 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarvesting AlphaEarth: Benchmarking the Geospatial Foundation Model for Agricultural Downstream Tasks
Dec 30, 2025Geospatial foundation models (GFMs) have emerged as a promising approach to overcoming the limitations in existing featurization methods. More recently, Google DeepMind has introduced AlphaEarth Foundation (AEF), a GFM pre-trained using multi-source EOs across continuous time. An annual and global embedding dataset is produced using AEF that is ready for analysis and modeling. The internal experiments show that AEF embeddings have outperformed operational models in 15 EO tasks without re-training. However, those experiments are mostly about land cover and land use classification. Applying AEF and other GFMs to agricultural monitoring require an in-depth evaluation in critical agricultural downstream tasks. There is also a lack of comprehensive comparison between the AEF-based models and traditional remote sensing (RS)-based models under different scenarios, which could offer valuable guidance for researchers and practitioners. This study addresses some of these gaps by evaluating AEF embeddings in three agricultural downstream tasks in the U.S., including crop yield prediction, tillage mapping, and cover crop mapping. Datasets are compiled from both public and private sources to comprehensively evaluate AEF embeddings across tasks at different scales and locations, and RS-based models are trained as comparison models. AEF-based models generally exhibit strong performance on all tasks and are competitive with purpose-built RS-based models in yield prediction and county-level tillage mapping when trained on local data. However, we also find several limitations in current AEF embeddings, such as limited spatial transferability compared to RS-based models, low interpretability, and limited time sensitivity. These limitations recommend caution when applying AEF embeddings in agriculture, where time sensitivity, generalizability, and interpretability is important.
Scalable Vision-Guided Crop Yield Estimation
Nov 17, 2025Precise estimation and uncertainty quantification for average crop yields are critical for agricultural monitoring and decision making. Existing data collection methods, such as crop cuts in randomly sampled fields at harvest time, are relatively time-consuming. Thus, we propose an approach based on prediction-powered inference (PPI) to supplement these crop cuts with less time-consuming field photos. After training a computer vision model to predict the ground truth crop cut yields from the photos, we learn a ``control function" that recalibrates these predictions with the spatial coordinates of each field. This enables fields with photos but not crop cuts to be leveraged to improve the precision of zone-wide average yield estimates. Our control function is learned by training on a dataset of nearly 20,000 real crop cuts and photos of rice and maize fields in sub-Saharan Africa. To improve precision, we pool training observations across different zones within the same first-level subdivision of each country. Our final PPI-based point estimates of the average yield are provably asymptotically unbiased and cannot increase the asymptotic variance beyond that of the natural baseline estimator -- the sample average of the crop cuts -- as the number of fields grows. We also propose a novel bias-corrected and accelerated (BCa) bootstrap to construct accompanying confidence intervals. Even in zones with as few as 20 fields, the point estimates show significant empirical improvement over the baseline, increasing the effective sample size by as much as 73% for rice and by 12-23% for maize. The confidence intervals are accordingly shorter at minimal cost to empirical finite-sample coverage. This demonstrates the potential for relatively low-cost images to make area-based crop insurance more affordable and thus spur investment into sustainable agricultural practices.
ExPLoRA: Parameter-Efficient Extended Pre-Training to Adapt Vision Transformers under Domain Shifts
Jun 16, 2024Parameter-efficient fine-tuning (PEFT) techniques such as low-rank adaptation (LoRA) can effectively adapt large pre-trained foundation models to downstream tasks using only a small fraction (0.1%-10%) of the original trainable weights. An under-explored question of PEFT is in extending the pre-training phase without supervised labels; that is, can we adapt a pre-trained foundation model to a new domain via efficient self-supervised pre-training on this new domain? In this work, we introduce ExPLoRA, a highly effective technique to improve transfer learning of pre-trained vision transformers (ViTs) under domain shifts. Initializing a ViT with pre-trained weights on large, natural-image datasets such as from DinoV2 or MAE, ExPLoRA continues the unsupervised pre-training objective on a new domain. In this extended pre-training phase, ExPLoRA only unfreezes 1-2 pre-trained ViT blocks and all normalization layers, and then tunes all other layers with LoRA. Finally, we fine-tune the resulting model only with LoRA on this new domain for supervised learning. Our experiments demonstrate state-of-the-art results on satellite imagery, even outperforming fully pre-training and fine-tuning ViTs. Using the DinoV2 training objective, we demonstrate up to 7% improvement in linear probing top-1 accuracy on downstream tasks while using <10% of the number of parameters that are used in prior fully-tuned state-of-the art approaches. Our ablation studies confirm the efficacy of our approach over other baselines, including PEFT and simply unfreezing more transformer blocks.
Annual field-scale maps of tall and short crops at the global scale using GEDI and Sentinel-2
Dec 19, 2022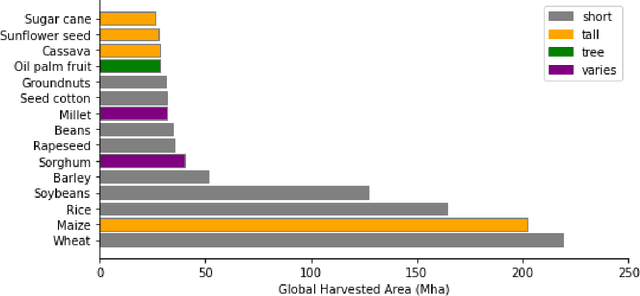
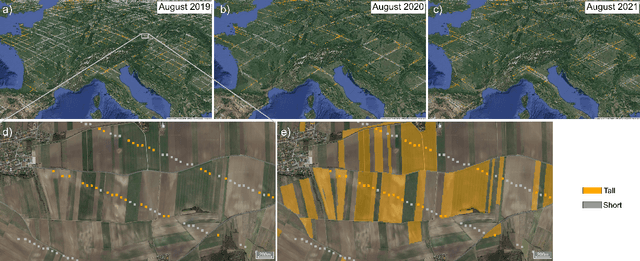
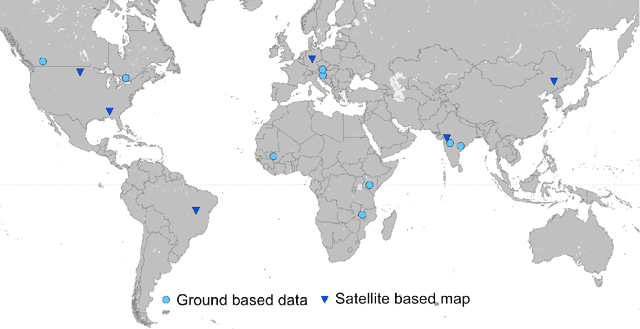
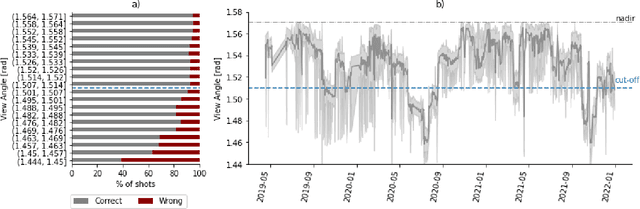
Crop type maps are critical for tracking agricultural land use and estimating crop production. Remote sensing has proven an efficient and reliable tool for creating these maps in regions with abundant ground labels for model training, yet these labels remain difficult to obtain in many regions and years. NASA's Global Ecosystem Dynamics Investigation (GEDI) spaceborne lidar instrument, originally designed for forest monitoring, has shown promise for distinguishing tall and short crops. In the current study, we leverage GEDI to develop wall-to-wall maps of short vs tall crops on a global scale at 10 m resolution for 2019-2021. Specifically, we show that (1) GEDI returns can reliably be classified into tall and short crops after removing shots with extreme view angles or topographic slope, (2) the frequency of tall crops over time can be used to identify months when tall crops are at their peak height, and (3) GEDI shots in these months can then be used to train random forest models that use Sentinel-2 time series to accurately predict short vs. tall crops. Independent reference data from around the world are then used to evaluate these GEDI-S2 maps. We find that GEDI-S2 performed nearly as well as models trained on thousands of local reference training points, with accuracies of at least 87% and often above 90% throughout the Americas, Europe, and East Asia. Systematic underestimation of tall crop area was observed in regions where crops frequently exhibit low biomass, namely Africa and South Asia, and further work is needed in these systems. Although the GEDI-S2 approach only differentiates tall from short crops, in many landscapes this distinction goes a long way toward mapping the main individual crop types. The combination of GEDI and Sentinel-2 thus presents a very promising path towards global crop mapping with minimal reliance on ground data.
SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery
Jul 17, 2022

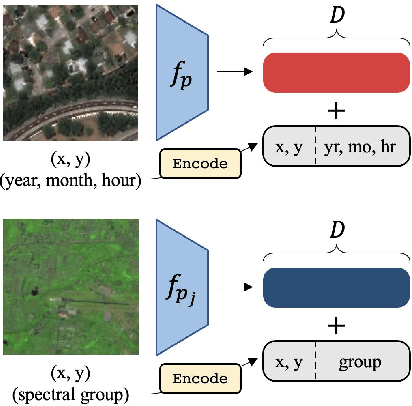
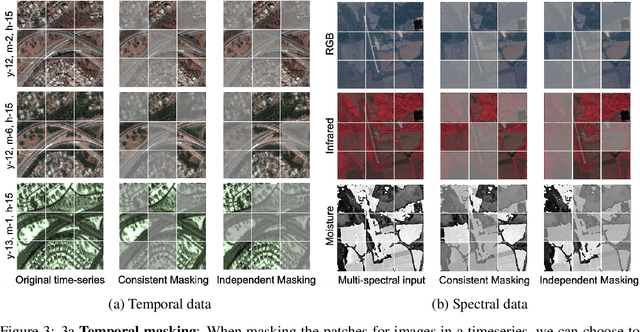
Unsupervised pre-training methods for large vision models have shown to enhance performance on downstream supervised tasks. Developing similar techniques for satellite imagery presents significant opportunities as unlabelled data is plentiful and the inherent temporal and multi-spectral structure provides avenues to further improve existing pre-training strategies. In this paper, we present SatMAE, a pre-training framework for temporal or multi-spectral satellite imagery based on Masked Autoencoder (MAE). To leverage temporal information, we include a temporal embedding along with independently masking image patches across time. In addition, we demonstrate that encoding multi-spectral data as groups of bands with distinct spectral positional encodings is beneficial. Our approach yields strong improvements over previous state-of-the-art techniques, both in terms of supervised learning performance on benchmark datasets (up to $\uparrow$ 7\%), and transfer learning performance on downstream remote sensing tasks, including land cover classification (up to $\uparrow$ 14\%) and semantic segmentation.
Tracking Urbanization in Developing Regions with Remote Sensing Spatial-Temporal Super-Resolution
Apr 04, 2022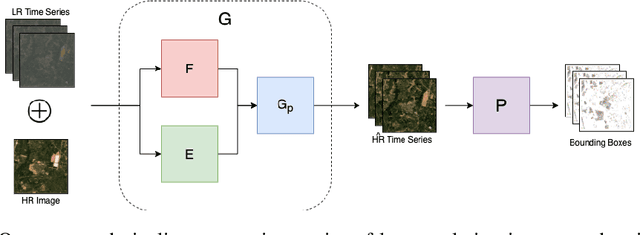
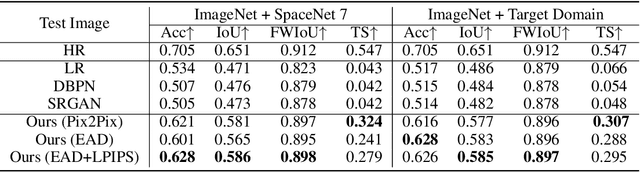

Automated tracking of urban development in areas where construction information is not available became possible with recent advancements in machine learning and remote sensing. Unfortunately, these solutions perform best on high-resolution imagery, which is expensive to acquire and infrequently available, making it difficult to scale over long time spans and across large geographies. In this work, we propose a pipeline that leverages a single high-resolution image and a time series of publicly available low-resolution images to generate accurate high-resolution time series for object tracking in urban construction. Our method achieves significant improvement in comparison to baselines using single image super-resolution, and can assist in extending the accessibility and scalability of building construction tracking across the developing world.
Unlocking large-scale crop field delineation in smallholder farming systems with transfer learning and weak supervision
Jan 13, 2022
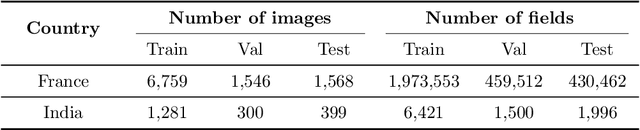


Crop field boundaries aid in mapping crop types, predicting yields, and delivering field-scale analytics to farmers. Recent years have seen the successful application of deep learning to delineating field boundaries in industrial agricultural systems, but field boundary datasets remain missing in smallholder systems due to (1) small fields that require high resolution satellite imagery to delineate and (2) a lack of ground labels for model training and validation. In this work, we combine transfer learning and weak supervision to overcome these challenges, and we demonstrate the methods' success in India where we efficiently generated 10,000 new field labels. Our best model uses 1.5m resolution Airbus SPOT imagery as input, pre-trains a state-of-the-art neural network on France field boundaries, and fine-tunes on India labels to achieve a median Intersection over Union (IoU) of 0.86 in India. If using 4.8m resolution PlanetScope imagery instead, the best model achieves a median IoU of 0.72. Experiments also show that pre-training in France reduces the number of India field labels needed to achieve a given performance level by as much as $20\times$ when datasets are small. These findings suggest our method is a scalable approach for delineating crop fields in regions of the world that currently lack field boundary datasets. We publicly release the 10,000 labels and delineation model to facilitate the creation of field boundary maps and new methods by the community.
SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning
Nov 08, 2021
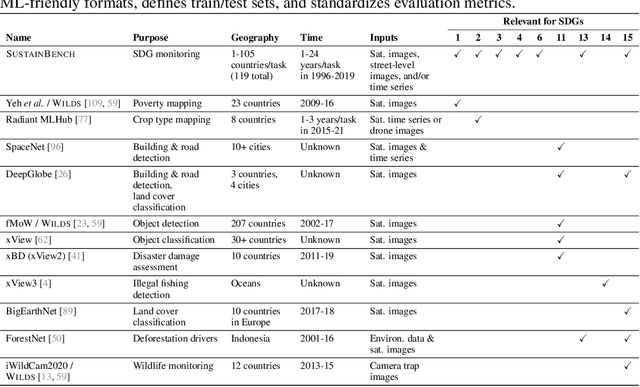
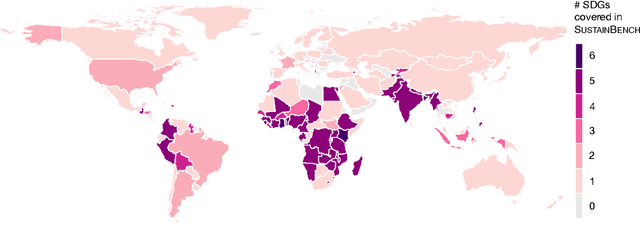
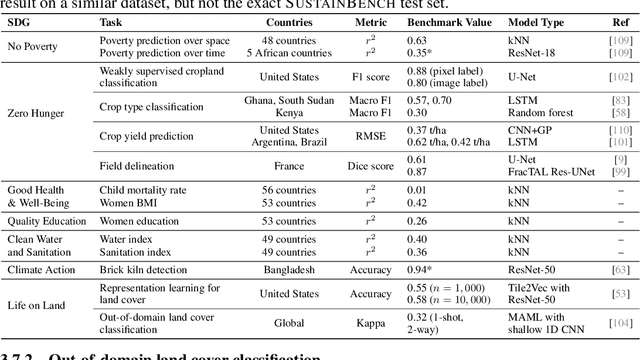
Progress toward the United Nations Sustainable Development Goals (SDGs) has been hindered by a lack of data on key environmental and socioeconomic indicators, which historically have come from ground surveys with sparse temporal and spatial coverage. Recent advances in machine learning have made it possible to utilize abundant, frequently-updated, and globally available data, such as from satellites or social media, to provide insights into progress toward SDGs. Despite promising early results, approaches to using such data for SDG measurement thus far have largely evaluated on different datasets or used inconsistent evaluation metrics, making it hard to understand whether performance is improving and where additional research would be most fruitful. Furthermore, processing satellite and ground survey data requires domain knowledge that many in the machine learning community lack. In this paper, we introduce SustainBench, a collection of 15 benchmark tasks across 7 SDGs, including tasks related to economic development, agriculture, health, education, water and sanitation, climate action, and life on land. Datasets for 11 of the 15 tasks are released publicly for the first time. Our goals for SustainBench are to (1) lower the barriers to entry for the machine learning community to contribute to measuring and achieving the SDGs; (2) provide standard benchmarks for evaluating machine learning models on tasks across a variety of SDGs; and (3) encourage the development of novel machine learning methods where improved model performance facilitates progress towards the SDGs.
Early- and in-season crop type mapping without current-year ground truth: generating labels from historical information via a topology-based approach
Oct 19, 2021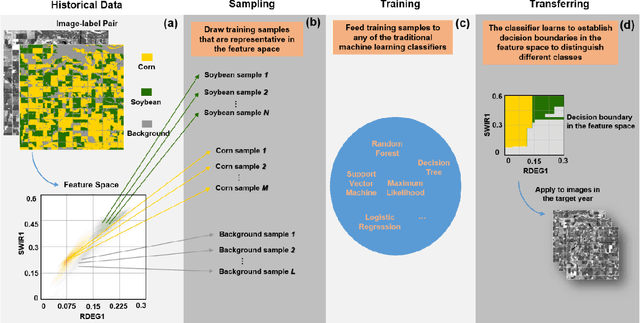

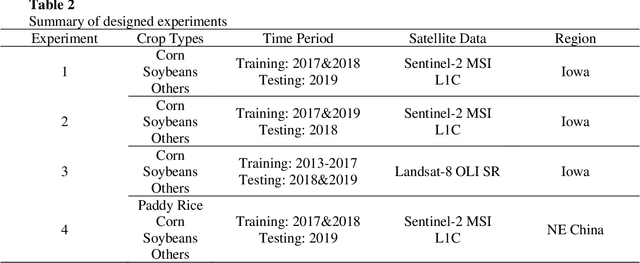
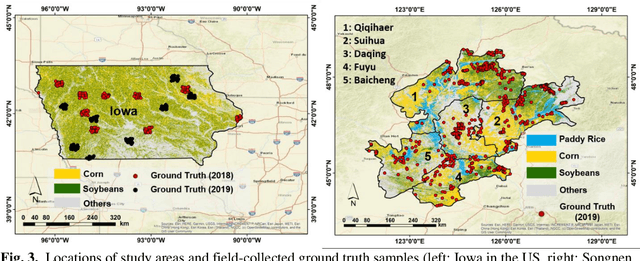
Land cover classification in remote sensing is often faced with the challenge of limited ground truth. Incorporating historical information has the potential to significantly lower the expensive cost associated with collecting ground truth and, more importantly, enable early- and in-season mapping that is helpful to many pre-harvest decisions. In this study, we propose a new approach that can effectively transfer knowledge about the topology (i.e. relative position) of different crop types in the spectral feature space (e.g. the histogram of SWIR1 vs RDEG1 bands) to generate labels, thereby support crop classification in a different year. Importantly, our approach does not attempt to transfer classification decision boundaries that are susceptible to inter-annual variations of weather and management, but relies on the more robust and shift-invariant topology information. We tested this approach for mapping corn/soybeans in the US Midwest and paddy rice/corn/soybeans in Northeast China using Landsat-8 and Sentinel-2 data. Results show that our approach automatically generates high-quality labels for crops in the target year immediately after each image becomes available. Based on these generated labels from our approach, the subsequent crop type mapping using a random forest classifier reach the F1 score as high as 0.887 for corn as early as the silking stage and 0.851 for soybean as early as the flowering stage and the overall accuracy of 0.873 in Iowa. In Northeast China, F1 scores of paddy rice, corn and soybeans and the overall accuracy can exceed 0.85 two and half months ahead of harvest. Overall, these results highlight unique advantages of our approach in transferring historical knowledge and maximizing the timeliness of crop maps. Our approach supports a general paradigm shift towards learning transferrable and generalizable knowledge to facilitate land cover classification.
Combining GEDI and Sentinel-2 for wall-to-wall mapping of tall and short crops
Sep 10, 2021



High resolution crop type maps are an important tool for improving food security, and remote sensing is increasingly used to create such maps in regions that possess ground truth labels for model training. However, these labels are absent in many regions, and models trained in other regions on typical satellite features, such as those from optical sensors, often exhibit low performance when transferred. Here we explore the use of NASA's Global Ecosystem Dynamics Investigation (GEDI) spaceborne lidar instrument, combined with Sentinel-2 optical data, for crop type mapping. Using data from three major cropped regions (in China, France, and the United States) we first demonstrate that GEDI energy profiles are capable of reliably distinguishing maize, a crop typically above 2m in height, from crops like rice and soybean that are shorter. We further show that these GEDI profiles provide much more invariant features across geographies compared to spectral and phenological features detected by passive optical sensors. GEDI is able to distinguish maize from other crops within each region with accuracies higher than 84%, and able to transfer across regions with accuracies higher than 82% compared to 64% for transfer of optical features. Finally, we show that GEDI profiles can be used to generate training labels for models based on optical imagery from Sentinel-2, thereby enabling the creation of 10m wall-to-wall maps of tall versus short crops in label-scarce regions. As maize is the second most widely grown crop in the world and often the only tall crop grown within a landscape, we conclude that GEDI offers great promise for improving global crop type maps.