 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning
Aug 26, 2025Existing literature typically treats style-driven and subject-driven generation as two disjoint tasks: the former prioritizes stylistic similarity, whereas the latter insists on subject consistency, resulting in an apparent antagonism. We argue that both objectives can be unified under a single framework because they ultimately concern the disentanglement and re-composition of content and style, a long-standing theme in style-driven research. To this end, we present USO, a Unified Style-Subject Optimized customization model. First, we construct a large-scale triplet dataset consisting of content images, style images, and their corresponding stylized content images. Second, we introduce a disentangled learning scheme that simultaneously aligns style features and disentangles content from style through two complementary objectives, style-alignment training and content-style disentanglement training. Third, we incorporate a style reward-learning paradigm denoted as SRL to further enhance the model's performance. Finally, we release USO-Bench, the first benchmark that jointly evaluates style similarity and subject fidelity across multiple metrics. Extensive experiments demonstrate that USO achieves state-of-the-art performance among open-source models along both dimensions of subject consistency and style similarity. Code and model: https://github.com/bytedance/USO
Less-to-More Generalization: Unlocking More Controllability by In-Context Generation
Apr 02, 2025Although subject-driven generation has been extensively explored in image generation due to its wide applications, it still has challenges in data scalability and subject expansibility. For the first challenge, moving from curating single-subject datasets to multiple-subject ones and scaling them is particularly difficult. For the second, most recent methods center on single-subject generation, making it hard to apply when dealing with multi-subject scenarios. In this study, we propose a highly-consistent data synthesis pipeline to tackle this challenge. This pipeline harnesses the intrinsic in-context generation capabilities of diffusion transformers and generates high-consistency multi-subject paired data. Additionally, we introduce UNO, which consists of progressive cross-modal alignment and universal rotary position embedding. It is a multi-image conditioned subject-to-image model iteratively trained from a text-to-image model. Extensive experiments show that our method can achieve high consistency while ensuring controllability in both single-subject and multi-subject driven generation.
VMix: Improving Text-to-Image Diffusion Model with Cross-Attention Mixing Control
Dec 30, 2024
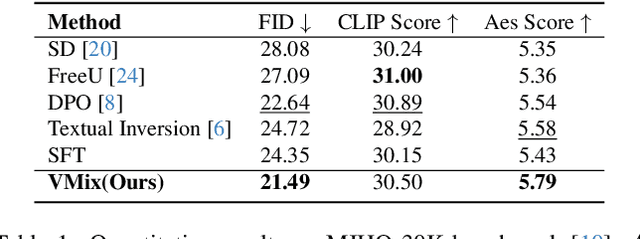
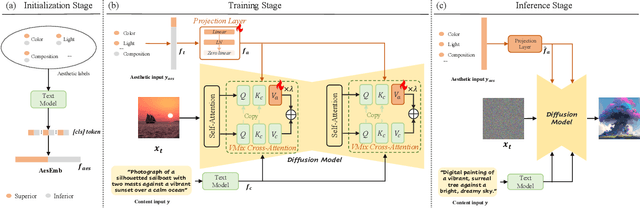
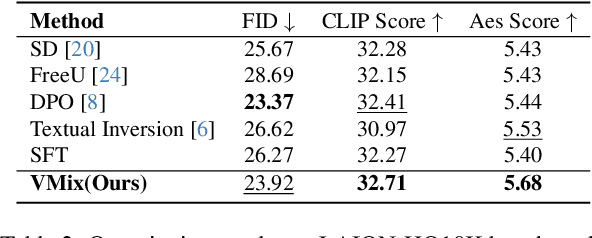
While diffusion models show extraordinary talents in text-to-image generation, they may still fail to generate highly aesthetic images. More specifically, there is still a gap between the generated images and the real-world aesthetic images in finer-grained dimensions including color, lighting, composition, etc. In this paper, we propose Cross-Attention Value Mixing Control (VMix) Adapter, a plug-and-play aesthetics adapter, to upgrade the quality of generated images while maintaining generality across visual concepts by (1) disentangling the input text prompt into the content description and aesthetic description by the initialization of aesthetic embedding, and (2) integrating aesthetic conditions into the denoising process through value-mixed cross-attention, with the network connected by zero-initialized linear layers. Our key insight is to enhance the aesthetic presentation of existing diffusion models by designing a superior condition control method, all while preserving the image-text alignment. Through our meticulous design, VMix is flexible enough to be applied to community models for better visual performance without retraining. To validate the effectiveness of our method, we conducted extensive experiments, showing that VMix outperforms other state-of-the-art methods and is compatible with other community modules (e.g., LoRA, ControlNet, and IPAdapter) for image generation. The project page is https://vmix-diffusion.github.io/VMix/.
Towards Complex Real-World Safety Factory Inspection: A High-Quality Dataset for Safety Clothing and Helmet Detection
Jun 03, 2023Safety clothing and helmets play a crucial role in ensuring worker safety at construction sites. Recently, deep learning methods have garnered significant attention in the field of computer vision for their potential to enhance safety and efficiency in various industries. However, limited availability of high-quality datasets has hindered the development of deep learning methods for safety clothing and helmet detection. In this work, we present a large, comprehensive, and realistic high-quality dataset for safety clothing and helmet detection, which was collected from a real-world chemical plant and annotated by professional security inspectors. Our dataset has been compared with several existing open-source datasets, and its effectiveness has been verified applying some classic object detection methods. The results demonstrate that our dataset is more complete and performs better in real-world settings. Furthermore, we have released our deployment code to the public to encourage the adoption of our dataset and improve worker safety. We hope that our efforts will promote the convergence of academic research and industry, ultimately contribute to the betterment of society.