 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntellicise Wireless Networks Meet Agentic AI: A Security and Privacy Perspective
Feb 17, 2026Intellicise (Intelligent and Concise) wireless network is the main direction of the evolution of future mobile communication systems, a perspective now widely acknowledged across academia and industry. As a key technology within it, Agentic AI has garnered growing attention due to its advanced cognitive capabilities, enabled through continuous perception-memory-reasoning-action cycles. This paper first analyses the unique advantages that Agentic AI introduces to intellicise wireless networks. We then propose a structured taxonomy for Agentic AI-enhanced secure intellicise wireless networks. Building on this framework, we identify emerging security and privacy challenges introduced by Agentic AI and summarize targeted strategies to address these vulnerabilities. A case study further demonstrates Agentic AI's efficacy in defending against intelligent eavesdropping attacks. Finally, we outline key open research directions to guide future exploration in this field.
Large AI Model-Enabled Secure Communications in Low-Altitude Wireless Networks: Concepts, Perspectives and Case Study
Aug 01, 2025Low-altitude wireless networks (LAWNs) have the potential to revolutionize communications by supporting a range of applications, including urban parcel delivery, aerial inspections and air taxis. However, compared with traditional wireless networks, LAWNs face unique security challenges due to low-altitude operations, frequent mobility and reliance on unlicensed spectrum, making it more vulnerable to some malicious attacks. In this paper, we investigate some large artificial intelligence model (LAM)-enabled solutions for secure communications in LAWNs. Specifically, we first explore the amplified security risks and important limitations of traditional AI methods in LAWNs. Then, we introduce the basic concepts of LAMs and delve into the role of LAMs in addressing these challenges. To demonstrate the practical benefits of LAMs for secure communications in LAWNs, we propose a novel LAM-based optimization framework that leverages large language models (LLMs) to generate enhanced state features on top of handcrafted representations, and to design intrinsic rewards accordingly, thereby improving reinforcement learning performance for secure communication tasks. Through a typical case study, simulation results validate the effectiveness of the proposed framework. Finally, we outline future directions for integrating LAMs into secure LAWN applications.
RealGeneral: Unifying Visual Generation via Temporal In-Context Learning with Video Models
Mar 13, 2025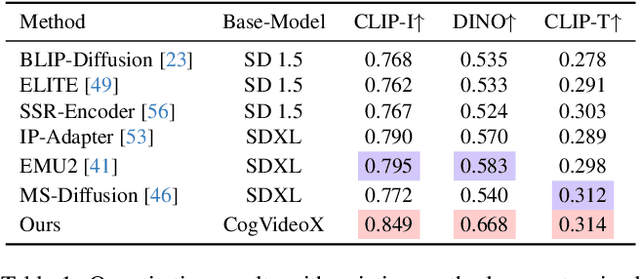
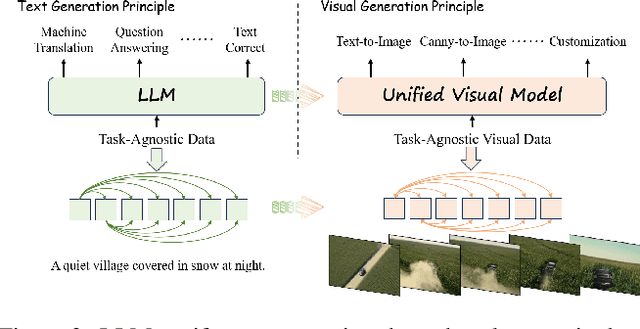
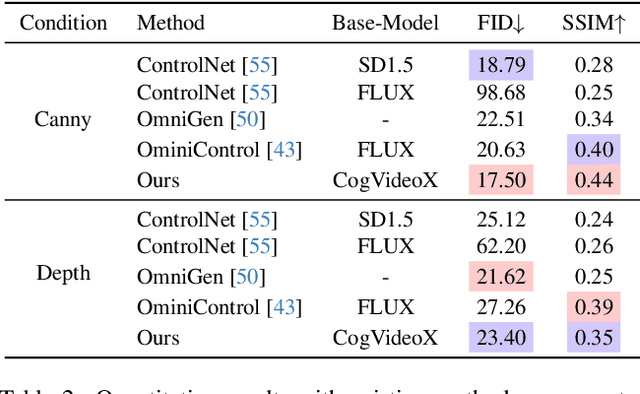
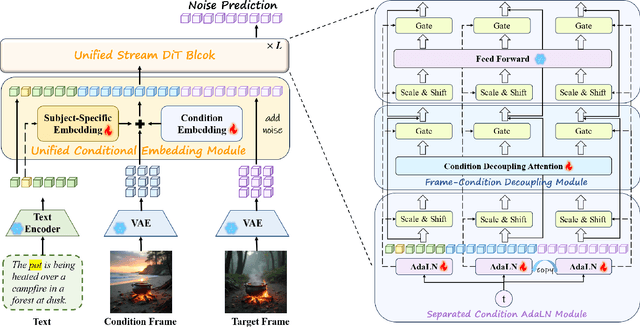
Unifying diverse image generation tasks within a single framework remains a fundamental challenge in visual generation. While large language models (LLMs) achieve unification through task-agnostic data and generation, existing visual generation models fail to meet these principles. Current approaches either rely on per-task datasets and large-scale training or adapt pre-trained image models with task-specific modifications, limiting their generalizability. In this work, we explore video models as a foundation for unified image generation, leveraging their inherent ability to model temporal correlations. We introduce RealGeneral, a novel framework that reformulates image generation as a conditional frame prediction task, analogous to in-context learning in LLMs. To bridge the gap between video models and condition-image pairs, we propose (1) a Unified Conditional Embedding module for multi-modal alignment and (2) a Unified Stream DiT Block with decoupled adaptive LayerNorm and attention mask to mitigate cross-modal interference. RealGeneral demonstrates effectiveness in multiple important visual generation tasks, e.g., it achieves a 14.5% improvement in subject similarity for customized generation and a 10% enhancement in image quality for canny-to-image task. Project page: https://lyne1.github.io/RealGeneral/
Mixture of Experts for Network Optimization: A Large Language Model-enabled Approach
Feb 15, 2024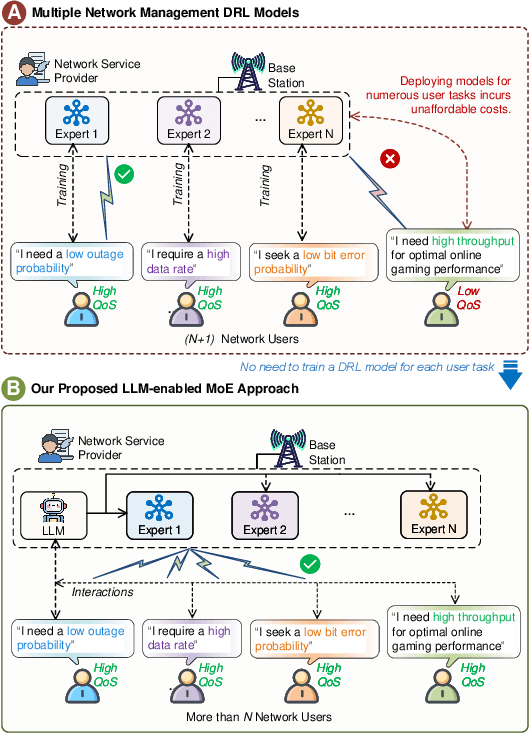
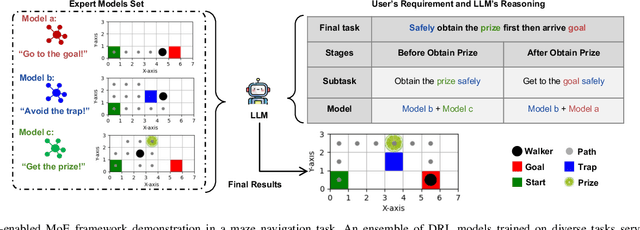
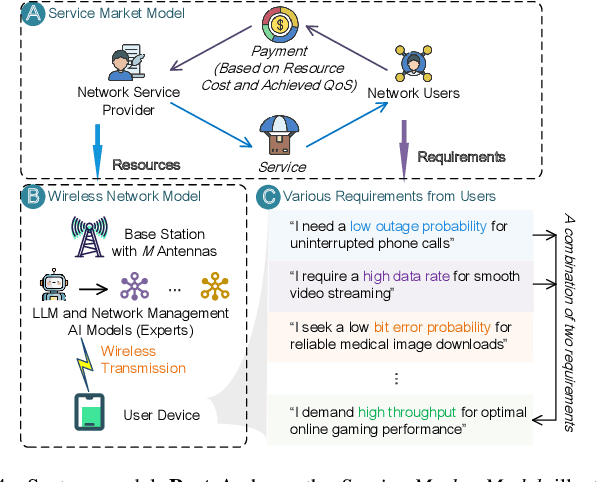
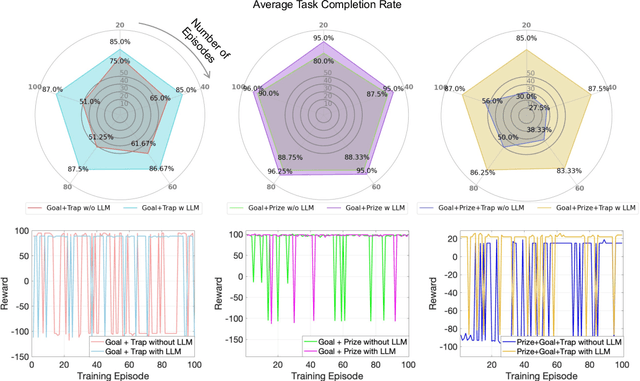
Optimizing various wireless user tasks poses a significant challenge for networking systems because of the expanding range of user requirements. Despite advancements in Deep Reinforcement Learning (DRL), the need for customized optimization tasks for individual users complicates developing and applying numerous DRL models, leading to substantial computation resource and energy consumption and can lead to inconsistent outcomes. To address this issue, we propose a novel approach utilizing a Mixture of Experts (MoE) framework, augmented with Large Language Models (LLMs), to analyze user objectives and constraints effectively, select specialized DRL experts, and weigh each decision from the participating experts. Specifically, we develop a gate network to oversee the expert models, allowing a collective of experts to tackle a wide array of new tasks. Furthermore, we innovatively substitute the traditional gate network with an LLM, leveraging its advanced reasoning capabilities to manage expert model selection for joint decisions. Our proposed method reduces the need to train new DRL models for each unique optimization problem, decreasing energy consumption and AI model implementation costs. The LLM-enabled MoE approach is validated through a general maze navigation task and a specific network service provider utility maximization task, demonstrating its effectiveness and practical applicability in optimizing complex networking systems.
Blockchain-enabled Trustworthy Federated Unlearning
Jan 29, 2024Federated unlearning is a promising paradigm for protecting the data ownership of distributed clients. It allows central servers to remove historical data effects within the machine learning model as well as address the "right to be forgotten" issue in federated learning. However, existing works require central servers to retain the historical model parameters from distributed clients, such that allows the central server to utilize these parameters for further training even, after the clients exit the training process. To address this issue, this paper proposes a new blockchain-enabled trustworthy federated unlearning framework. We first design a proof of federated unlearning protocol, which utilizes the Chameleon hash function to verify data removal and eliminate the data contributions stored in other clients' models. Then, an adaptive contribution-based retraining mechanism is developed to reduce the computational overhead and significantly improve the training efficiency. Extensive experiments demonstrate that the proposed framework can achieve a better data removal effect than the state-of-the-art frameworks, marking a significant stride towards trustworthy federated unlearning.
Scalable Federated Unlearning via Isolated and Coded Sharding
Jan 29, 2024

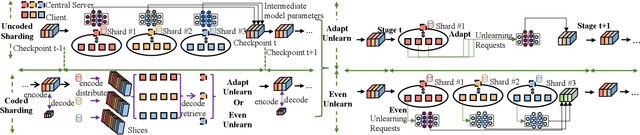

Federated unlearning has emerged as a promising paradigm to erase the client-level data effect without affecting the performance of collaborative learning models. However, the federated unlearning process often introduces extensive storage overhead and consumes substantial computational resources, thus hindering its implementation in practice. To address this issue, this paper proposes a scalable federated unlearning framework based on isolated sharding and coded computing. We first divide distributed clients into multiple isolated shards across stages to reduce the number of clients being affected. Then, to reduce the storage overhead of the central server, we develop a coded computing mechanism by compressing the model parameters across different shards. In addition, we provide the theoretical analysis of time efficiency and storage effectiveness for the isolated and coded sharding. Finally, extensive experiments on two typical learning tasks, i.e., classification and generation, demonstrate that our proposed framework can achieve better performance than three state-of-the-art frameworks in terms of accuracy, retraining time, storage overhead, and F1 scores for resisting membership inference attacks.
Beyond Deep Reinforcement Learning: A Tutorial on Generative Diffusion Models in Network Optimization
Aug 10, 2023Generative Diffusion Models (GDMs) have emerged as a transformative force in the realm of Generative Artificial Intelligence (GAI), demonstrating their versatility and efficacy across a variety of applications. The ability to model complex data distributions and generate high-quality samples has made GDMs particularly effective in tasks such as image generation and reinforcement learning. Furthermore, their iterative nature, which involves a series of noise addition and denoising steps, is a powerful and unique approach to learning and generating data. This paper serves as a comprehensive tutorial on applying GDMs in network optimization tasks. We delve into the strengths of GDMs, emphasizing their wide applicability across various domains, such as vision, text, and audio generation.We detail how GDMs can be effectively harnessed to solve complex optimization problems inherent in networks. The paper first provides a basic background of GDMs and their applications in network optimization. This is followed by a series of case studies, showcasing the integration of GDMs with Deep Reinforcement Learning (DRL), incentive mechanism design, Semantic Communications (SemCom), Internet of Vehicles (IoV) networks, etc. These case studies underscore the practicality and efficacy of GDMs in real-world scenarios, offering insights into network design. We conclude with a discussion on potential future directions for GDM research and applications, providing major insights into how they can continue to shape the future of network optimization.