computational cost. Extensive experiments demonstrate that our method achieves higher accuracy compared to previous semi-dense matchers. Meanwhile, our dense matching results exhibit similar end-point-error accuracy compared to previous dense matchers while maintaining semi-dense efficiency.
SkySense: A Multi-Modal Remote Sensing Foundation Model Towards Universal Interpretation for Earth Observation Imagery
Dec 15, 2023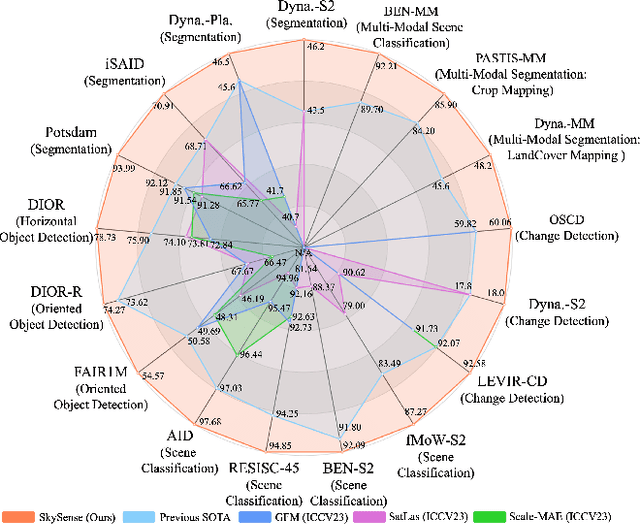
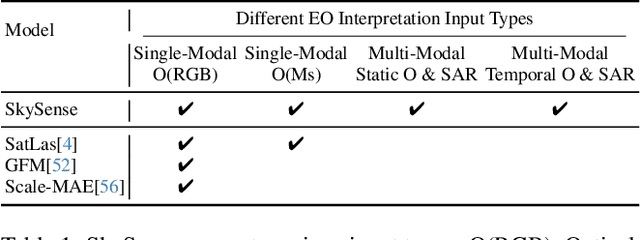
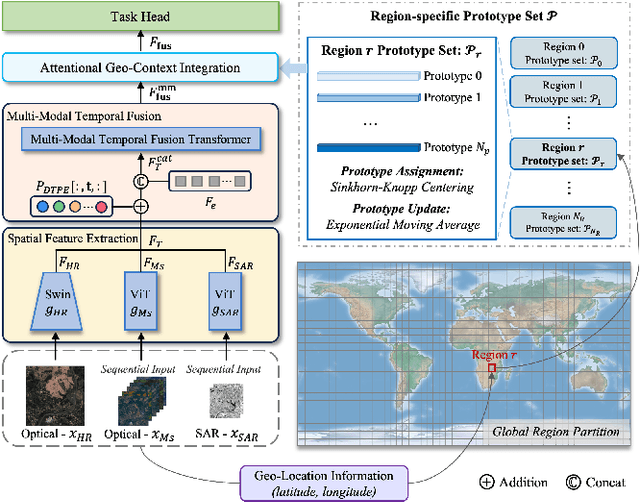
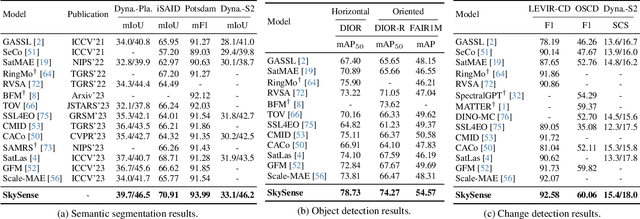
Prior studies on Remote Sensing Foundation Model (RSFM) reveal immense potential towards a generic model for Earth Observation. Nevertheless, these works primarily focus on a single modality without temporal and geo-context modeling, hampering their capabilities for diverse tasks. In this study, we present SkySense, a generic billion-scale model, pre-trained on a curated multi-modal Remote Sensing Imagery (RSI) dataset with 21.5 million temporal sequences. SkySense incorporates a factorized multi-modal spatiotemporal encoder taking temporal sequences of optical and Synthetic Aperture Radar (SAR) data as input. This encoder is pre-trained by our proposed Multi-Granularity Contrastive Learning to learn representations across different modal and spatial granularities. To further enhance the RSI representations by the geo-context clue, we introduce Geo-Context Prototype Learning to learn region-aware prototypes upon RSI's multi-modal spatiotemporal features. To our best knowledge, SkySense is the largest Multi-Modal RSFM to date, whose modules can be flexibly combined or used individually to accommodate various tasks. It demonstrates remarkable generalization capabilities on a thorough evaluation encompassing 16 datasets over 7 tasks, from single- to multi-modal, static to temporal, and classification to localization. SkySense surpasses 18 recent RSFMs in all test scenarios. Specifically, it outperforms the latest models such as GFM, SatLas and Scale-MAE by a large margin, i.e., 2.76%, 3.67% and 3.61% on average respectively. We will release the pre-trained weights to facilitate future research and Earth Observation applications.
Early- and in-season crop type mapping without current-year ground truth: generating labels from historical information via a topology-based approach
Oct 19, 2021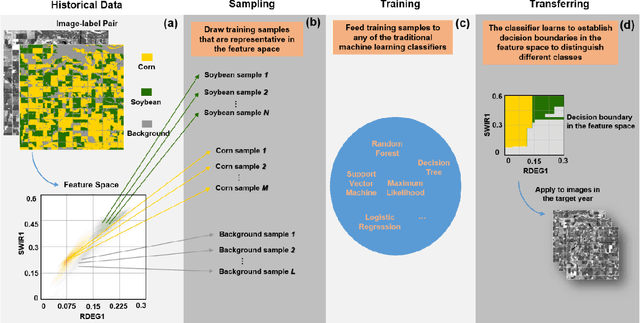

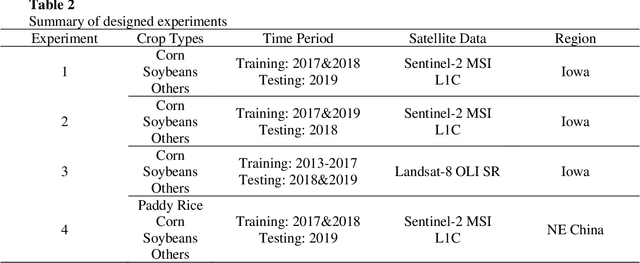
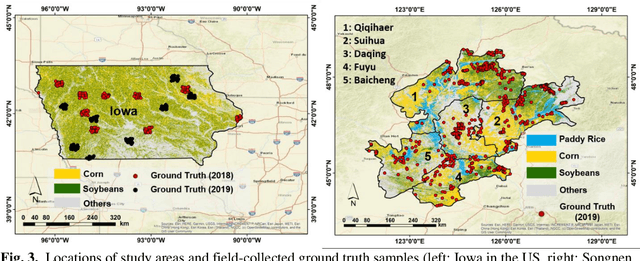
Land cover classification in remote sensing is often faced with the challenge of limited ground truth. Incorporating historical information has the potential to significantly lower the expensive cost associated with collecting ground truth and, more importantly, enable early- and in-season mapping that is helpful to many pre-harvest decisions. In this study, we propose a new approach that can effectively transfer knowledge about the topology (i.e. relative position) of different crop types in the spectral feature space (e.g. the histogram of SWIR1 vs RDEG1 bands) to generate labels, thereby support crop classification in a different year. Importantly, our approach does not attempt to transfer classification decision boundaries that are susceptible to inter-annual variations of weather and management, but relies on the more robust and shift-invariant topology information. We tested this approach for mapping corn/soybeans in the US Midwest and paddy rice/corn/soybeans in Northeast China using Landsat-8 and Sentinel-2 data. Results show that our approach automatically generates high-quality labels for crops in the target year immediately after each image becomes available. Based on these generated labels from our approach, the subsequent crop type mapping using a random forest classifier reach the F1 score as high as 0.887 for corn as early as the silking stage and 0.851 for soybean as early as the flowering stage and the overall accuracy of 0.873 in Iowa. In Northeast China, F1 scores of paddy rice, corn and soybeans and the overall accuracy can exceed 0.85 two and half months ahead of harvest. Overall, these results highlight unique advantages of our approach in transferring historical knowledge and maximizing the timeliness of crop maps. Our approach supports a general paradigm shift towards learning transferrable and generalizable knowledge to facilitate land cover classification.
Classification under Data Contamination with Application to Remote Sensing Image Mis-registration
Jan 05, 2012
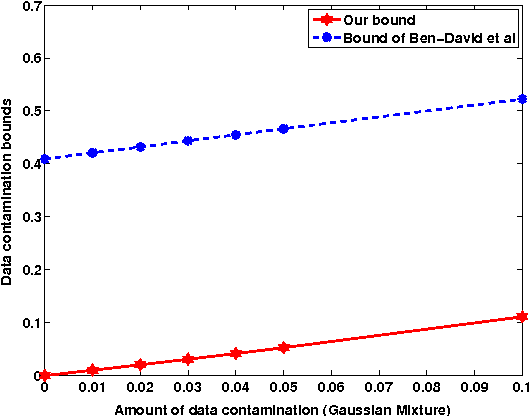
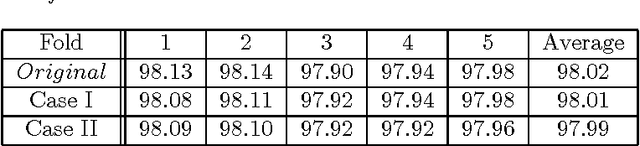
This work is motivated by the problem of image mis-registration in remote sensing and we are interested in determining the resulting loss in the accuracy of pattern classification. A statistical formulation is given where we propose to use data contamination to model and understand the phenomenon of image mis-registration. This model is widely applicable to many other types of errors as well, for example, measurement errors and gross errors etc. The impact of data contamination on classification is studied under a statistical learning theoretical framework. A closed-form asymptotic bound is established for the resulting loss in classification accuracy, which is less than $\epsilon/(1-\epsilon)$ for data contamination of an amount of $\epsilon$. Our bound is sharper than similar bounds in the domain adaptation literature and, unlike such bounds, it applies to classifiers with an infinite Vapnik-Chervonekis (VC) dimension. Extensive simulations have been conducted on both synthetic and real datasets under various types of data contamination, including label flipping, feature swapping and the replacement of feature values with data generated from a random source such as a Gaussian or Cauchy distribution. Our simulation results show that the bound we derive is fairly tight.