 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeachers Do More Than Teach: Compressing Image-to-Image Models
Mar 05, 2021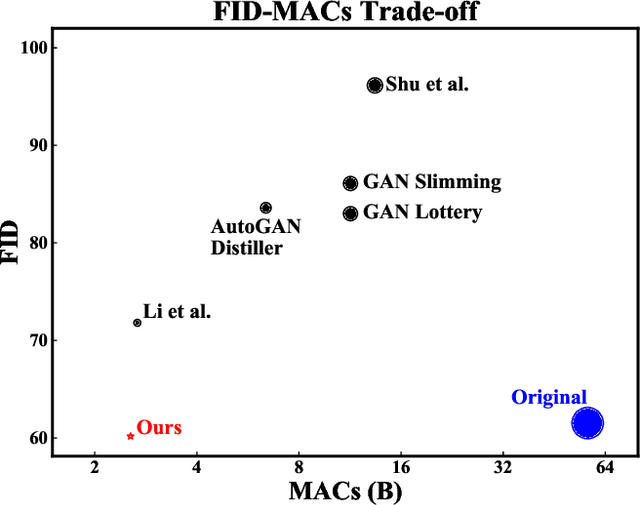
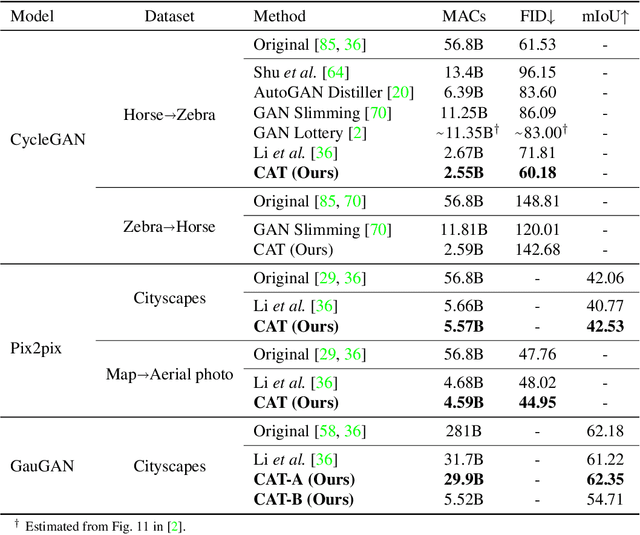
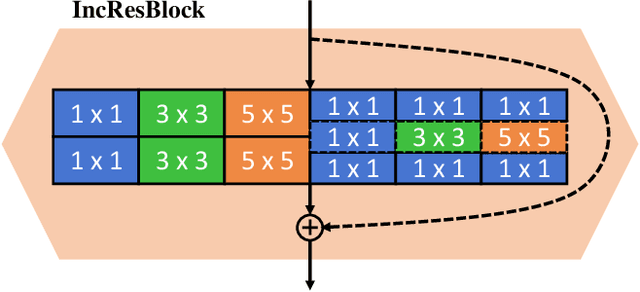
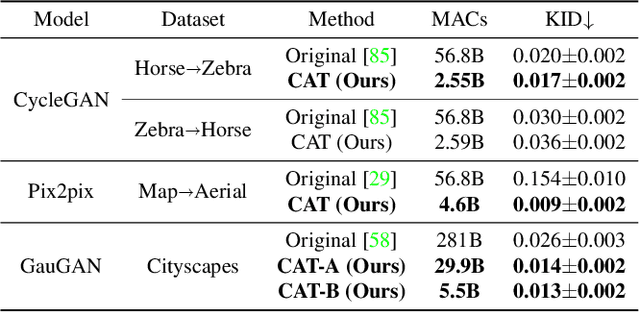
Generative Adversarial Networks (GANs) have achieved huge success in generating high-fidelity images, however, they suffer from low efficiency due to tremendous computational cost and bulky memory usage. Recent efforts on compression GANs show noticeable progress in obtaining smaller generators by sacrificing image quality or involving a time-consuming searching process. In this work, we aim to address these issues by introducing a teacher network that provides a search space in which efficient network architectures can be found, in addition to performing knowledge distillation. First, we revisit the search space of generative models, introducing an inception-based residual block into generators. Second, to achieve target computation cost, we propose a one-step pruning algorithm that searches a student architecture from the teacher model and substantially reduces searching cost. It requires no l1 sparsity regularization and its associated hyper-parameters, simplifying the training procedure. Finally, we propose to distill knowledge through maximizing feature similarity between teacher and student via an index named Global Kernel Alignment (GKA). Our compressed networks achieve similar or even better image fidelity (FID, mIoU) than the original models with much-reduced computational cost, e.g., MACs. Code will be released at https://github.com/snap-research/CAT.
SCD: A Stacked Carton Dataset for Detection and Segmentation
Feb 25, 2021
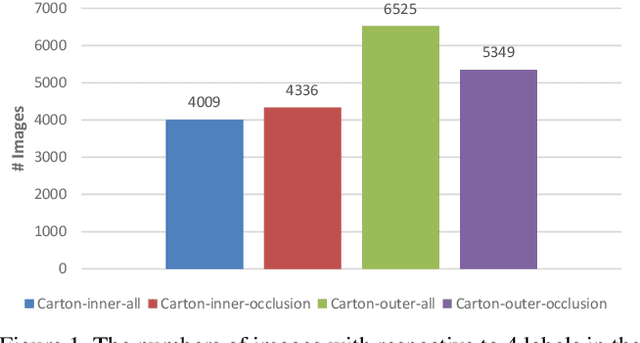
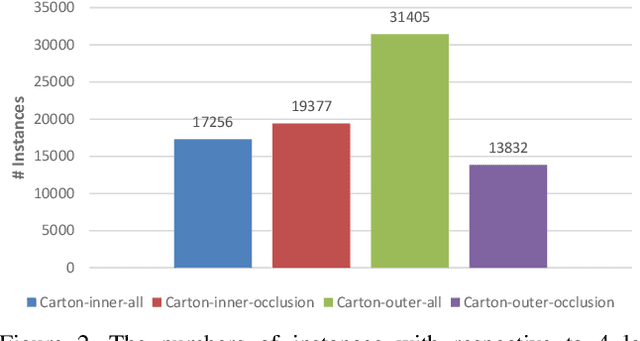
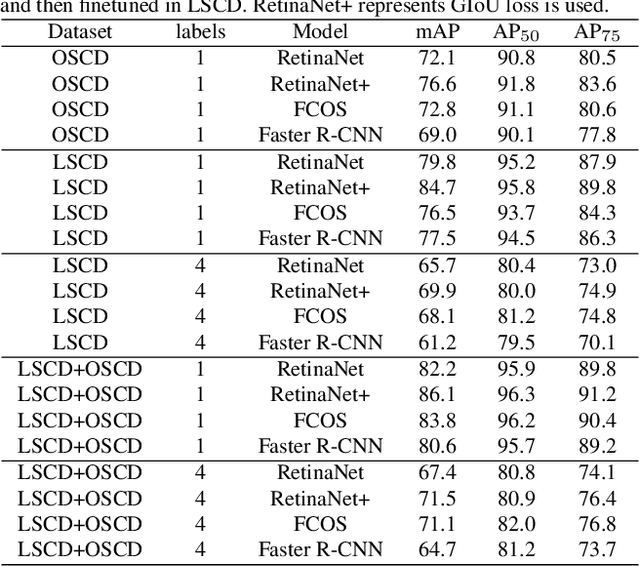
Carton detection is an important technique in the automatic logistics system and can be applied to many applications such as the stacking and unstacking of cartons, the unloading of cartons in the containers. However, there is no public large-scale carton dataset for the research community to train and evaluate the carton detection models up to now, which hinders the development of carton detection. In this paper, we present a large-scale carton dataset named Stacked Carton Dataset(SCD) with the goal of advancing the state-of-the-art in carton detection. Images are collected from the internet and several warehourses, and objects are labeled using per-instance segmentation for precise localization. There are totally 250,000 instance masks from 16,136 images. In addition, we design a carton detector based on RetinaNet by embedding Offset Prediction between Classification and Localization module(OPCL) and Boundary Guided Supervision module(BGS). OPCL alleviates the imbalance problem between classification and localization quality which boosts AP by 3.1% - 4.7% on SCD while BGS guides the detector to pay more attention to boundary information of cartons and decouple repeated carton textures. To demonstrate the generalization of OPCL to other datasets, we conduct extensive experiments on MS COCO and PASCAL VOC. The improvement of AP on MS COCO and PASCAL VOC is 1.8% - 2.2% and 3.4% - 4.3% respectively.
Combination of Hyperband and Bayesian Optimization for Hyperparameter Optimization in Deep Learning
Jan 05, 2018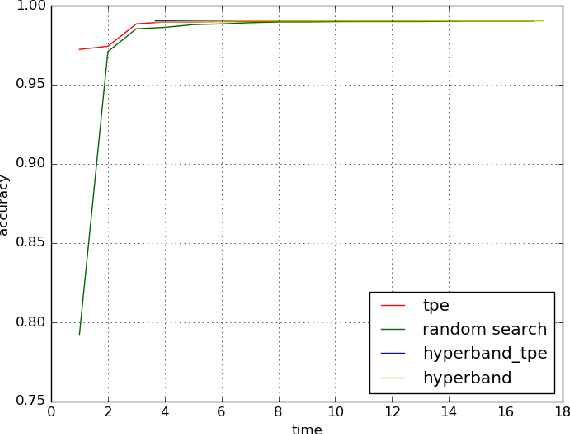
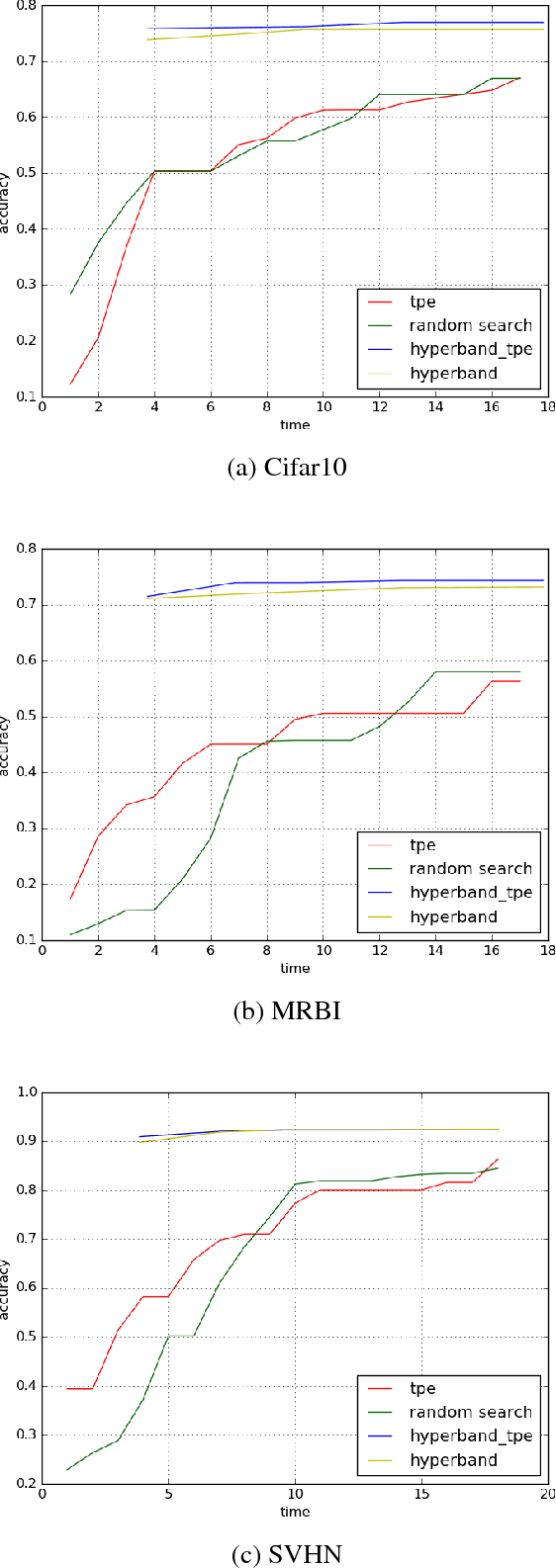
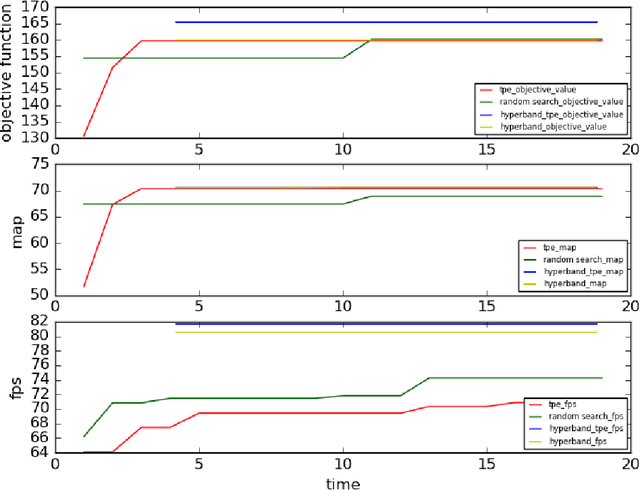
Deep learning has achieved impressive results on many problems. However, it requires high degree of expertise or a lot of experience to tune well the hyperparameters, and such manual tuning process is likely to be biased. Moreover, it is not practical to try out as many different hyperparameter configurations in deep learning as in other machine learning scenarios, because evaluating each single hyperparameter configuration in deep learning would mean training a deep neural network, which usually takes quite long time. Hyperband algorithm achieves state-of-the-art performance on various hyperparameter optimization problems in the field of deep learning. However, Hyperband algorithm does not utilize history information of previous explored hyperparameter configurations, thus the solution found is suboptimal. We propose to combine Hyperband algorithm with Bayesian optimization (which does not ignore history when sampling next trial configuration). Experimental results show that our combination approach is superior to other hyperparameter optimization approaches including Hyperband algorithm.