 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Free 3D Quantitative Phase Imaging of Flowing Cellular Populations
Sep 05, 2025High-throughput 3D quantitative phase imaging (QPI) in flow cytometry enables label-free, volumetric characterization of individual cells by reconstructing their refractive index (RI) distributions from multiple viewing angles during flow through microfluidic channels. However, current imaging methods assume that cells undergo uniform, single-axis rotation, which require their poses to be known at each frame. This assumption restricts applicability to near-spherical cells and prevents accurate imaging of irregularly shaped cells with complex rotations. As a result, only a subset of the cellular population can be analyzed, limiting the ability of flow-based assays to perform robust statistical analysis. We introduce OmniFHT, a pose-free 3D RI reconstruction framework that leverages the Fourier diffraction theorem and implicit neural representations (INRs) for high-throughput flow cytometry tomographic imaging. By jointly optimizing each cell's unknown rotational trajectory and volumetric structure under weak scattering assumptions, OmniFHT supports arbitrary cell geometries and multi-axis rotations. Its continuous representation also allows accurate reconstruction from sparsely sampled projections and restricted angular coverage, producing high-fidelity results with as few as 10 views or only 120 degrees of angular range. OmniFHT enables, for the first time, in situ, high-throughput tomographic imaging of entire flowing cell populations, providing a scalable and unbiased solution for label-free morphometric analysis in flow cytometry platforms.
Maximum Likelihood Estimation Based Complex-Valued Robust Chinese Remainder Theorem and Its Fast Algorithm
Mar 25, 2025Recently, a multi-channel self-reset analog-to-digital converter (ADC) system with complex-valued moduli has been proposed. This system enables the recovery of high dynamic range complex-valued bandlimited signals at low sampling rates via the Chinese remainder theorem (CRT). In this paper, we investigate complex-valued CRT (C-CRT) with erroneous remainders, where the errors follow wrapped complex Gaussian distributions. Based on the existing real-valued CRT utilizing maximum likelihood estimation (MLE), we propose a fast MLE-based C-CRT (MLE C-CRT). The proposed algorithm requires only $2L$ searches to obtain the optimal estimate of the common remainder, where $L$ is the number of moduli. Once the common remainder is estimated, the complex number can be determined using the C-CRT. Furthermore, we obtain a necessary and sufficient condition for the fast MLE C-CRT to achieve robust estimation. Finally, we apply the proposed algorithm to ADCs. The results demonstrate that the proposed algorithm outperforms the existing methods.
Maximum Likelihood CFO Estimation for High-Mobility OFDM Systems: A Chinese Remainder Theorem Based Method
Dec 27, 2023Orthogonal frequency division multiplexing (OFDM) is a widely adopted wireless communication technique but is sensitive to the carrier frequency offset (CFO). For high-mobility environments, severe Doppler shifts cause the CFO to extend well beyond the subcarrier spacing. Traditional algorithms generally estimate the integer and fractional parts of the CFO separately, which is time-consuming and requires high additional computations. To address these issues, this paper proposes a Chinese remainder theorem-based CFO Maximum Likelihood Estimation (CCMLE) approach for jointly estimating the integer and fractional parts. With CCMLE, the MLE of the CFO can be obtained directly from multiple estimates of sequences with varying lengths. This approach can achieve a wide estimation range up to the total number of subcarriers, without significant additional computations. Furthermore, we show that the CCMLE can approach the Cram$\acute{\text{e}}$r-Rao Bound (CRB), and give an analytic expression for the signal-to-noise ratio (SNR) threshold approaching the CRB, enabling an efficient waveform design. Accordingly, a parameter configuration guideline for the CCMLE is presented to achieve a better MSE performance and a lower SNR threshold. Finally, experiments show that our proposed method is highly consistent with the theoretical analysis and advantageous regarding estimated range and error performance compared to baselines.
Channel Capacity and Bounds In Mixed Gaussian-Impulsive Noise
Nov 15, 2023



Communication systems suffer from the mixed noise consisting of both non-Gaussian impulsive noise (IN) and white Gaussian noise (WGN) in many practical applications. However, there is little literature about the channel capacity under mixed noise. In this paper, we prove the existence of the capacity under p-th moment constraint and show that there are only finite mass points in the capacity-achieving distribution. Moreover, we provide lower and upper capacity bounds with closed forms. It is shown that the lower bounds can degenerate to the well-known Shannon formula under special scenarios. In addition, the capacity for specific modulations and the corresponding lower bounds are discussed. Numerical results reveal that the capacity decreases when the impulsiveness of the mixed noise becomes dominant and the obtained capacity bounds are shown to be very tight.
Towards 3D Object Detection with 2D Supervision
Nov 15, 2022The great progress of 3D object detectors relies on large-scale data and 3D annotations. The annotation cost for 3D bounding boxes is extremely expensive while the 2D ones are easier and cheaper to collect. In this paper, we introduce a hybrid training framework, enabling us to learn a visual 3D object detector with massive 2D (pseudo) labels, even without 3D annotations. To break through the information bottleneck of 2D clues, we explore a new perspective: Temporal 2D Supervision. We propose a temporal 2D transformation to bridge the 3D predictions with temporal 2D labels. Two steps, including homography wraping and 2D box deduction, are taken to transform the 3D predictions into 2D ones for supervision. Experiments conducted on the nuScenes dataset show strong results (nearly 90% of its fully-supervised performance) with only 25% 3D annotations. We hope our findings can provide new insights for using a large number of 2D annotations for 3D perception.
Quality Matters: Embracing Quality Clues for Robust 3D Multi-Object Tracking
Aug 23, 2022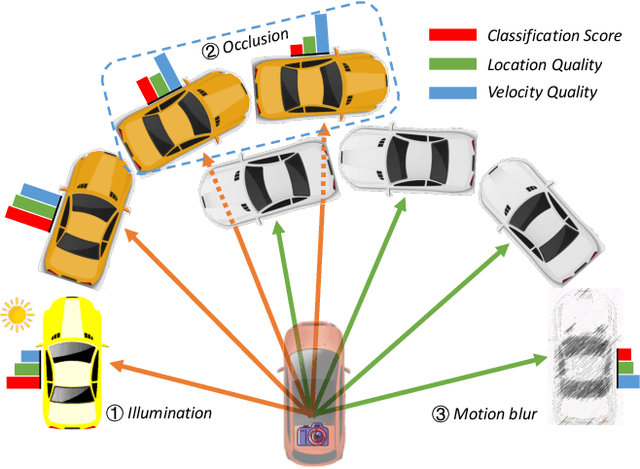
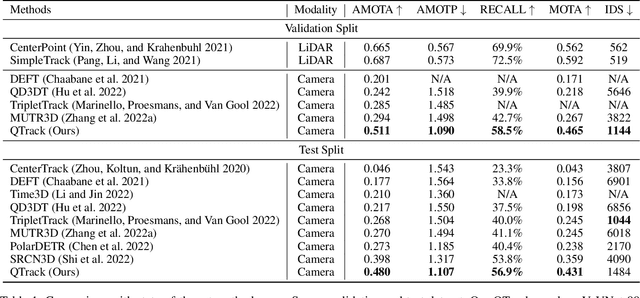
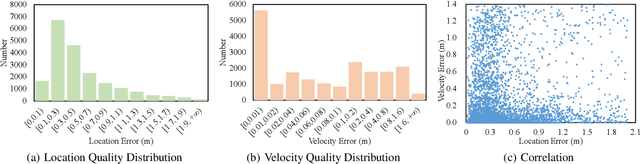

3D Multi-Object Tracking (MOT) has achieved tremendous achievement thanks to the rapid development of 3D object detection and 2D MOT. Recent advanced works generally employ a series of object attributes, e.g., position, size, velocity, and appearance, to provide the clues for the association in 3D MOT. However, these cues may not be reliable due to some visual noise, such as occlusion and blur, leading to tracking performance bottleneck. To reveal the dilemma, we conduct extensive empirical analysis to expose the key bottleneck of each clue and how they correlate with each other. The analysis results motivate us to efficiently absorb the merits among all cues, and adaptively produce an optimal tacking manner. Specifically, we present Location and Velocity Quality Learning, which efficiently guides the network to estimate the quality of predicted object attributes. Based on these quality estimations, we propose a quality-aware object association (QOA) strategy to leverage the quality score as an important reference factor for achieving robust association. Despite its simplicity, extensive experiments indicate that the proposed strategy significantly boosts tracking performance by 2.2% AMOTA and our method outperforms all existing state-of-the-art works on nuScenes by a large margin. Moreover, QTrack achieves 48.0% and 51.1% AMOTA tracking performance on the nuScenes validation and test sets, which significantly reduces the performance gap between pure camera and LiDAR based trackers.
DBQ-SSD: Dynamic Ball Query for Efficient 3D Object Detection
Jul 22, 2022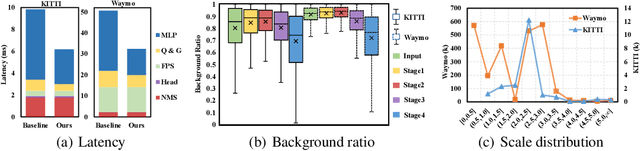
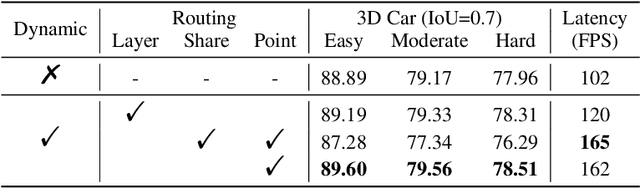
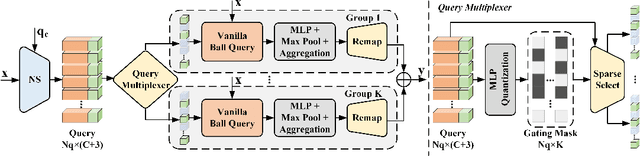
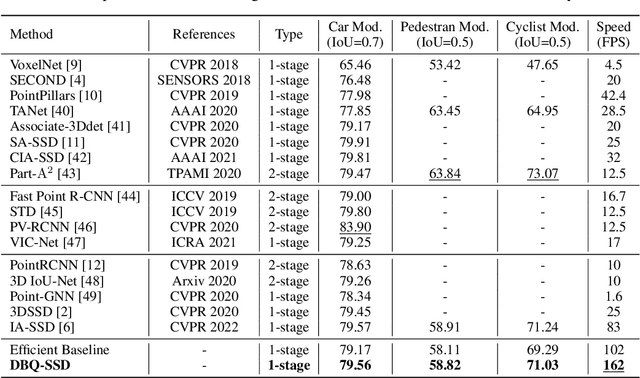
Many point-based 3D detectors adopt point-feature sampling strategies to drop some points for efficient inference. These strategies are typically based on fixed and handcrafted rules, making difficult to handle complicated scenes. Different from them, we propose a Dynamic Ball Query (DBQ) network to adaptively select a subset of input points according to the input features, and assign the feature transform with suitable receptive field for each selected point. It can be embedded into some state-of-the-art 3D detectors and trained in an end-to-end manner, which significantly reduces the computational cost. Extensive experiments demonstrate that our method can reduce latency by 30%-60% on KITTI and Waymo datasets. Specifically, the inference speed of our detector can reach 162 FPS and 30 FPS with negligible performance degradation on KITTI and Waymo datasets, respectively.
StreamYOLO: Real-time Object Detection for Streaming Perception
Jul 21, 2022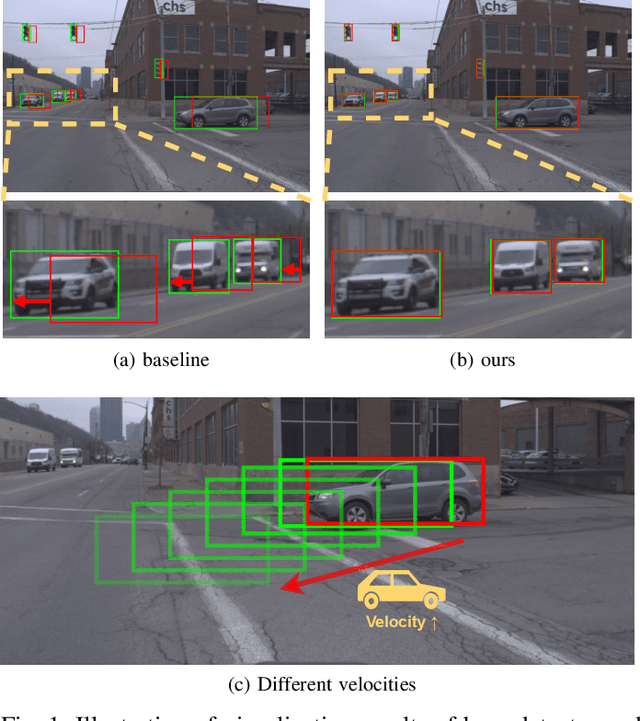
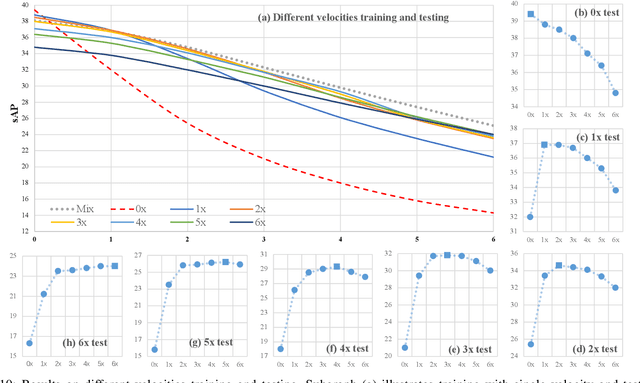
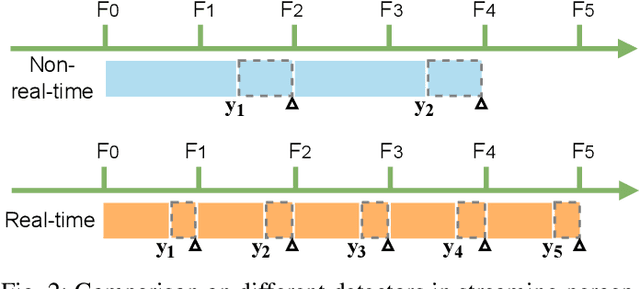
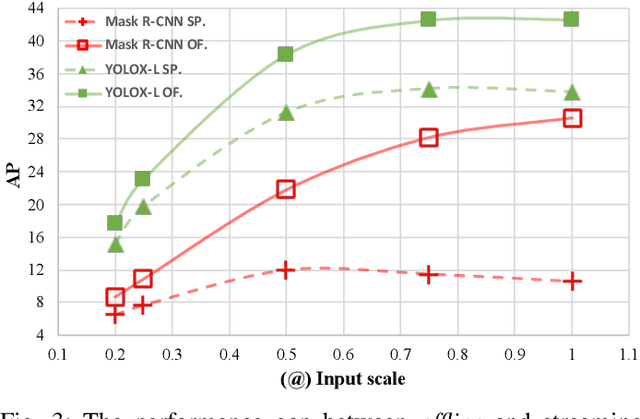
The perceptive models of autonomous driving require fast inference within a low latency for safety. While existing works ignore the inevitable environmental changes after processing, streaming perception jointly evaluates the latency and accuracy into a single metric for video online perception, guiding the previous works to search trade-offs between accuracy and speed. In this paper, we explore the performance of real time models on this metric and endow the models with the capacity of predicting the future, significantly improving the results for streaming perception. Specifically, we build a simple framework with two effective modules. One is a Dual Flow Perception module (DFP). It consists of dynamic flow and static flow in parallel to capture moving tendency and basic detection feature, respectively. Trend Aware Loss (TAL) is the other module which adaptively generates loss weight for each object with its moving speed. Realistically, we consider multiple velocities driving scene and further propose Velocity-awared streaming AP (VsAP) to jointly evaluate the accuracy. In this realistic setting, we design a efficient mix-velocity training strategy to guide detector perceive any velocities. Our simple method achieves the state-of-the-art performance on Argoverse-HD dataset and improves the sAP and VsAP by 4.7% and 8.2% respectively compared to the strong baseline, validating its effectiveness.
A Semantic Consistency Feature Alignment Object Detection Model Based on Mixed-Class Distribution Metrics
Jun 12, 2022
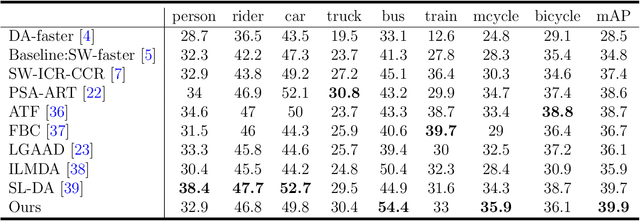
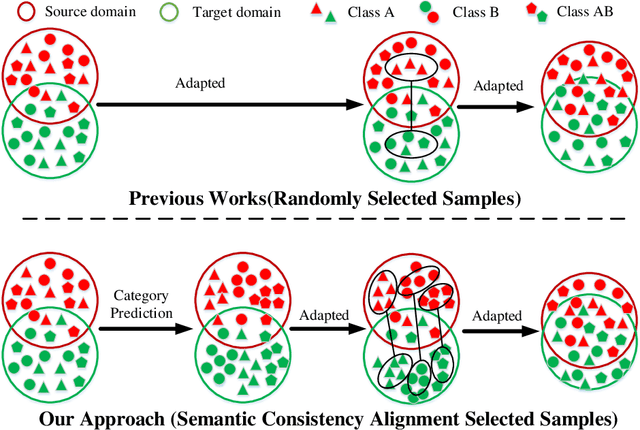
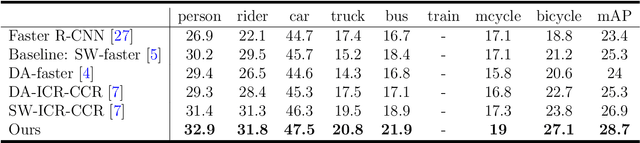
Unsupervised domain adaptation is critical in various computer vision tasks, such as object detection, instance segmentation, etc. They attempt to reduce domain bias-induced performance degradation while also promoting model application speed. Previous works in domain adaptation object detection attempt to align image-level and instance-level shifts to eventually minimize the domain discrepancy, but they may align single-class features to mixed-class features in image-level domain adaptation because each image in the object detection task may be more than one class and object. In order to achieve single-class with single-class alignment and mixed-class with mixed-class alignment, we treat the mixed-class of the feature as a new class and propose a mixed-classes $H-divergence$ for object detection to achieve homogenous feature alignment and reduce negative transfer. Then, a Semantic Consistency Feature Alignment Model (SCFAM) based on mixed-classes $H-divergence$ was also presented. To improve single-class and mixed-class semantic information and accomplish semantic separation, the SCFAM model proposes Semantic Prediction Models (SPM) and Semantic Bridging Components (SBC). And the weight of the pix domain discriminator loss is then changed based on the SPM result to reduce sample imbalance. Extensive unsupervised domain adaption experiments on widely used datasets illustrate our proposed approach's robust object detection in domain bias settings.
Real-time Object Detection for Streaming Perception
Mar 29, 2022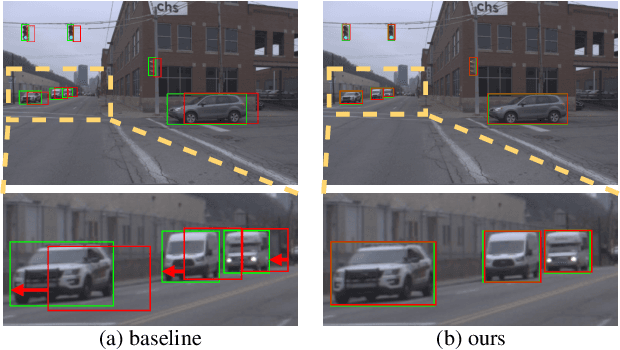

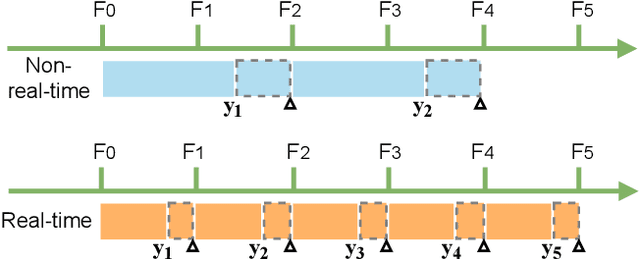
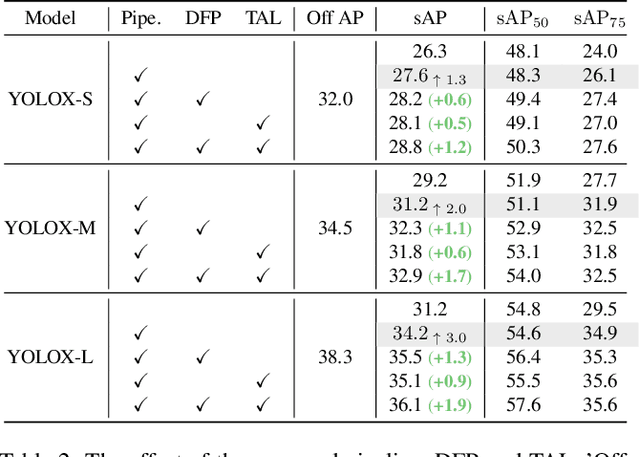
Autonomous driving requires the model to perceive the environment and (re)act within a low latency for safety. While past works ignore the inevitable changes in the environment after processing, streaming perception is proposed to jointly evaluate the latency and accuracy into a single metric for video online perception. In this paper, instead of searching trade-offs between accuracy and speed like previous works, we point out that endowing real-time models with the ability to predict the future is the key to dealing with this problem. We build a simple and effective framework for streaming perception. It equips a novel DualFlow Perception module (DFP), which includes dynamic and static flows to capture the moving trend and basic detection feature for streaming prediction. Further, we introduce a Trend-Aware Loss (TAL) combined with a trend factor to generate adaptive weights for objects with different moving speeds. Our simple method achieves competitive performance on Argoverse-HD dataset and improves the AP by 4.9% compared to the strong baseline, validating its effectiveness. Our code will be made available at https://github.com/yancie-yjr/StreamYOLO.