 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Chaos: Efficient Autoscaling and Self-healing for Distributed Training at the Edge
May 19, 2025Frequent node and link changes in edge AI clusters disrupt distributed training, while traditional checkpoint-based recovery and cloud-centric autoscaling are too slow for scale-out and ill-suited to chaotic and self-governed edge. This paper proposes Chaos, a resilient and scalable edge distributed training system with built-in self-healing and autoscaling. It speeds up scale-out by using multi-neighbor replication with fast shard scheduling, allowing a new node to pull the latest training state from nearby neighbors in parallel while balancing the traffic load between them. It also uses a cluster monitor to track resource and topology changes to assist scheduler decisions, and handles scaling events through peer negotiation protocols, enabling fully self-governed autoscaling without a central admin. Extensive experiments show that Chaos consistently achieves much lower scale-out delays than Pollux, EDL, and Autoscaling, and handles scale-in, connect-link, and disconnect-link events within 1 millisecond, making it smoother to handle node joins, exits, and failures. It also delivers the lowest idle time, showing superior resource use and scalability as the cluster grows.
A Trustworthy Multi-LLM Network: Challenges,Solutions, and A Use Case
May 06, 2025Large Language Models (LLMs) demonstrate strong potential across a variety of tasks in communications and networking due to their advanced reasoning capabilities. However, because different LLMs have different model structures and are trained using distinct corpora and methods, they may offer varying optimization strategies for the same network issues. Moreover, the limitations of an individual LLM's training data, aggravated by the potential maliciousness of its hosting device, can result in responses with low confidence or even bias. To address these challenges, we propose a blockchain-enabled collaborative framework that connects multiple LLMs into a Trustworthy Multi-LLM Network (MultiLLMN). This architecture enables the cooperative evaluation and selection of the most reliable and high-quality responses to complex network optimization problems. Specifically, we begin by reviewing related work and highlighting the limitations of existing LLMs in collaboration and trust, emphasizing the need for trustworthiness in LLM-based systems. We then introduce the workflow and design of the proposed Trustworthy MultiLLMN framework. Given the severity of False Base Station (FBS) attacks in B5G and 6G communication systems and the difficulty of addressing such threats through traditional modeling techniques, we present FBS defense as a case study to empirically validate the effectiveness of our approach. Finally, we outline promising future research directions in this emerging area.
Cluster-Based Multi-Agent Task Scheduling for Space-Air-Ground Integrated Networks
Dec 14, 2024



The Space-Air-Ground Integrated Network (SAGIN) framework is a crucial foundation for future networks, where satellites and aerial nodes assist in computational task offloading. The low-altitude economy, leveraging the flexibility and multifunctionality of Unmanned Aerial Vehicles (UAVs) in SAGIN, holds significant potential for development in areas such as communication and sensing. However, effective coordination is needed to streamline information exchange and enable efficient system resource allocation. In this paper, we propose a Clustering-based Multi-agent Deep Deterministic Policy Gradient (CMADDPG) algorithm to address the multi-UAV cooperative task scheduling challenges in SAGIN. The CMADDPG algorithm leverages dynamic UAV clustering to partition UAVs into clusters, each managed by a Cluster Head (CH) UAV, facilitating a distributed-centralized control approach. Within each cluster, UAVs delegate offloading decisions to the CH UAV, reducing intra-cluster communication costs and decision conflicts, thereby enhancing task scheduling efficiency. Additionally, by employing a multi-agent reinforcement learning framework, the algorithm leverages the extensive coverage of satellites to achieve centralized training and distributed execution of multi-agent tasks, while maximizing overall system profit through optimized task offloading decision-making. Simulation results reveal that the CMADDPG algorithm effectively optimizes resource allocation, minimizes queue delays, maintains balanced load distribution, and surpasses existing methods by achieving at least a 25\% improvement in system profit, showcasing its robustness and adaptability across diverse scenarios.
Convergence of Symbiotic Communications and Blockchain for Sustainable and Trustworthy 6G Wireless Networks
Aug 11, 2024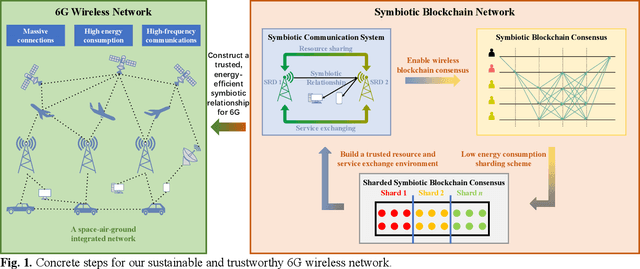
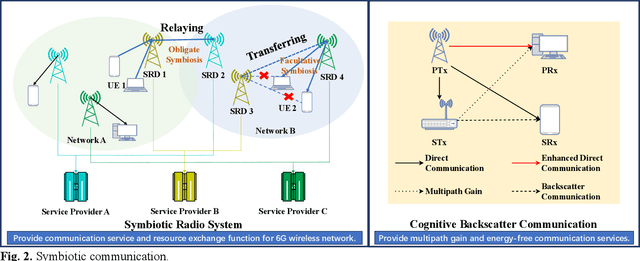
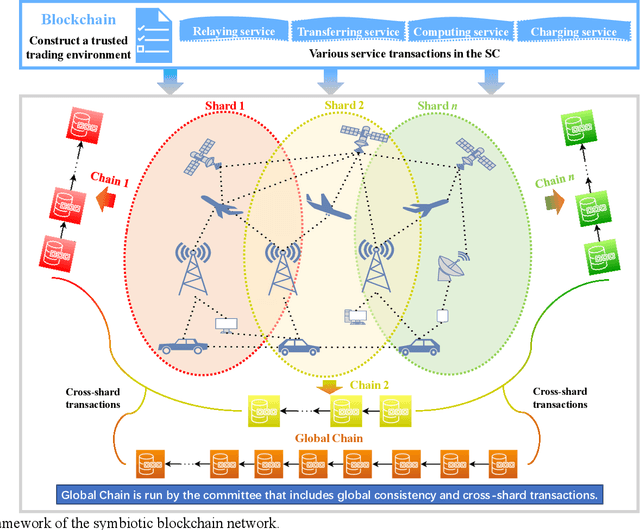
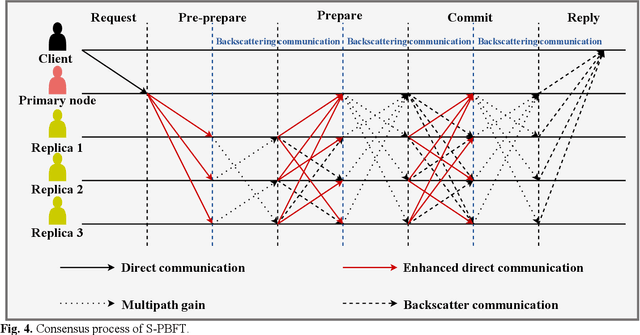
Symbiotic communication (SC) is known as a new wireless communication paradigm, similar to the natural ecosystem population, and can enable multiple communication systems to cooperate and mutualize through service exchange and resource sharing. As a result, SC is seen as an important potential technology for future sixth-generation (6G) communications, solving the problem of lack of spectrum resources and energy inefficiency. Symbiotic relationships among communication systems can complement radio resources in 6G. However, the absence of established trust relationships among diverse communication systems presents a formidable hurdle in ensuring efficient and trusted resource and service exchange within SC frameworks. To better realize trusted SC services in 6G, in this paper, we propose a solution that converges SC and blockchain, called a symbiotic blockchain network (SBN). Specifically, we first use cognitive backscatter communication to transform blockchain consensus, that is, the symbiotic blockchain consensus (SBC), so that it can be better suited for the wireless network. Then, for SBC, we propose a highly energy-efficient sharding scheme to meet the extremely low power consumption requirements in 6G. Finally, such a blockchain scheme guarantees trusted transactions of communication services in SC. Through ablation experiments, our proposed SBN demonstrates significant efficacy in mitigating energy consumption and reducing processing latency in adversarial networks, which is expected to achieve a sustainable and trusted 6G wireless network.
Wav2SQL: Direct Generalizable Speech-To-SQL Parsing
May 21, 2023



Speech-to-SQL (S2SQL) aims to convert spoken questions into SQL queries given relational databases, which has been traditionally implemented in a cascaded manner while facing the following challenges: 1) model training is faced with the major issue of data scarcity, where limited parallel data is available; and 2) the systems should be robust enough to handle diverse out-of-domain speech samples that differ from the source data. In this work, we propose the first direct speech-to-SQL parsing model Wav2SQL which avoids error compounding across cascaded systems. Specifically, 1) to accelerate speech-driven SQL parsing research in the community, we release a large-scale and multi-speaker dataset MASpider; 2) leveraging the recent progress in the large-scale pre-training, we show that it alleviates the data scarcity issue and allow for direct speech-to-SQL parsing; and 3) we include the speech re-programming and gradient reversal classifier techniques to reduce acoustic variance and learned style-agnostic representation, improving generalization to unseen out-of-domain custom data. Experimental results demonstrate that Wav2SQL avoids error compounding and achieves state-of-the-art results by up to 2.5\% accuracy improvement over the baseline.
SPSQL: Step-by-step Parsing Based Framework for Text-to-SQL Generation
May 10, 2023



Converting text into the structured query language (Text2SQL) is a research hotspot in the field of natural language processing (NLP), which has broad application prospects. In the era of big data, the use of databases has penetrated all walks of life, in which the collected data is large in scale, diverse in variety, and wide in scope, making the data query cumbersome and inefficient, and putting forward higher requirements for the Text2SQL model. In practical applications, the current mainstream end-to-end Text2SQL model is not only difficult to build due to its complex structure and high requirements for training data, but also difficult to adjust due to massive parameters. In addition, the accuracy of the model is hard to achieve the desired result. Based on this, this paper proposes a pipelined Text2SQL method: SPSQL. This method disassembles the Text2SQL task into four subtasks--table selection, column selection, SQL generation, and value filling, which can be converted into a text classification problem, a sequence labeling problem, and two text generation problems, respectively. Then, we construct data formats of different subtasks based on existing data and improve the accuracy of the overall model by improving the accuracy of each submodel. We also use the named entity recognition module and data augmentation to optimize the overall model. We construct the dataset based on the marketing business data of the State Grid Corporation of China. Experiments demonstrate our proposed method achieves the best performance compared with the end-to-end method and other pipeline methods.
ESCM: An Efficient and Secure Communication Mechanism for UAV Networks
Apr 26, 2023



UAV (unmanned aerial vehicle) is gradually entering various human activities. It has also become an important part of satellite-air-ground-sea integrated network (SAGS) for 6G communication. In order to achieve high mobility, UAV has strict requirements on communication latency, and it cannot be illegally controlled as weapons of attack with malicious intentions. Therefore, an efficient and secure communication method specifically designed for UAV network is required. This paper proposes a communication mechanism named ESCM for the above requirements. For high efficiency of communication, ESCM designs a routing protocol based on artificial bee colony algorithm (ABC) for UAV network to accelerate communication between UAVs. Meanwhile, we plan to use blockchain to guarantee the communication security of UAV networks. However, blockchain has unstable links in high mobility network scenarios, resulting in low consensus efficiency and high communication overhead. Therefore, ESCM also introduces the concept of the digital twin, mapping the UAVs from the physical world into Cyberspace, transforming the UAV network into a static network. And this virtual UAV network is called CyberUAV. Then, in CyberUAV, we design a blockchain system and propose a consensus algorithm based on network coding, named proof of network coding (PoNC). PoNC not only ensures the security of ESCM, but also further improves the performance of ESCM through network coding. Simulation results show that ESCM has obvious advantages in communication efficiency and security. Moreover, encoding messages through PoNC consensus can increase the network throughput, and make mobile blockchain static through digital twin can improve the consensus success rate.
Performance Analysis and Comparison of Non-ideal Wireless PBFT and RAFT Consensus Networks in 6G Communications
Apr 18, 2023Due to advantages in security and privacy, blockchain is considered a key enabling technology to support 6G communications. Practical Byzantine Fault Tolerance (PBFT) and RAFT are seen as the most applicable consensus mechanisms (CMs) in blockchain-enabled wireless networks. However, previous studies on PBFT and RAFT rarely consider the channel performance of the physical layer, such as path loss and channel fading, resulting in research results that are far from real networks. Additionally, 6G communications will widely deploy high-frequency signals such as terahertz (THz) and millimeter wave (mmWave), while performances of PBFT and RAFT are still unknown when these signals are transmitted in wireless PBFT or RAFT networks. Therefore, it is urgent to study the performance of non-ideal wireless PBFT and RAFT networks with THz and mmWave signals, to better make PBFT and RAFT play a role in the 6G era. In this paper, we study and compare the performance of THz and mmWave signals in non-ideal wireless PBFT and RAFT networks, considering Rayleigh Fading (RF) and close-in Free Space (FS) reference distance path loss. Performance is evaluated by five metrics: consensus success rate, latency, throughput, reliability gain, and energy consumption. Meanwhile, we find and derive that there is a maximum distance between two nodes that can make CMs inevitably successful, and it is named the active distance of CMs. The research results not only analyze the performance of non-ideal wireless PBFT and RAFT networks, but also provide important references for the future transmission of THz and mmWave signals in PBFT and RAFT networks.
Performance Analysis of Non-ideal Wireless PBFT Networks with mmWave and Terahertz Signals
Mar 28, 2023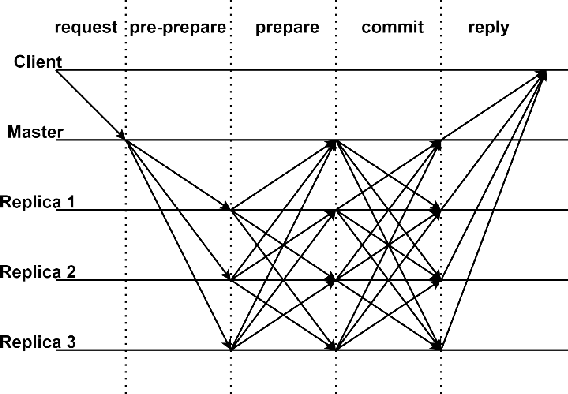
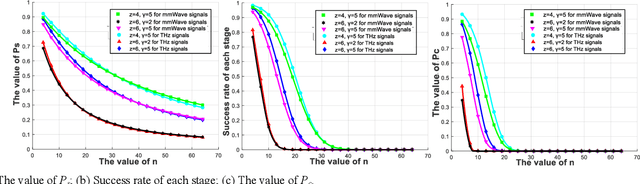
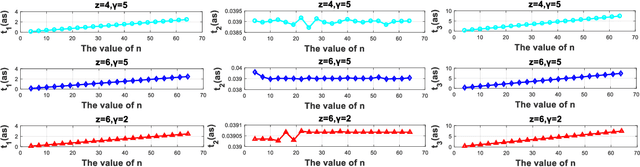
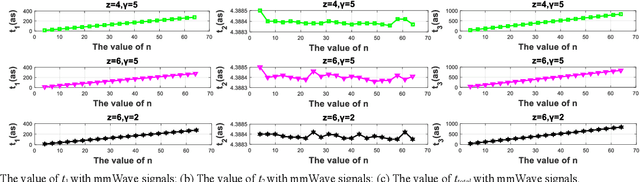
Due to advantages in security and privacy, blockchain is considered a key enabling technology to support 6G communications. Practical Byzantine Fault Tolerance (PBFT) is seen as the most applicable consensus mechanism in blockchain-enabled wireless networks. However, previous studies on PBFT do not consider the channel performance of the physical layer, such as path loss and channel fading, resulting in research results that are far from real networks. Additionally, 6G communications will widely deploy high frequency signals such as millimeter wave (mmWave) and terahertz (THz), while the performance of PBFT is still unknown when these signals are transmitted in wireless PBFT networks. Therefore, it is urgent to study the performance of non-ideal wireless PBFT networks with mmWave and THz siganls, so as to better make PBFT play a role in 6G era. In this paper, we study and compare the performance of mmWave and THz signals in non-ideal wireless PBFT networks, considering Rayleigh Fading (RF) and close-in Free Space (FS) reference distance path loss. Performance is evaluated by consensus success rate and delay. Meanwhile, we find and derive that there is a maximum distance between two nodes that can make PBFT consensus inevitably successful, and it is named active distance of PBFT in this paper. The research results not only analyze the performance of non-ideal wireless PBFT networks, but also provide an important reference for the future transmission of mmWave and THz signals in PBFT networks.
HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
Sep 21, 2022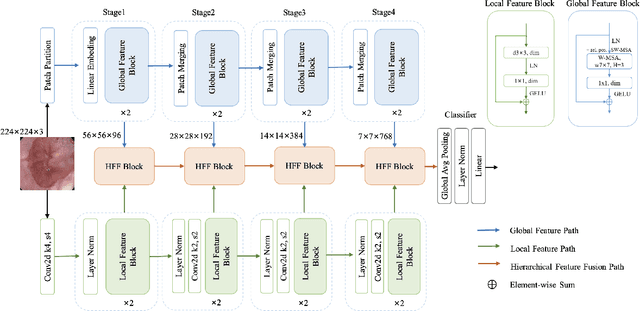
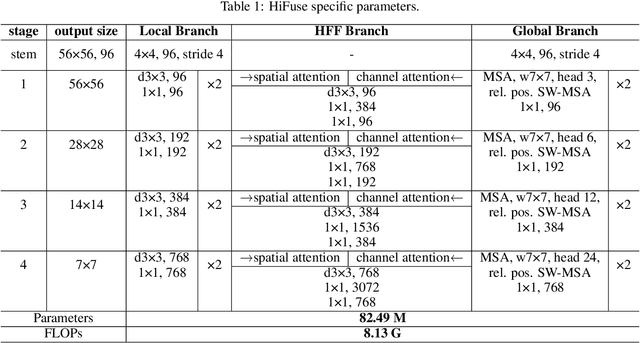
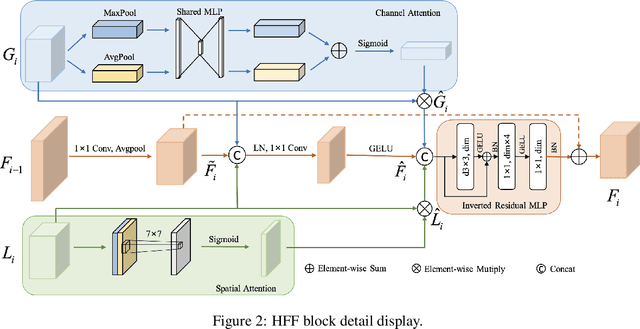
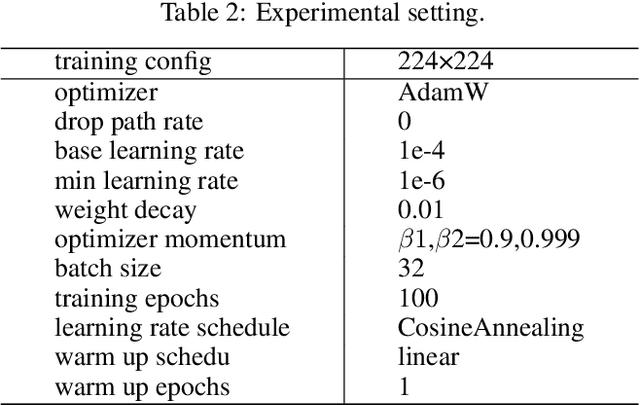
Medical image classification has developed rapidly under the impetus of the convolutional neural network (CNN). Due to the fixed size of the receptive field of the convolution kernel, it is difficult to capture the global features of medical images. Although the self-attention-based Transformer can model long-range dependencies, it has high computational complexity and lacks local inductive bias. Much research has demonstrated that global and local features are crucial for image classification. However, medical images have a lot of noisy, scattered features, intra-class variation, and inter-class similarities. This paper proposes a three-branch hierarchical multi-scale feature fusion network structure termed as HiFuse for medical image classification as a new method. It can fuse the advantages of Transformer and CNN from multi-scale hierarchies without destroying the respective modeling so as to improve the classification accuracy of various medical images. A parallel hierarchy of local and global feature blocks is designed to efficiently extract local features and global representations at various semantic scales, with the flexibility to model at different scales and linear computational complexity relevant to image size. Moreover, an adaptive hierarchical feature fusion block (HFF block) is designed to utilize the features obtained at different hierarchical levels comprehensively. The HFF block contains spatial attention, channel attention, residual inverted MLP, and shortcut to adaptively fuse semantic information between various scale features of each branch. The accuracy of our proposed model on the ISIC2018 dataset is 7.6% higher than baseline, 21.5% on the Covid-19 dataset, and 10.4% on the Kvasir dataset. Compared with other advanced models, the HiFuse model performs the best. Our code is open-source and available from https://github.com/huoxiangzuo/HiFuse.