 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurg$Σ$: A Spectrum of Large-Scale Multimodal Data and Foundation Models for Surgical Intelligence
Mar 17, 2026Surgical intelligence has the potential to improve the safety and consistency of surgical care, yet most existing surgical AI frameworks remain task-specific and struggle to generalize across procedures and institutions. Although multimodal foundation models, particularly multimodal large language models, have demonstrated strong cross-task capabilities across various medical domains, their advancement in surgery remains constrained by the lack of large-scale, systematically curated multimodal data. To address this challenge, we introduce Surg$Σ$, a spectrum of large-scale multimodal data and foundation models for surgical intelligence. At the core of this framework lies Surg$Σ$-DB, a large-scale multimodal data foundation designed to support diverse surgical tasks. Surg$Σ$-DB consolidates heterogeneous surgical data sources (including open-source datasets, curated in-house clinical collections and web-source data) into a unified schema, aiming to improve label consistency and data standardization across heterogeneous datasets. Surg$Σ$-DB spans 6 clinical specialties and diverse surgical types, providing rich image- and video-level annotations across 18 practical surgical tasks covering understanding, reasoning, planning, and generation, at an unprecedented scale (over 5.98M conversations). Beyond conventional multimodal conversations, Surg$Σ$-DB incorporates hierarchical reasoning annotations, providing richer semantic cues to support deeper contextual understanding in complex surgical scenarios. We further provide empirical evidence through recently developed surgical foundation models built upon Surg$Σ$-DB, illustrating the practical benefits of large-scale multimodal annotations, unified semantic design, and structured reasoning annotations for improving cross-task generalization and interpretability.
Surg-R1: A Hierarchical Reasoning Foundation Model for Scalable and Interpretable Surgical Decision Support with Multi-Center Clinical Validation
Mar 12, 2026Surgical scene understanding demands not only accurate predictions but also interpretable reasoning that surgeons can verify against clinical expertise. However, existing surgical vision-language models generate predictions without reasoning chains, and general-purpose reasoning models fail on compositional surgical tasks without domain-specific knowledge. We present Surg-R1, a surgical Vision-Language Model that addresses this gap through hierarchical reasoning trained via a four-stage pipeline. Our approach introduces three key contributions: (1) a three-level reasoning hierarchy decomposing surgical interpretation into perceptual grounding, relational understanding, and contextual reasoning; (2) the largest surgical chain-of-thought dataset with 320,000 reasoning pairs; and (3) a four-stage training pipeline progressing from supervised fine-tuning to group relative policy optimization and iterative self-improvement. Evaluation on SurgBench, comprising six public benchmarks and six multi-center external validation datasets from five institutions, demonstrates that Surg-R1 achieves the highest Arena Score (64.9%) on public benchmarks versus Gemini 3.0 Pro (46.1%) and GPT-5.1 (37.9%), outperforming both proprietary reasoning models and specialized surgical VLMs on the majority of tasks spanning instrument localization, triplet recognition, phase recognition, action recognition, and critical view of safety assessment, with a 15.2 percentage point improvement over the strongest surgical baseline on external validation.
AlignSurvey: A Comprehensive Benchmark for Human Preferences Alignment in Social Surveys
Nov 13, 2025Understanding human attitudes, preferences, and behaviors through social surveys is essential for academic research and policymaking. Yet traditional surveys face persistent challenges, including fixed-question formats, high costs, limited adaptability, and difficulties ensuring cross-cultural equivalence. While recent studies explore large language models (LLMs) to simulate survey responses, most are limited to structured questions, overlook the entire survey process, and risks under-representing marginalized groups due to training data biases. We introduce AlignSurvey, the first benchmark that systematically replicates and evaluates the full social survey pipeline using LLMs. It defines four tasks aligned with key survey stages: social role modeling, semi-structured interview modeling, attitude stance modeling and survey response modeling. It also provides task-specific evaluation metrics to assess alignment fidelity, consistency, and fairness at both individual and group levels, with a focus on demographic diversity. To support AlignSurvey, we construct a multi-tiered dataset architecture: (i) the Social Foundation Corpus, a cross-national resource with 44K+ interview dialogues and 400K+ structured survey records; and (ii) a suite of Entire-Pipeline Survey Datasets, including the expert-annotated AlignSurvey-Expert (ASE) and two nationally representative surveys for cross-cultural evaluation. We release the SurveyLM family, obtained through two-stage fine-tuning of open-source LLMs, and offer reference models for evaluating domain-specific alignment. All datasets, models, and tools are available at github and huggingface to support transparent and socially responsible research.
Tree-Based Hard Attention with Self-Motivation for Large Language Models
Feb 14, 2024



While large language models (LLMs) excel at understanding and generating plain text, they are not specifically tailored to handle hierarchical text structures. Extracting the task-desired property from their natural language responses typically necessitates additional processing steps. In fact, selectively comprehending the hierarchical structure of large-scale text is pivotal to understanding its substance. Aligning LLMs more closely with the classification or regression values of specific task through prompting also remains challenging. To this end, we propose a novel framework called Tree-Based Hard Attention with Self-Motivation for Large Language Models (TEAROOM). TEAROOM incorporates a tree-based hard attention mechanism for LLMs to process hierarchically structured text inputs. By leveraging prompting, it enables a frozen LLM to selectively focus on relevant leaves in relation to the root, generating a tailored symbolic representation of their relationship. Moreover, TEAROOM comprises a self-motivation strategy for another LLM equipped with a trainable adapter and a linear layer. The selected symbolic outcomes are integrated into another prompt, along with the predictive value of the task. We iteratively feed output values back into the prompt, enabling the trainable LLM to progressively approximate the golden truth. TEAROOM outperforms existing state-of-the-art methods in experimental evaluations across three benchmark datasets, showing its effectiveness in estimating task-specific properties. Through comprehensive experiments and analysis, we have validated the ability of TEAROOM to gradually approach the underlying golden truth through multiple inferences.
Mapping smallholder cashew plantations to inform sustainable tree crop expansion in Benin
Jan 01, 2023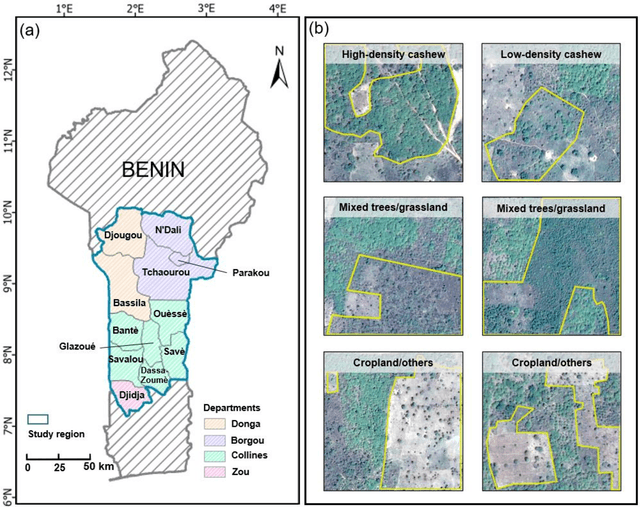

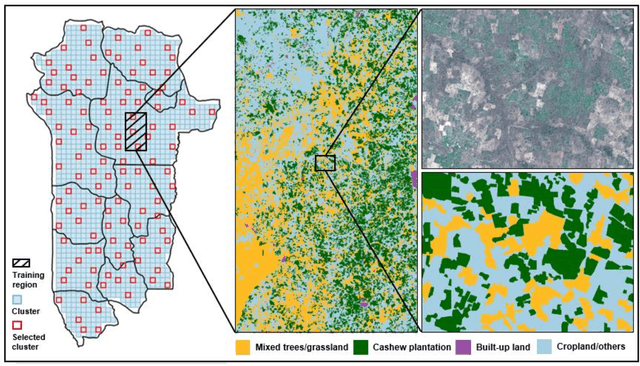
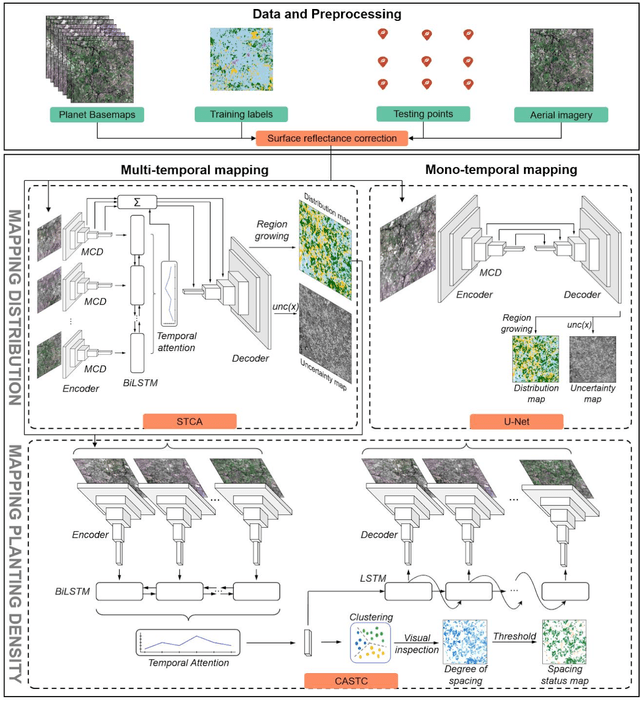
Cashews are grown by over 3 million smallholders in more than 40 countries worldwide as a principal source of income. As the third largest cashew producer in Africa, Benin has nearly 200,000 smallholder cashew growers contributing 15% of the country's national export earnings. However, a lack of information on where and how cashew trees grow across the country hinders decision-making that could support increased cashew production and poverty alleviation. By leveraging 2.4-m Planet Basemaps and 0.5-m aerial imagery, newly developed deep learning algorithms, and large-scale ground truth datasets, we successfully produced the first national map of cashew in Benin and characterized the expansion of cashew plantations between 2015 and 2021. In particular, we developed a SpatioTemporal Classification with Attention (STCA) model to map the distribution of cashew plantations, which can fully capture texture information from discriminative time steps during a growing season. We further developed a Clustering Augmented Self-supervised Temporal Classification (CASTC) model to distinguish high-density versus low-density cashew plantations by automatic feature extraction and optimized clustering. Results show that the STCA model has an overall accuracy of 80% and the CASTC model achieved an overall accuracy of 77.9%. We found that the cashew area in Benin has doubled from 2015 to 2021 with 60% of new plantation development coming from cropland or fallow land, while encroachment of cashew plantations into protected areas has increased by 70%. Only half of cashew plantations were high-density in 2021, suggesting high potential for intensification. Our study illustrates the power of combining high-resolution remote sensing imagery and state-of-the-art deep learning algorithms to better understand tree crops in the heterogeneous smallholder landscape.
Early- and in-season crop type mapping without current-year ground truth: generating labels from historical information via a topology-based approach
Oct 19, 2021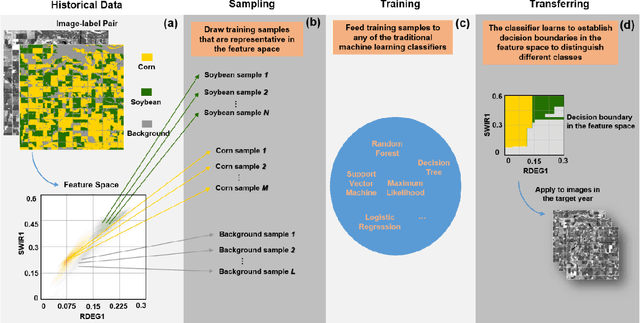

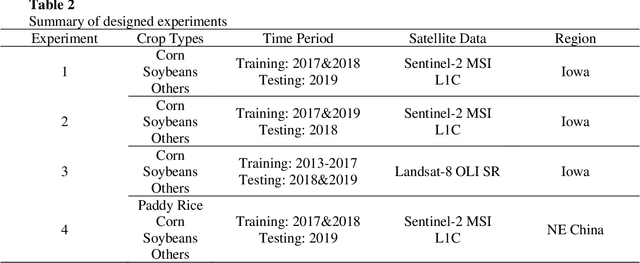
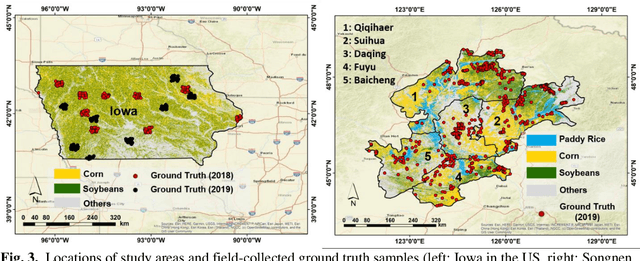
Land cover classification in remote sensing is often faced with the challenge of limited ground truth. Incorporating historical information has the potential to significantly lower the expensive cost associated with collecting ground truth and, more importantly, enable early- and in-season mapping that is helpful to many pre-harvest decisions. In this study, we propose a new approach that can effectively transfer knowledge about the topology (i.e. relative position) of different crop types in the spectral feature space (e.g. the histogram of SWIR1 vs RDEG1 bands) to generate labels, thereby support crop classification in a different year. Importantly, our approach does not attempt to transfer classification decision boundaries that are susceptible to inter-annual variations of weather and management, but relies on the more robust and shift-invariant topology information. We tested this approach for mapping corn/soybeans in the US Midwest and paddy rice/corn/soybeans in Northeast China using Landsat-8 and Sentinel-2 data. Results show that our approach automatically generates high-quality labels for crops in the target year immediately after each image becomes available. Based on these generated labels from our approach, the subsequent crop type mapping using a random forest classifier reach the F1 score as high as 0.887 for corn as early as the silking stage and 0.851 for soybean as early as the flowering stage and the overall accuracy of 0.873 in Iowa. In Northeast China, F1 scores of paddy rice, corn and soybeans and the overall accuracy can exceed 0.85 two and half months ahead of harvest. Overall, these results highlight unique advantages of our approach in transferring historical knowledge and maximizing the timeliness of crop maps. Our approach supports a general paradigm shift towards learning transferrable and generalizable knowledge to facilitate land cover classification.
Clustering augmented Self-Supervised Learning: Anapplication to Land Cover Mapping
Aug 16, 2021
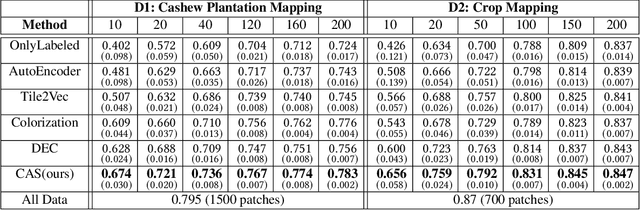
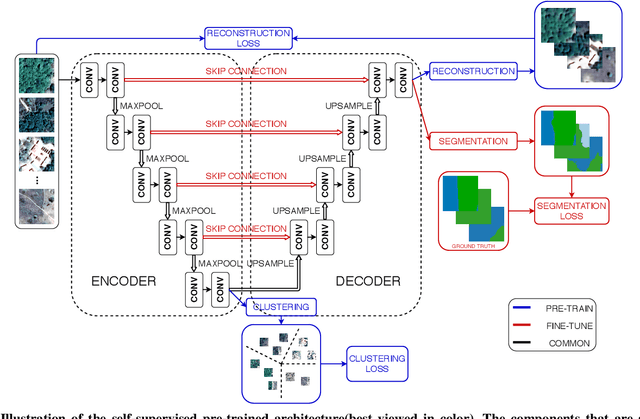

Collecting large annotated datasets in Remote Sensing is often expensive and thus can become a major obstacle for training advanced machine learning models. Common techniques of addressing this issue, based on the underlying idea of pre-training the Deep Neural Networks (DNN) on freely available large datasets, cannot be used for Remote Sensing due to the unavailability of such large-scale labeled datasets and the heterogeneity of data sources caused by the varying spatial and spectral resolution of different sensors. Self-supervised learning is an alternative approach that learns feature representation from unlabeled images without using any human annotations. In this paper, we introduce a new method for land cover mapping by using a clustering based pretext task for self-supervised learning. We demonstrate the effectiveness of the method on two societally relevant applications from the aspect of segmentation performance, discriminative feature representation learning and the underlying cluster structure. We also show the effectiveness of the active sampling using the clusters obtained from our method in improving the mapping accuracy given a limited budget of annotating.
Attention-augmented Spatio-Temporal Segmentation for Land Cover Mapping
May 02, 2021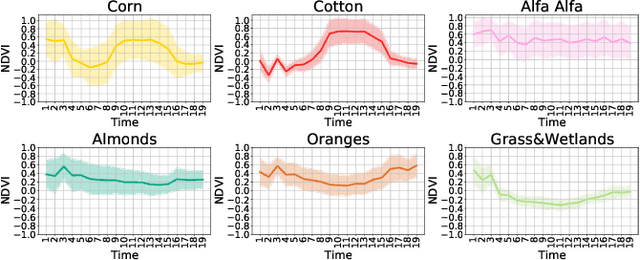
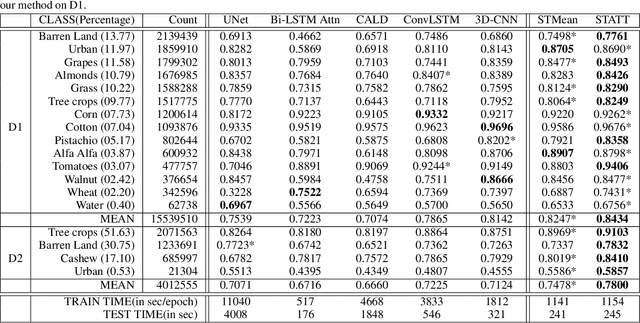
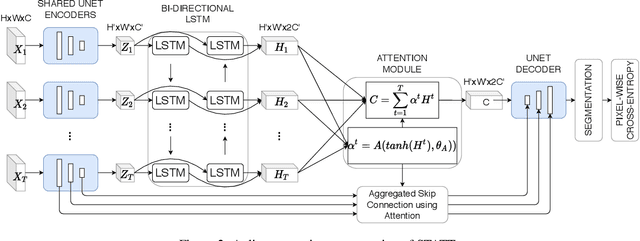
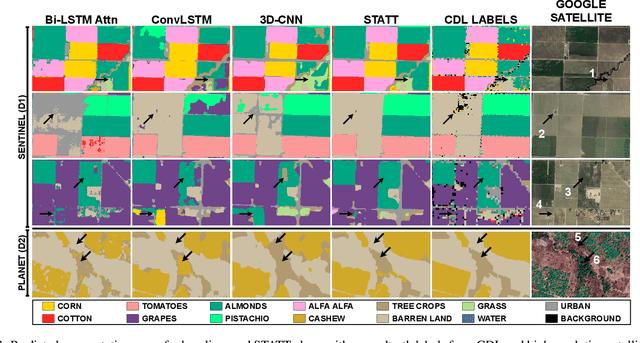
The availability of massive earth observing satellite data provide huge opportunities for land use and land cover mapping. However, such mapping effort is challenging due to the existence of various land cover classes, noisy data, and the lack of proper labels. Also, each land cover class typically has its own unique temporal pattern and can be identified only during certain periods. In this article, we introduce a novel architecture that incorporates the UNet structure with Bidirectional LSTM and Attention mechanism to jointly exploit the spatial and temporal nature of satellite data and to better identify the unique temporal patterns of each land cover. We evaluate this method for mapping crops in multiple regions over the world. We compare our method with other state-of-the-art methods both quantitatively and qualitatively on two real-world datasets which involve multiple land cover classes. We also visualise the attention weights to study its effectiveness in mitigating noise and identifying discriminative time period.
Carton dataset synthesis based on foreground texture replacement
Mar 25, 2021



One major impediment in rapidly deploying object detection models for industrial applications is the lack of large annotated datasets. We currently have presented the Sacked Carton Dataset(SCD) that contains carton images from three scenarios such as comprehensive pharmaceutical logistics company(CPLC), e-commerce logistics company(ECLC), fruit market(FM). However, due to domain shift, the model trained with carton datasets from one of the three scenarios in SCD has poor generalization ability when applied to the rest scenarios. To solve this problem, a novel image synthesis method is proposed to replace the foreground texture of the source datasets with the foreground instance texture of the target datasets. This method can greatly augment the target datasets and improve the model's performance. We firstly propose a surfaces segmentation algorithm to identify the different surfaces of the carton instance. Secondly, a contour reconstruction algorithm is proposed to solve the problem of occlusion, truncation, and incomplete contour of carton instances. Finally, the Gaussian fusion algorithm is used to fuse the background from the source datasets with the foreground from the target datasets. The novel image synthesis method can largely boost AP by at least $4.3\%\sim6.5\%$ on RetinaNet and $3.4\%\sim6.8\%$ on Faster R-CNN for the target domain. And on the source domain, the performance AP can be improved by $1.7\%\sim2\%$ on RetinaNet and $0.9\%\sim1.5\%$ on Faster R-CNN. Code is available at https://github.com/hustgetlijun/RCAN.
SCD: A Stacked Carton Dataset for Detection and Segmentation
Feb 25, 2021
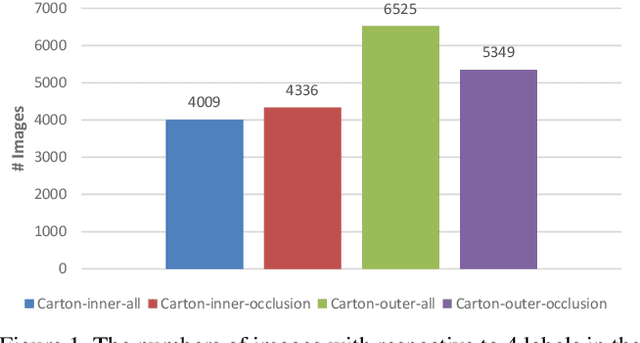
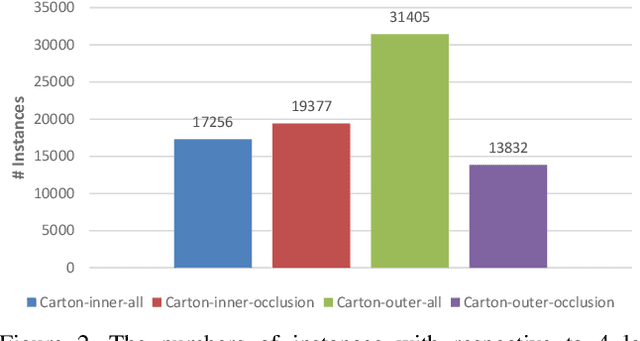
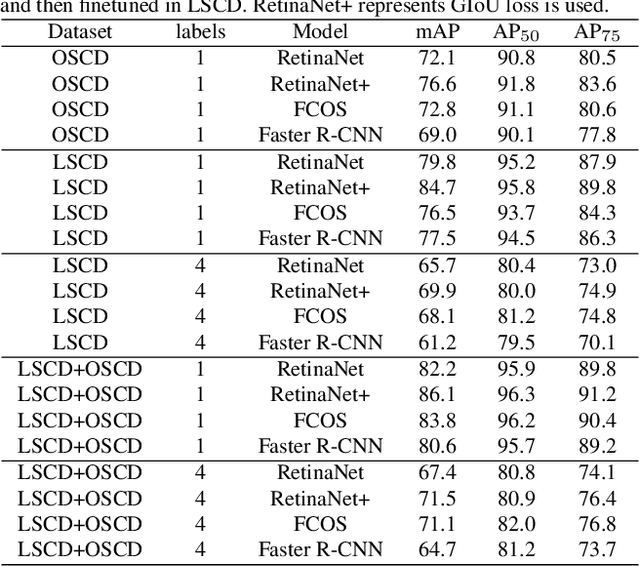
Carton detection is an important technique in the automatic logistics system and can be applied to many applications such as the stacking and unstacking of cartons, the unloading of cartons in the containers. However, there is no public large-scale carton dataset for the research community to train and evaluate the carton detection models up to now, which hinders the development of carton detection. In this paper, we present a large-scale carton dataset named Stacked Carton Dataset(SCD) with the goal of advancing the state-of-the-art in carton detection. Images are collected from the internet and several warehourses, and objects are labeled using per-instance segmentation for precise localization. There are totally 250,000 instance masks from 16,136 images. In addition, we design a carton detector based on RetinaNet by embedding Offset Prediction between Classification and Localization module(OPCL) and Boundary Guided Supervision module(BGS). OPCL alleviates the imbalance problem between classification and localization quality which boosts AP by 3.1% - 4.7% on SCD while BGS guides the detector to pay more attention to boundary information of cartons and decouple repeated carton textures. To demonstrate the generalization of OPCL to other datasets, we conduct extensive experiments on MS COCO and PASCAL VOC. The improvement of AP on MS COCO and PASCAL VOC is 1.8% - 2.2% and 3.4% - 4.3% respectively.