 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLance: Unified Multimodal Modeling by Multi-Task Synergy
May 20, 2026We present Lance, a lightweight native unified model supporting multimodal understanding, generation, and editing for both images and videos. Rather than relying on model capacity scaling or text-image-dominant designs, Lance explores a practical paradigm for unified multimodal modeling via collaborative multi-task training. It is grounded in two core principles: unified context modeling and decoupled capability pathways. Specifically, Lance is trained from scratch and employs a dual-stream mixture-of-experts architecture on shared interleaved multimodal sequences, enabling joint context learning while decoupling the pathways for understanding and generation. We further introduce modality-aware rotary positional encoding to mitigate interference among heterogeneous visual tokens and boost cross-task alignment. During training, Lance adopts a staged multi-task training paradigm with capability-oriented objectives and adaptive data scheduling to strengthen both semantic comprehension and visual generation performance. Experimental results demonstrate that Lance substantially outperforms existing open-source unified models in image and video generation, while retaining strong multimodal understanding capabilities. The homepage is available at https://lance-project.github.io.
Stream-T1: Test-Time Scaling for Streaming Video Generation
May 06, 2026While Test-Time Scaling (TTS) offers a promising direction to enhance video generation without the surging costs of training, current test-time video generation methods based on diffusion models suffer from exorbitant candidate exploration costs and lack temporal guidance. To address these structural bottlenecks, we propose shifting the focus to streaming video generation. We identify that its chunk-level synthesis and few denoising steps are intrinsically suited for TTS, significantly lowering computational overhead while enabling fine-grained temporal control. Driven by this insight, we introduced Stream-T1, a pioneering comprehensive TTS framework exclusively tailored for streaming video generation. Specifically, Stream-T1 is composed of three units: (1) Stream -Scaled Noise Propagation, which actively refines the initial latent noise of the generating chunk using historically proven, high-quality previous chunk noise, effectively establishes temporal dependency and utilizing the historical Gaussian prior to guide the current generation; (2) Stream -Scaled Reward Pruning, which comprehensively evaluates generated candidates to strike an optimal balance between local spatial aesthetics and global temporal coherence by integrating immediate short-term assessments with sliding-window-based long-term evaluations; (3) Stream-Scaled Memory Sinking, which dynamically routes the context evicted from KV-cache into distinct updating pathways guided by the reward feedback, ensuring that previously generated visual information effectively anchors and guides the subsequent video stream. Evaluated on both 5s and 30s comprehensive video benchmarks, Stream-T1 demonstrates profound superiority, significantly improving temporal consistency, motion smoothness, and frame-level visual quality.
Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
May 05, 2026Distillation-based acceleration has become foundational for making autoregressive streaming video diffusion models practical, with distribution matching distillation (DMD) as the de facto choice. Existing methods, however, train the student to match the teacher's output indiscriminately, treating every rollout, frame, and pixel as equally reliable supervision. We argue that this caps distilled quality, since it overlooks two complementary axes of variance in DMD supervision: Inter-Reliability across student rollouts whose supervision varies in reliability, and Intra-Perplexity across spatial regions and temporal frames that contribute unequally to where quality can still be improved. The objective thus conflates two questions under a uniform weight: whether to learn from each rollout, and where to concentrate optimization within it. To address this, we propose Stream-R1, a Reliability-Perplexity Aware Reward Distillation framework that adaptively reweights the distillation objective at both rollout and spatiotemporal-element levels through a single shared reward-guided mechanism. At the Inter-Reliability level, Stream-R1 rescales each rollout's loss by an exponential of a pretrained video reward score, so that rollouts with reliable supervision dominate optimization. At the Intra-Perplexity level, it back-propagates the same reward model to extract per-pixel gradient saliency, which is factored into spatial and temporal weights that concentrate optimization pressure on regions and frames where refinement yields the largest expected gain. An adaptive balancing mechanism prevents any single quality axis from dominating across visual quality, motion quality, and text alignment. Stream-R1 attains consistent improvements on all three dimensions over distillation baselines on standard streaming video generation benchmarks, without architectural modification or additional inference cost.
NativeTok: Native Visual Tokenization for Improved Image Generation
Jan 30, 2026VQ-based image generation typically follows a two-stage pipeline: a tokenizer encodes images into discrete tokens, and a generative model learns their dependencies for reconstruction. However, improved tokenization in the first stage does not necessarily enhance the second-stage generation, as existing methods fail to constrain token dependencies. This mismatch forces the generative model to learn from unordered distributions, leading to bias and weak coherence. To address this, we propose native visual tokenization, which enforces causal dependencies during tokenization. Building on this idea, we introduce NativeTok, a framework that achieves efficient reconstruction while embedding relational constraints within token sequences. NativeTok consists of: (1) a Meta Image Transformer (MIT) for latent image modeling, and (2) a Mixture of Causal Expert Transformer (MoCET), where each lightweight expert block generates a single token conditioned on prior tokens and latent features. We further design a Hierarchical Native Training strategy that updates only new expert blocks, ensuring training efficiency. Extensive experiments demonstrate the effectiveness of NativeTok.
LayerEdit: Disentangled Multi-Object Editing via Conflict-Aware Multi-Layer Learning
Nov 11, 2025



Text-driven multi-object image editing which aims to precisely modify multiple objects within an image based on text descriptions, has recently attracted considerable interest. Existing works primarily follow the localize-editing paradigm, focusing on independent object localization and editing while neglecting critical inter-object interactions. However, this work points out that the neglected attention entanglements in inter-object conflict regions, inherently hinder disentangled multi-object editing, leading to either inter-object editing leakage or intra-object editing constraints. We thereby propose a novel multi-layer disentangled editing framework LayerEdit, a training-free method which, for the first time, through precise object-layered decomposition and coherent fusion, enables conflict-free object-layered editing. Specifically, LayerEdit introduces a novel "decompose-editingfusion" framework, consisting of: (1) Conflict-aware Layer Decomposition module, which utilizes an attention-aware IoU scheme and time-dependent region removing, to enhance conflict awareness and suppression for layer decomposition. (2) Object-layered Editing module, to establish coordinated intra-layer text guidance and cross-layer geometric mapping, achieving disentangled semantic and structural modifications. (3) Transparency-guided Layer Fusion module, to facilitate structure-coherent inter-object layer fusion through precise transparency guidance learning. Extensive experiments verify the superiority of LayerEdit over existing methods, showing unprecedented intra-object controllability and inter-object coherence in complex multi-object scenarios. Codes are available at: https://github.com/fufy1024/LayerEdit.
USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning
Aug 26, 2025Existing literature typically treats style-driven and subject-driven generation as two disjoint tasks: the former prioritizes stylistic similarity, whereas the latter insists on subject consistency, resulting in an apparent antagonism. We argue that both objectives can be unified under a single framework because they ultimately concern the disentanglement and re-composition of content and style, a long-standing theme in style-driven research. To this end, we present USO, a Unified Style-Subject Optimized customization model. First, we construct a large-scale triplet dataset consisting of content images, style images, and their corresponding stylized content images. Second, we introduce a disentangled learning scheme that simultaneously aligns style features and disentangles content from style through two complementary objectives, style-alignment training and content-style disentanglement training. Third, we incorporate a style reward-learning paradigm denoted as SRL to further enhance the model's performance. Finally, we release USO-Bench, the first benchmark that jointly evaluates style similarity and subject fidelity across multiple metrics. Extensive experiments demonstrate that USO achieves state-of-the-art performance among open-source models along both dimensions of subject consistency and style similarity. Code and model: https://github.com/bytedance/USO
LongAnimation: Long Animation Generation with Dynamic Global-Local Memory
Jul 02, 2025



Animation colorization is a crucial part of real animation industry production. Long animation colorization has high labor costs. Therefore, automated long animation colorization based on the video generation model has significant research value. Existing studies are limited to short-term colorization. These studies adopt a local paradigm, fusing overlapping features to achieve smooth transitions between local segments. However, the local paradigm neglects global information, failing to maintain long-term color consistency. In this study, we argue that ideal long-term color consistency can be achieved through a dynamic global-local paradigm, i.e., dynamically extracting global color-consistent features relevant to the current generation. Specifically, we propose LongAnimation, a novel framework, which mainly includes a SketchDiT, a Dynamic Global-Local Memory (DGLM), and a Color Consistency Reward. The SketchDiT captures hybrid reference features to support the DGLM module. The DGLM module employs a long video understanding model to dynamically compress global historical features and adaptively fuse them with the current generation features. To refine the color consistency, we introduce a Color Consistency Reward. During inference, we propose a color consistency fusion to smooth the video segment transition. Extensive experiments on both short-term (14 frames) and long-term (average 500 frames) animations show the effectiveness of LongAnimation in maintaining short-term and long-term color consistency for open-domain animation colorization task. The code can be found at https://cn-makers.github.io/long_animation_web/.
HDGlyph: A Hierarchical Disentangled Glyph-Based Framework for Long-Tail Text Rendering in Diffusion Models
May 10, 2025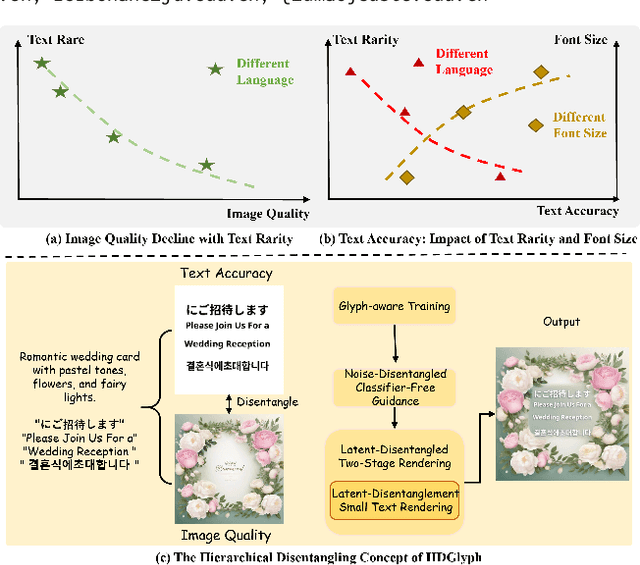
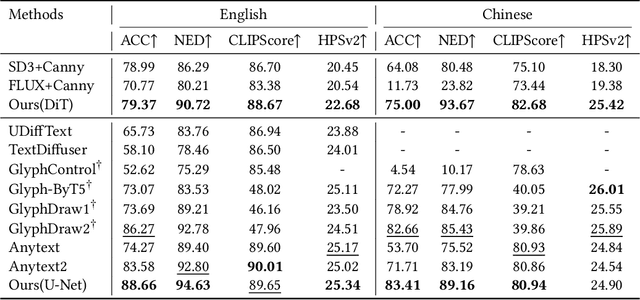
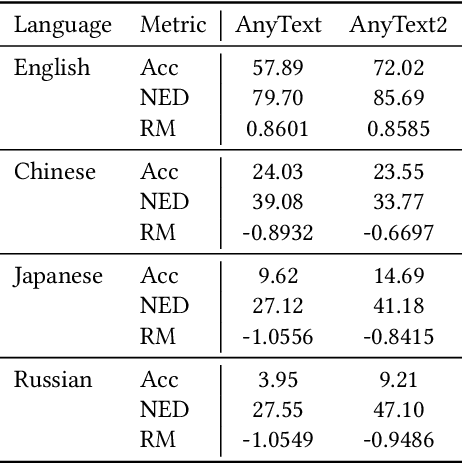
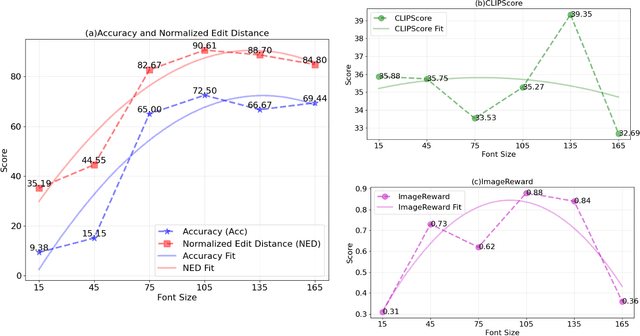
Visual text rendering, which aims to accurately integrate specified textual content within generated images, is critical for various applications such as commercial design. Despite recent advances, current methods struggle with long-tail text cases, particularly when handling unseen or small-sized text. In this work, we propose a novel Hierarchical Disentangled Glyph-Based framework (HDGlyph) that hierarchically decouples text generation from non-text visual synthesis, enabling joint optimization of both common and long-tail text rendering. At the training stage, HDGlyph disentangles pixel-level representations via the Multi-Linguistic GlyphNet and the Glyph-Aware Perceptual Loss, ensuring robust rendering even for unseen characters. At inference time, HDGlyph applies Noise-Disentangled Classifier-Free Guidance and Latent-Disentangled Two-Stage Rendering (LD-TSR) scheme, which refines both background and small-sized text. Extensive evaluations show our model consistently outperforms others, with 5.08% and 11.7% accuracy gains in English and Chinese text rendering while maintaining high image quality. It also excels in long-tail scenarios with strong accuracy and visual performance.
DualReal: Adaptive Joint Training for Lossless Identity-Motion Fusion in Video Customization
May 04, 2025Customized text-to-video generation with pre-trained large-scale models has recently garnered significant attention through focusing on identity and motion consistency. Existing works typically follow the isolated customized paradigm, where the subject identity or motion dynamics are customized exclusively. However, this paradigm completely ignores the intrinsic mutual constraints and synergistic interdependencies between identity and motion, resulting in identity-motion conflicts throughout the generation process that systematically degrades. To address this, we introduce DualReal, a novel framework that, employs adaptive joint training to collaboratively construct interdependencies between dimensions. Specifically, DualReal is composed of two units: (1) Dual-aware Adaptation dynamically selects a training phase (i.e., identity or motion), learns the current information guided by the frozen dimension prior, and employs a regularization strategy to avoid knowledge leakage; (2) StageBlender Controller leverages the denoising stages and Diffusion Transformer depths to guide different dimensions with adaptive granularity, avoiding conflicts at various stages and ultimately achieving lossless fusion of identity and motion patterns. We constructed a more comprehensive benchmark than existing methods. The experimental results show that DualReal improves CLIP-I and DINO-I metrics by 21.7% and 31.8% on average, and achieves top performance on nearly all motion quality metrics.
D$^2$iT: Dynamic Diffusion Transformer for Accurate Image Generation
Apr 13, 2025



Diffusion models are widely recognized for their ability to generate high-fidelity images. Despite the excellent performance and scalability of the Diffusion Transformer (DiT) architecture, it applies fixed compression across different image regions during the diffusion process, disregarding the naturally varying information densities present in these regions. However, large compression leads to limited local realism, while small compression increases computational complexity and compromises global consistency, ultimately impacting the quality of generated images. To address these limitations, we propose dynamically compressing different image regions by recognizing the importance of different regions, and introduce a novel two-stage framework designed to enhance the effectiveness and efficiency of image generation: (1) Dynamic VAE (DVAE) at first stage employs a hierarchical encoder to encode different image regions at different downsampling rates, tailored to their specific information densities, thereby providing more accurate and natural latent codes for the diffusion process. (2) Dynamic Diffusion Transformer (D$^2$iT) at second stage generates images by predicting multi-grained noise, consisting of coarse-grained (less latent code in smooth regions) and fine-grained (more latent codes in detailed regions), through an novel combination of the Dynamic Grain Transformer and the Dynamic Content Transformer. The strategy of combining rough prediction of noise with detailed regions correction achieves a unification of global consistency and local realism. Comprehensive experiments on various generation tasks validate the effectiveness of our approach. Code will be released at https://github.com/jiawn-creator/Dynamic-DiT.