 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Chaos: Efficient Autoscaling and Self-healing for Distributed Training at the Edge
May 19, 2025Frequent node and link changes in edge AI clusters disrupt distributed training, while traditional checkpoint-based recovery and cloud-centric autoscaling are too slow for scale-out and ill-suited to chaotic and self-governed edge. This paper proposes Chaos, a resilient and scalable edge distributed training system with built-in self-healing and autoscaling. It speeds up scale-out by using multi-neighbor replication with fast shard scheduling, allowing a new node to pull the latest training state from nearby neighbors in parallel while balancing the traffic load between them. It also uses a cluster monitor to track resource and topology changes to assist scheduler decisions, and handles scaling events through peer negotiation protocols, enabling fully self-governed autoscaling without a central admin. Extensive experiments show that Chaos consistently achieves much lower scale-out delays than Pollux, EDL, and Autoscaling, and handles scale-in, connect-link, and disconnect-link events within 1 millisecond, making it smoother to handle node joins, exits, and failures. It also delivers the lowest idle time, showing superior resource use and scalability as the cluster grows.
TPI-LLM: Serving 70B-scale LLMs Efficiently on Low-resource Edge Devices
Oct 01, 2024



Large model inference is shifting from cloud to edge due to concerns about the privacy of user interaction data. However, edge devices often struggle with limited computing power, memory, and bandwidth, requiring collaboration across multiple devices to run and speed up LLM inference. Pipeline parallelism, the mainstream solution, is inefficient for single-user scenarios, while tensor parallelism struggles with frequent communications. In this paper, we argue that tensor parallelism can be more effective than pipeline on low-resource devices, and present a compute- and memory-efficient tensor parallel inference system, named TPI-LLM, to serve 70B-scale models. TPI-LLM keeps sensitive raw data local in the users' devices and introduces a sliding window memory scheduler to dynamically manage layer weights during inference, with disk I/O latency overlapped with the computation and communication. This allows larger models to run smoothly on memory-limited devices. We analyze the communication bottleneck and find that link latency, not bandwidth, emerges as the main issue, so a star-based allreduce algorithm is implemented. Through extensive experiments on both emulated and real testbeds, TPI-LLM demonstrated over 80% less time-to-first-token and token latency compared to Accelerate, and over 90% compared to Transformers and Galaxy, while cutting the peak memory footprint of Llama 2-70B by 90%, requiring only 3.1 GB of memory for 70B-scale models.
AMSNet: Netlist Dataset for AMS Circuits
May 15, 2024



Today's analog/mixed-signal (AMS) integrated circuit (IC) designs demand substantial manual intervention. The advent of multimodal large language models (MLLMs) has unveiled significant potential across various fields, suggesting their applicability in streamlining large-scale AMS IC design as well. A bottleneck in employing MLLMs for automatic AMS circuit generation is the absence of a comprehensive dataset delineating the schematic-netlist relationship. We therefore design an automatic technique for converting schematics into netlists, and create dataset AMSNet, encompassing transistor-level schematics and corresponding SPICE format netlists. With a growing size, AMSNet can significantly facilitate exploration of MLLM applications in AMS circuit design. We have made an initial set of netlists public, and will make both our netlist generation tool and the full dataset available upon publishing of this paper.
Beyond Deep Reinforcement Learning: A Tutorial on Generative Diffusion Models in Network Optimization
Aug 10, 2023Generative Diffusion Models (GDMs) have emerged as a transformative force in the realm of Generative Artificial Intelligence (GAI), demonstrating their versatility and efficacy across a variety of applications. The ability to model complex data distributions and generate high-quality samples has made GDMs particularly effective in tasks such as image generation and reinforcement learning. Furthermore, their iterative nature, which involves a series of noise addition and denoising steps, is a powerful and unique approach to learning and generating data. This paper serves as a comprehensive tutorial on applying GDMs in network optimization tasks. We delve into the strengths of GDMs, emphasizing their wide applicability across various domains, such as vision, text, and audio generation.We detail how GDMs can be effectively harnessed to solve complex optimization problems inherent in networks. The paper first provides a basic background of GDMs and their applications in network optimization. This is followed by a series of case studies, showcasing the integration of GDMs with Deep Reinforcement Learning (DRL), incentive mechanism design, Semantic Communications (SemCom), Internet of Vehicles (IoV) networks, etc. These case studies underscore the practicality and efficacy of GDMs in real-world scenarios, offering insights into network design. We conclude with a discussion on potential future directions for GDM research and applications, providing major insights into how they can continue to shape the future of network optimization.
Effective Intrusion Detection in Highly Imbalanced IoT Networks with Lightweight S2CGAN-IDS
Jun 06, 2023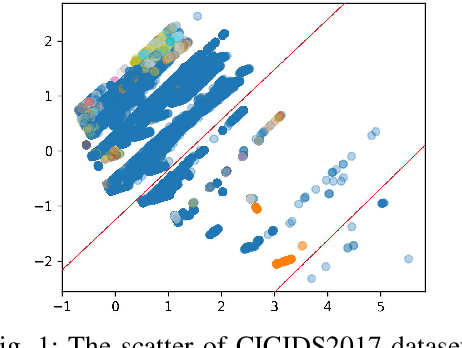
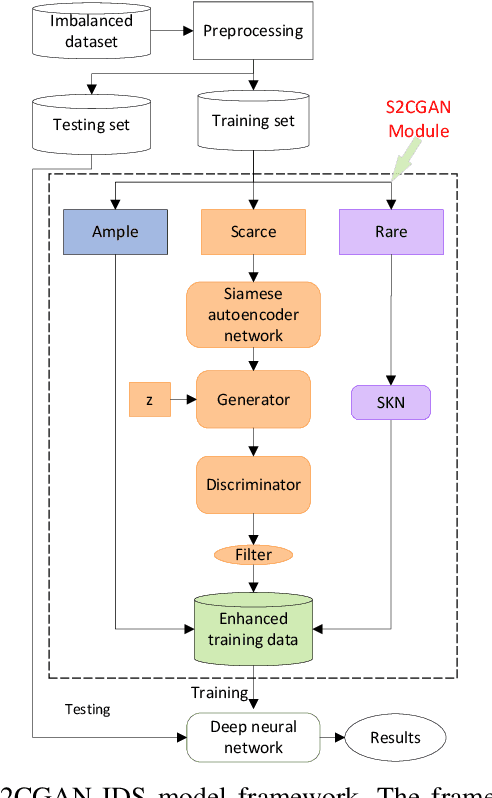
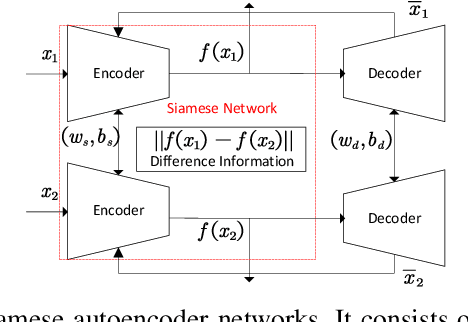
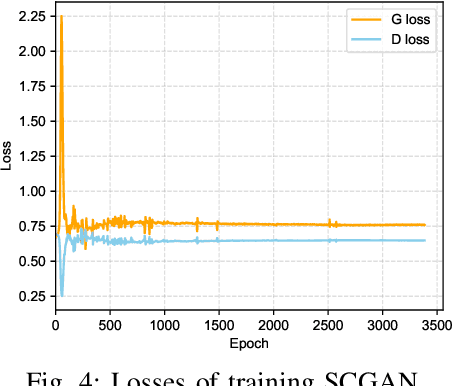
Since the advent of the Internet of Things (IoT), exchanging vast amounts of information has increased the number of security threats in networks. As a result, intrusion detection based on deep learning (DL) has been developed to achieve high throughput and high precision. Unlike general deep learning-based scenarios, IoT networks contain benign traffic far more than abnormal traffic, with some rare attacks. However, most existing studies have been focused on sacrificing the detection rate of the majority class in order to improve the detection rate of the minority class in class-imbalanced IoT networks. Although this way can reduce the false negative rate of minority classes, it both wastes resources and reduces the credibility of the intrusion detection systems. To address this issue, we propose a lightweight framework named S2CGAN-IDS. The proposed framework leverages the distribution characteristics of network traffic to expand the number of minority categories in both data space and feature space, resulting in a substantial increase in the detection rate of minority categories while simultaneously ensuring the detection precision of majority categories. To reduce the impact of sparsity on the experiments, the CICIDS2017 numeric dataset is utilized to demonstrate the effectiveness of the proposed method. The experimental results indicate that our proposed approach outperforms the superior method in both Precision and Recall, particularly with a 10.2% improvement in the F1-score.
Enabling AI-Generated Content (AIGC) Services in Wireless Edge Networks
Jan 09, 2023



Artificial Intelligence-Generated Content (AIGC) refers to the use of AI to automate the information creation process while fulfilling the personalized requirements of users. However, due to the instability of AIGC models, e.g., the stochastic nature of diffusion models, the quality and accuracy of the generated content can vary significantly. In wireless edge networks, the transmission of incorrectly generated content may unnecessarily consume network resources. Thus, a dynamic AIGC service provider (ASP) selection scheme is required to enable users to connect to the most suited ASP, improving the users' satisfaction and quality of generated content. In this article, we first review the AIGC techniques and their applications in wireless networks. We then present the AIGC-as-a-service (AaaS) concept and discuss the challenges in deploying AaaS at the edge networks. Yet, it is essential to have performance metrics to evaluate the accuracy of AIGC services. Thus, we introduce several image-based perceived quality evaluation metrics. Then, we propose a general and effective model to illustrate the relationship between computational resources and user-perceived quality evaluation metrics. To achieve efficient AaaS and maximize the quality of generated content in wireless edge networks, we propose a deep reinforcement learning-enabled algorithm for optimal ASP selection. Simulation results show that the proposed algorithm can provide a higher quality of generated content to users and achieve fewer crashed tasks by comparing with four benchmarks, i.e., overloading-avoidance, random, round-robin policies, and the upper-bound schemes.
HFedMS: Heterogeneous Federated Learning with Memorable Data Semantics in Industrial Metaverse
Nov 07, 2022



Federated Learning (FL), as a rapidly evolving privacy-preserving collaborative machine learning paradigm, is a promising approach to enable edge intelligence in the emerging Industrial Metaverse. Even though many successful use cases have proved the feasibility of FL in theory, in the industrial practice of Metaverse, the problems of non-independent and identically distributed (non-i.i.d.) data, learning forgetting caused by streaming industrial data, and scarce communication bandwidth remain key barriers to realize practical FL. Facing the above three challenges simultaneously, this paper presents a high-performance and efficient system named HFEDMS for incorporating practical FL into Industrial Metaverse. HFEDMS reduces data heterogeneity through dynamic grouping and training mode conversion (Dynamic Sequential-to-Parallel Training, STP). Then, it compensates for the forgotten knowledge by fusing compressed historical data semantics and calibrates classifier parameters (Semantic Compression and Compensation, SCC). Finally, the network parameters of the feature extractor and classifier are synchronized in different frequencies (Layer-wiseAlternative Synchronization Protocol, LASP) to reduce communication costs. These techniques make FL more adaptable to the heterogeneous streaming data continuously generated by industrial equipment, and are also more efficient in communication than traditional methods (e.g., Federated Averaging). Extensive experiments have been conducted on the streamed non-i.i.d. FEMNIST dataset using 368 simulated devices. Numerical results show that HFEDMS improves the classification accuracy by at least 6.4% compared with 8 benchmarks and saves both the overall runtime and transfer bytes by up to 98%, proving its superiority in precision and efficiency.
Personalized Saliency in Task-Oriented Semantic Communications: Image Transmission and Performance Analysis
Sep 25, 2022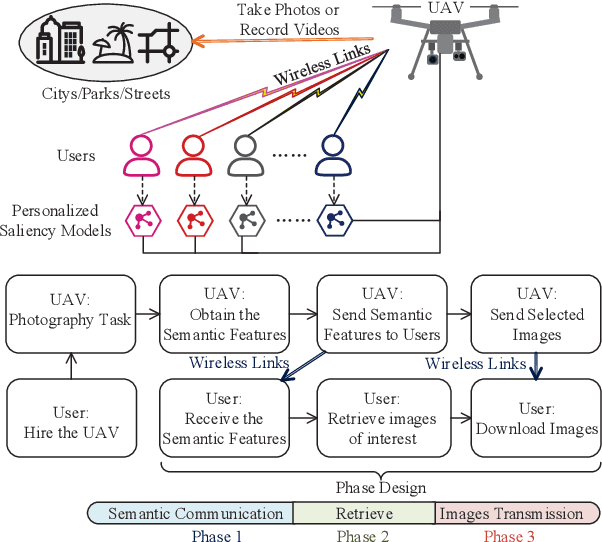
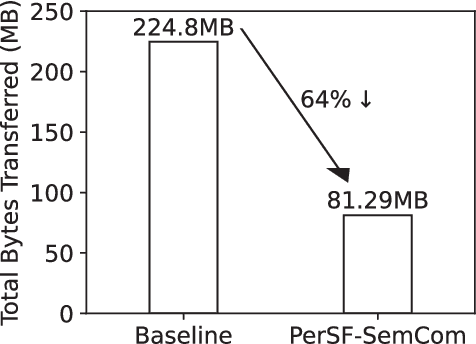
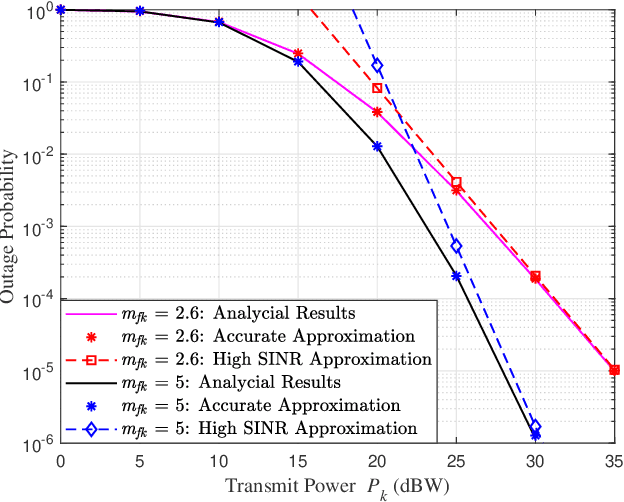
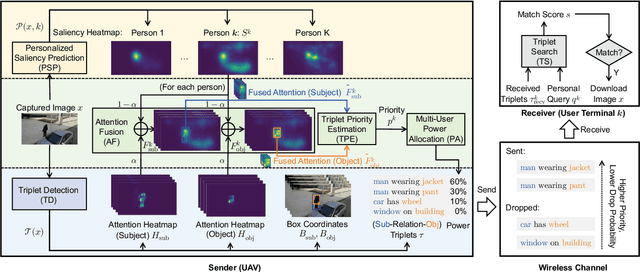
Semantic communication, as a promising technology, has emerged to break through the Shannon limit, which is envisioned as the key enabler and fundamental paradigm for future 6G networks and applications, e.g., smart healthcare. In this paper, we focus on UAV image-sensing-driven task-oriented semantic communications scenarios. The majority of existing work has focused on designing advanced algorithms for high-performance semantic communication. However, the challenges, such as energy-hungry and efficiency-limited image retrieval manner, and semantic encoding without considering user personality, have not been explored yet. These challenges have hindered the widespread adoption of semantic communication. To address the above challenges, at the semantic level, we first design an energy-efficient task-oriented semantic communication framework with a triple-based {\color{black}scene graph} for image information. We then design a new personalized semantic encoder based on user interests to meet the requirements of personalized saliency. Moreover, at the communication level, we study the effects of dynamic wireless fading channels on semantic transmission mathematically and thus design an optimal multi-user resource allocation scheme by using game theory. Numerical results based on real-world datasets clearly indicate that the proposed framework and schemes significantly enhance the personalization and anti-interference performance of semantic communication, and are also efficient to improve the communication quality of semantic communication services.
Aggregating Gradients in Encoded Domain for Federated Learning
Jun 09, 2022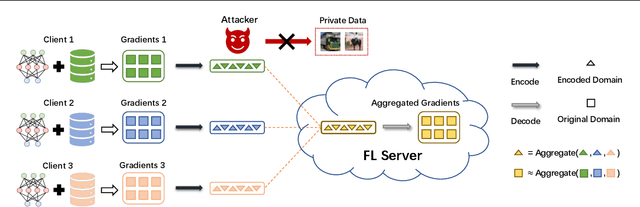
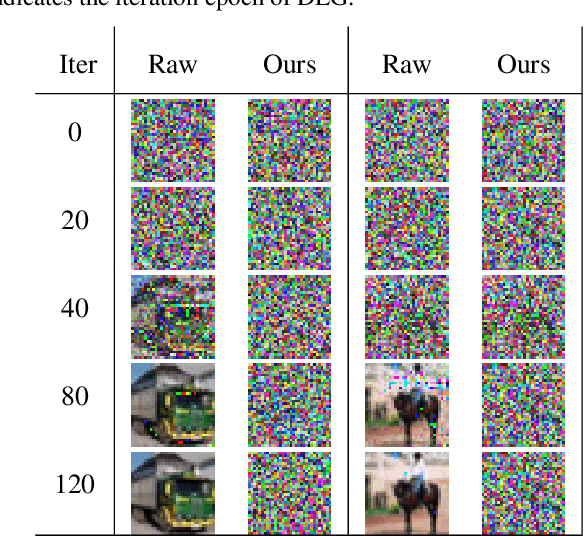

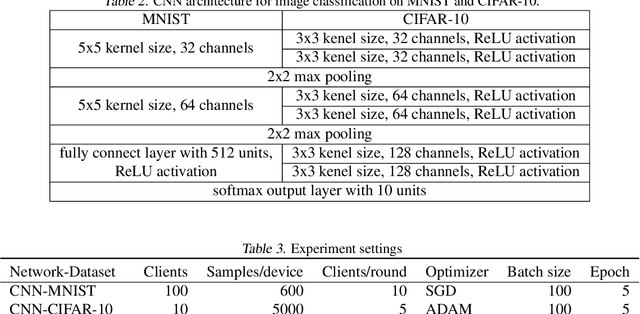
Malicious attackers and an honest-but-curious server can steal private client data from uploaded gradients in federated learning. Although current protection methods (e.g., additive homomorphic cryptosystem) can guarantee the security of the federated learning system, they bring additional computation and communication costs. To mitigate the cost, we propose the \texttt{FedAGE} framework, which enables the server to aggregate gradients in an encoded domain without accessing raw gradients of any single client. Thus, \texttt{FedAGE} can prevent the curious server from gradient stealing while maintaining the same prediction performance without additional communication costs. Furthermore, we theoretically prove that the proposed encoding-decoding framework is a Gaussian mechanism for differential privacy. Finally, we evaluate \texttt{FedAGE} under several federated settings, and the results have demonstrated the efficacy of the proposed framework.
CoFED: Cross-silo Heterogeneous Federated Multi-task Learning via Co-training
Feb 17, 2022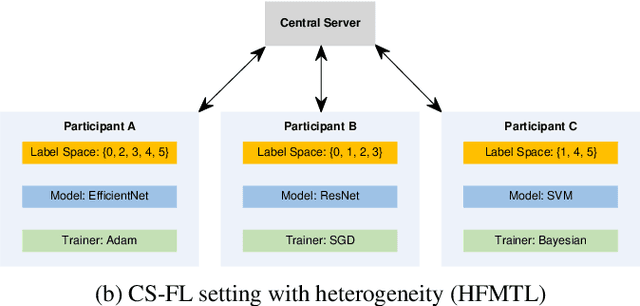
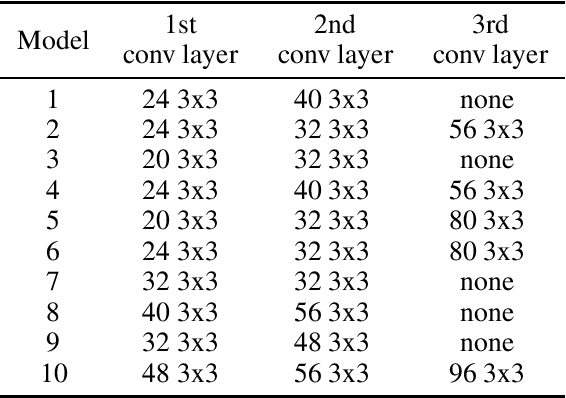
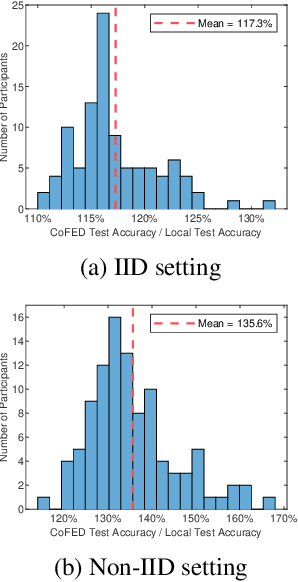

Federated Learning (FL) is a machine learning technique that enables participants to train high-quality models collaboratively without exchanging their private data. Participants in cross-silo FL settings are independent organizations with different task needs, and they are concerned not only with data privacy, but also with training independently their unique models due to intellectual property. Most existing FL schemes are incapability for the above scenarios. In this paper, we propose a communication-efficient FL scheme, CoFED, based on pseudo-labeling unlabeled data like co-training. To the best of our knowledge, it is the first FL scheme compatible with heterogeneous tasks, heterogeneous models, and heterogeneous training algorithms simultaneously. Experimental results show that CoFED achieves better performance with a lower communication cost. Especially for the non-IID settings and heterogeneous models, the proposed method improves the performance by 35%.