 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAT: Online Video Understanding Needs Watching Before Thinking
Mar 12, 2026Multimodal Large Language Models (MLLMs) have shown strong capabilities in image understanding, motivating recent efforts to extend them to video reasoning. However, existing Video LLMs struggle in online streaming scenarios, where long temporal context must be preserved under strict memory constraints. We propose WAT (Watching Before Thinking), a two-stage framework for online video reasoning. WAT separates processing into a query-independent watching stage and a query-triggered thinking stage. The watching stage builds a hierarchical memory system with a Short-Term Memory (STM) that buffers recent frames and a fixed-capacity Long-Term Memory (LTM) that maintains a diverse summary of historical content using a redundancy-aware eviction policy. In the thinking stage, a context-aware retrieval mechanism combines the query with the current STM context to retrieve relevant historical frames from the LTM for cross-temporal reasoning. To support training for online video tasks, we introduce WAT-85K, a dataset containing streaming-style annotations emphasizing real-time perception, backward tracing, and forecasting. Experiments show that WAT achieves state-of-the-art performance on online video benchmarks, including 77.7% accuracy on StreamingBench and 55.2% on OVO-Bench, outperforming existing open-source online Video LLMs while operating at real-time frame rates.
Quant Experts: Token-aware Adaptive Error Reconstruction with Mixture of Experts for Large Vision-Language Models Quantization
Feb 27, 2026Post-Training Quantization (PTQ) has emerged as an effective technique for alleviating the substantial computational and memory overheads of Vision-Language Models (VLMs) by compressing both weights and activations without retraining the full model. Existing PTQ methods primarily rely on static identification and global compensation of sensitive or outlier channels, yet they often overlook the distributional differences of these important channels across inputs, leading to unsatisfactory quantization. In this work, we observe that the distributions and occurrence frequencies of important channels vary significantly both across modalities and among tokens, even within the same modality. Accordingly, we propose \textbf{Quant Experts (QE)}, a token-aware adaptive error compensation with mixture-of-experts for VLMs quantization. QE divides the important channels into token-independent and token-dependent groups. For the former, a shared expert is designed for most tokens to compensate for global quantization error using a low-rank adapter. For the latter, routed experts including multiple routed low-rank adapters are elaborated to compensate for local quantization error related to specific tokens. Extensive experiments demonstrate that QE consistently enhances task accuracy across various quantization settings and model scales, ranging from 2B to 70B parameters, while maintaining performance comparable to full-precision models.
Expand Your SCOPE: Semantic Cognition over Potential-Based Exploration for Embodied Visual Navigation
Nov 12, 2025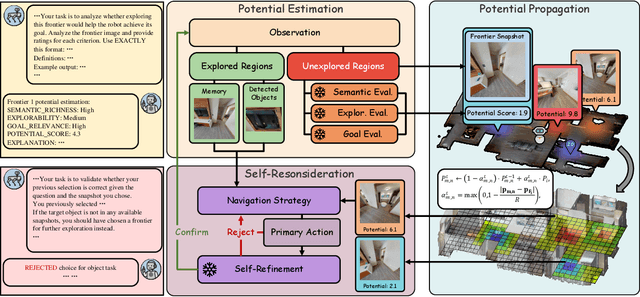
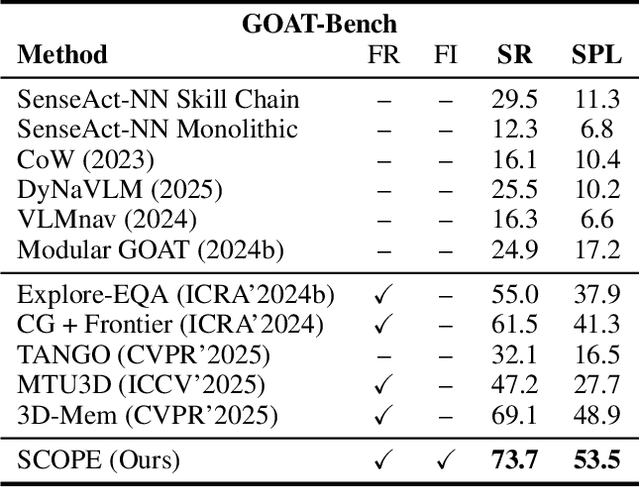
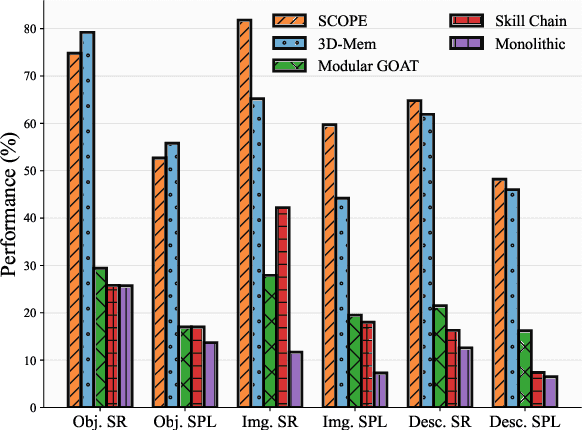
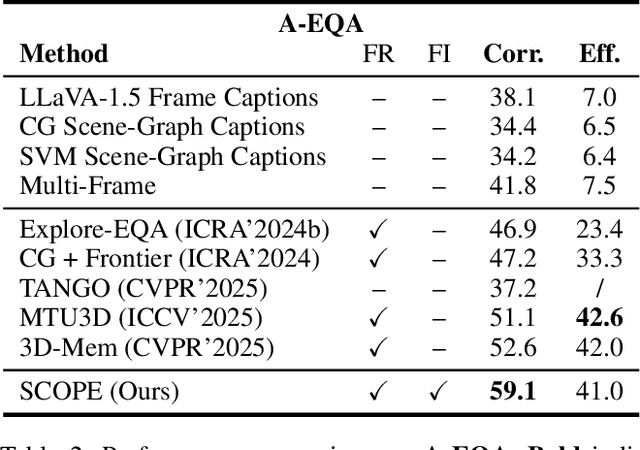
Embodied visual navigation remains a challenging task, as agents must explore unknown environments with limited knowledge. Existing zero-shot studies have shown that incorporating memory mechanisms to support goal-directed behavior can improve long-horizon planning performance. However, they overlook visual frontier boundaries, which fundamentally dictate future trajectories and observations, and fall short of inferring the relationship between partial visual observations and navigation goals. In this paper, we propose Semantic Cognition Over Potential-based Exploration (SCOPE), a zero-shot framework that explicitly leverages frontier information to drive potential-based exploration, enabling more informed and goal-relevant decisions. SCOPE estimates exploration potential with a Vision-Language Model and organizes it into a spatio-temporal potential graph, capturing boundary dynamics to support long-horizon planning. In addition, SCOPE incorporates a self-reconsideration mechanism that revisits and refines prior decisions, enhancing reliability and reducing overconfident errors. Experimental results on two diverse embodied navigation tasks show that SCOPE outperforms state-of-the-art baselines by 4.6\% in accuracy. Further analysis demonstrates that its core components lead to improved calibration, stronger generalization, and higher decision quality.
TensorAR: Refinement is All You Need in Autoregressive Image Generation
May 22, 2025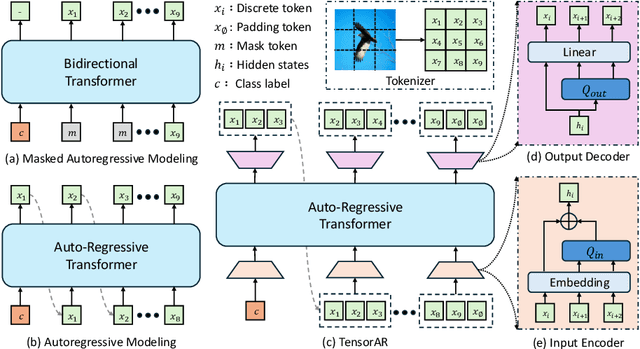

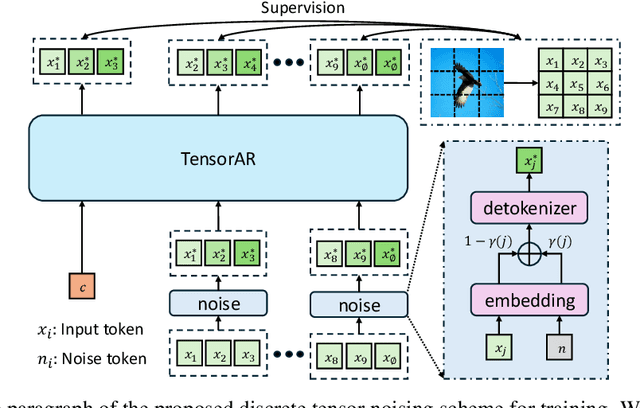

Autoregressive (AR) image generators offer a language-model-friendly approach to image generation by predicting discrete image tokens in a causal sequence. However, unlike diffusion models, AR models lack a mechanism to refine previous predictions, limiting their generation quality. In this paper, we introduce TensorAR, a new AR paradigm that reformulates image generation from next-token prediction to next-tensor prediction. By generating overlapping windows of image patches (tensors) in a sliding fashion, TensorAR enables iterative refinement of previously generated content. To prevent information leakage during training, we propose a discrete tensor noising scheme, which perturbs input tokens via codebook-indexed noise. TensorAR is implemented as a plug-and-play module compatible with existing AR models. Extensive experiments on LlamaGEN, Open-MAGVIT2, and RAR demonstrate that TensorAR significantly improves the generation performance of autoregressive models.
Neuc-MDS: Non-Euclidean Multidimensional Scaling Through Bilinear Forms
Nov 16, 2024We introduce Non-Euclidean-MDS (Neuc-MDS), an extension of classical Multidimensional Scaling (MDS) that accommodates non-Euclidean and non-metric inputs. The main idea is to generalize the standard inner product to symmetric bilinear forms to utilize the negative eigenvalues of dissimilarity Gram matrices. Neuc-MDS efficiently optimizes the choice of (both positive and negative) eigenvalues of the dissimilarity Gram matrix to reduce STRESS, the sum of squared pairwise error. We provide an in-depth error analysis and proofs of the optimality in minimizing lower bounds of STRESS. We demonstrate Neuc-MDS's ability to address limitations of classical MDS raised by prior research, and test it on various synthetic and real-world datasets in comparison with both linear and non-linear dimension reduction methods.
Latent Feature and Attention Dual Erasure Attack against Multi-View Diffusion Models for 3D Assets Protection
Aug 21, 2024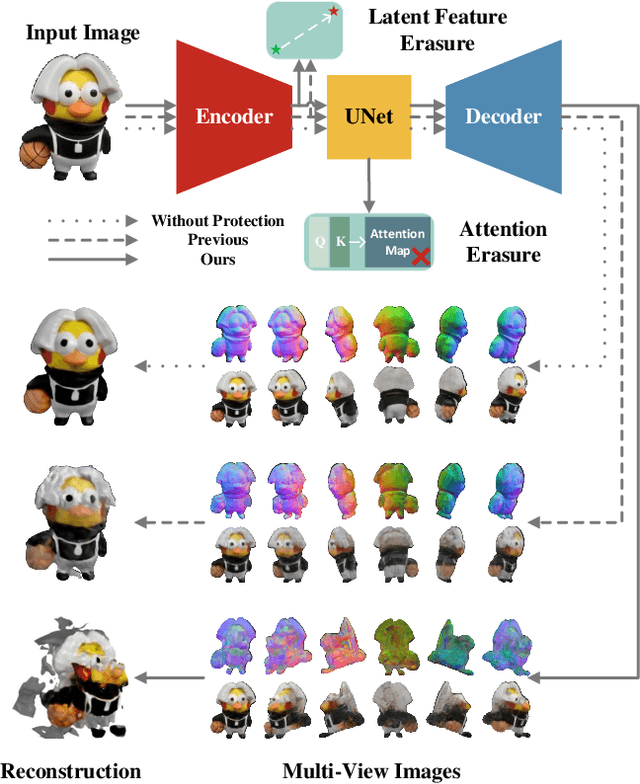
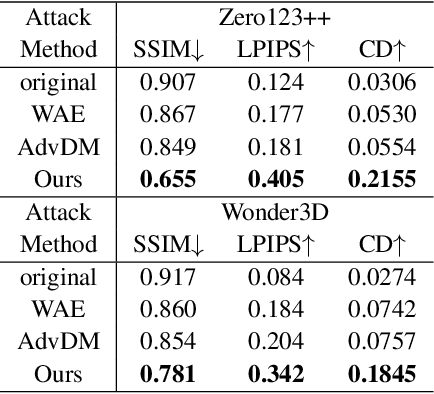
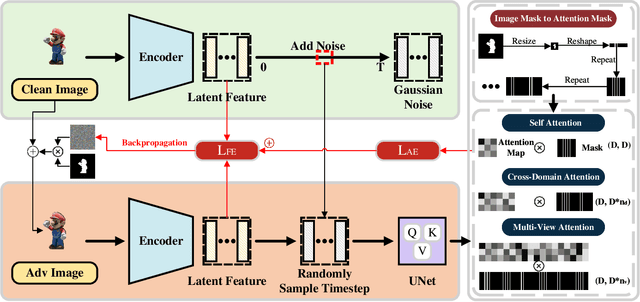
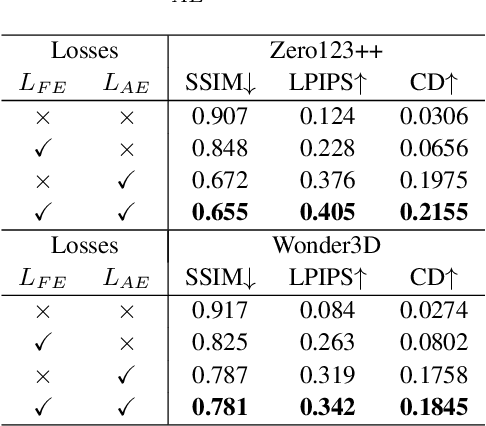
Multi-View Diffusion Models (MVDMs) enable remarkable improvements in the field of 3D geometric reconstruction, but the issue regarding intellectual property has received increasing attention due to unauthorized imitation. Recently, some works have utilized adversarial attacks to protect copyright. However, all these works focus on single-image generation tasks which only need to consider the inner feature of images. Previous methods are inefficient in attacking MVDMs because they lack the consideration of disrupting the geometric and visual consistency among the generated multi-view images. This paper is the first to address the intellectual property infringement issue arising from MVDMs. Accordingly, we propose a novel latent feature and attention dual erasure attack to disrupt the distribution of latent feature and the consistency across the generated images from multi-view and multi-domain simultaneously. The experiments conducted on SOTA MVDMs indicate that our approach achieves superior performances in terms of attack effectiveness, transferability, and robustness against defense methods. Therefore, this paper provides an efficient solution to protect 3D assets from MVDMs-based 3D geometry reconstruction.
Activating Wider Areas in Image Super-Resolution
Mar 13, 2024

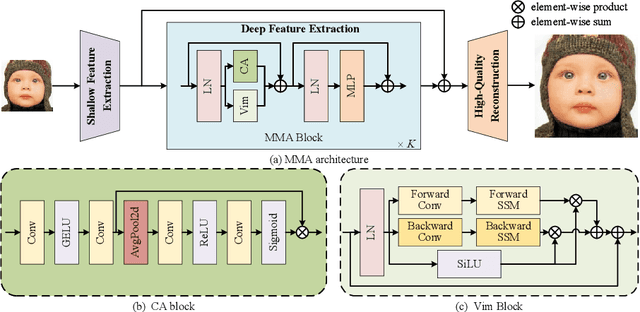

The prevalence of convolution neural networks (CNNs) and vision transformers (ViTs) has markedly revolutionized the area of single-image super-resolution (SISR). To further boost the SR performances, several techniques, such as residual learning and attention mechanism, are introduced, which can be largely attributed to a wider range of activated area, that is, the input pixels that strongly influence the SR results. However, the possibility of further improving SR performance through another versatile vision backbone remains an unresolved challenge. To address this issue, in this paper, we unleash the representation potential of the modern state space model, i.e., Vision Mamba (Vim), in the context of SISR. Specifically, we present three recipes for better utilization of Vim-based models: 1) Integration into a MetaFormer-style block; 2) Pre-training on a larger and broader dataset; 3) Employing complementary attention mechanism, upon which we introduce the MMA. The resulting network MMA is capable of finding the most relevant and representative input pixels to reconstruct the corresponding high-resolution images. Comprehensive experimental analysis reveals that MMA not only achieves competitive or even superior performance compared to state-of-the-art SISR methods but also maintains relatively low memory and computational overheads (e.g., +0.5 dB PSNR elevation on Manga109 dataset with 19.8 M parameters at the scale of 2). Furthermore, MMA proves its versatility in lightweight SR applications. Through this work, we aim to illuminate the potential applications of state space models in the broader realm of image processing rather than SISR, encouraging further exploration in this innovative direction.
Exploring Hardware Friendly Bottleneck Architecture in CNN for Embedded Computing Systems
Mar 11, 2024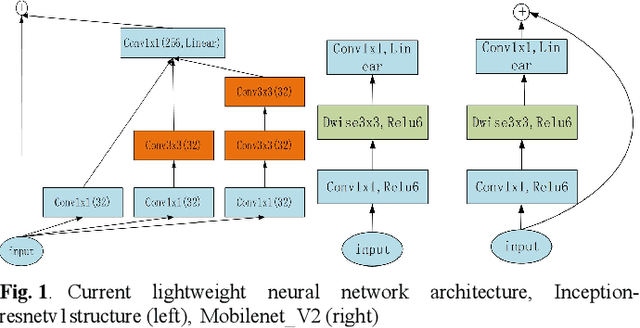

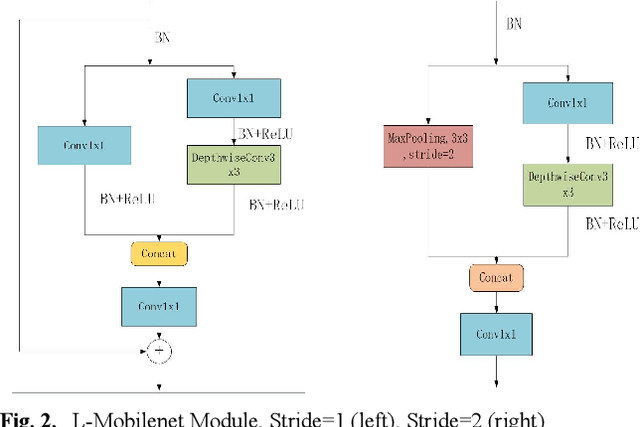
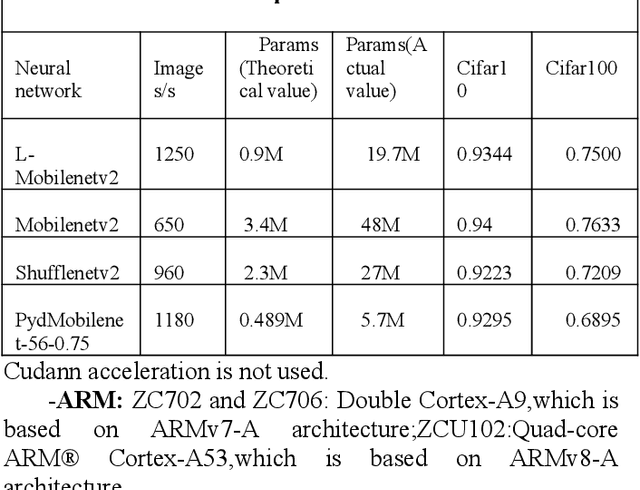
In this paper, we explore how to design lightweight CNN architecture for embedded computing systems. We propose L-Mobilenet model for ZYNQ based hardware platform. L-Mobilenet can adapt well to the hardware computing and accelerating, and its network structure is inspired by the state-of-the-art work of Inception-ResnetV1 and MobilenetV2, which can effectively reduce parameters and delay while maintaining the accuracy of inference. We deploy our L-Mobilenet model to ZYNQ embedded platform for fully evaluating the performance of our design. By measuring in cifar10 and cifar100 datasets, L-Mobilenet model is able to gain 3x speed up and 3.7x fewer parameters than MobileNetV2 while maintaining a similar accuracy. It also can obtain 2x speed up and 1.5x fewer parameters than ShufflenetV2 while maintaining the same accuracy. Experiments show that our network model can obtain better performance because of the special considerations for hardware accelerating and software-hardware co-design strategies in our L-Mobilenet bottleneck architecture.
Networked Multiagent Safe Reinforcement Learning for Low-carbon Demand Management in Distribution Network
Nov 27, 2023
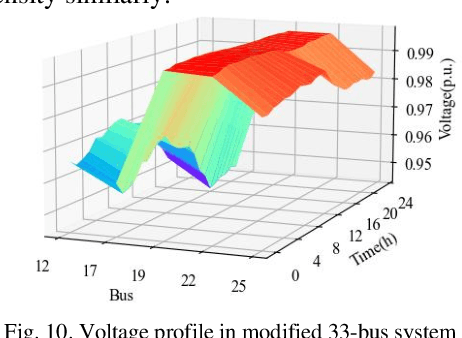


This paper proposes a multiagent based bi-level operation framework for the low-carbon demand management in distribution networks considering the carbon emission allowance on the demand side. In the upper level, the aggregate load agents optimize the control signals for various types of loads to maximize the profits; in the lower level, the distribution network operator makes optimal dispatching decisions to minimize the operational costs and calculates the distribution locational marginal price and carbon intensity. The distributed flexible load agent has only incomplete information of the distribution network and cooperates with other agents using networked communication. Finally, the problem is formulated into a networked multi-agent constrained Markov decision process, which is solved using a safe reinforcement learning algorithm called consensus multi-agent constrained policy optimization considering the carbon emission allowance for each agent. Case studies with the IEEE 33-bus and 123-bus distribution network systems demonstrate the effectiveness of the proposed approach, in terms of satisfying the carbon emission constraint on demand side, ensuring the safe operation of the distribution network and preserving privacy of both sides.
Meta-Adapter: An Online Few-shot Learner for Vision-Language Model
Nov 07, 2023



The contrastive vision-language pre-training, known as CLIP, demonstrates remarkable potential in perceiving open-world visual concepts, enabling effective zero-shot image recognition. Nevertheless, few-shot learning methods based on CLIP typically require offline fine-tuning of the parameters on few-shot samples, resulting in longer inference time and the risk of over-fitting in certain domains. To tackle these challenges, we propose the Meta-Adapter, a lightweight residual-style adapter, to refine the CLIP features guided by the few-shot samples in an online manner. With a few training samples, our method can enable effective few-shot learning capabilities and generalize to unseen data or tasks without additional fine-tuning, achieving competitive performance and high efficiency. Without bells and whistles, our approach outperforms the state-of-the-art online few-shot learning method by an average of 3.6\% on eight image classification datasets with higher inference speed. Furthermore, our model is simple and flexible, serving as a plug-and-play module directly applicable to downstream tasks. Without further fine-tuning, Meta-Adapter obtains notable performance improvements in open-vocabulary object detection and segmentation tasks.