 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignCoder: Aligning Retrieval with Target Intent for Repository-Level Code Completion
Jan 27, 2026Repository-level code completion remains a challenging task for existing code large language models (code LLMs) due to their limited understanding of repository-specific context and domain knowledge. While retrieval-augmented generation (RAG) approaches have shown promise by retrieving relevant code snippets as cross-file context, they suffer from two fundamental problems: misalignment between the query and the target code in the retrieval process, and the inability of existing retrieval methods to effectively utilize the inference information. To address these challenges, we propose AlignCoder, a repository-level code completion framework that introduces a query enhancement mechanism and a reinforcement learning based retriever training method. Our approach generates multiple candidate completions to construct an enhanced query that bridges the semantic gap between the initial query and the target code. Additionally, we employ reinforcement learning to train an AlignRetriever that learns to leverage inference information in the enhanced query for more accurate retrieval. We evaluate AlignCoder on two widely-used benchmarks (CrossCodeEval and RepoEval) across five backbone code LLMs, demonstrating an 18.1% improvement in EM score compared to baselines on the CrossCodeEval benchmark. The results show that our framework achieves superior performance and exhibits high generalizability across various code LLMs and programming languages.
ShortCoder: Knowledge-Augmented Syntax Optimization for Token-Efficient Code Generation
Jan 14, 2026Code generation tasks aim to automate the conversion of user requirements into executable code, significantly reducing manual development efforts and enhancing software productivity. The emergence of large language models (LLMs) has significantly advanced code generation, though their efficiency is still impacted by certain inherent architectural constraints. Each token generation necessitates a complete inference pass, requiring persistent retention of contextual information in memory and escalating resource consumption. While existing research prioritizes inference-phase optimizations such as prompt compression and model quantization, the generation phase remains underexplored. To tackle these challenges, we propose a knowledge-infused framework named ShortCoder, which optimizes code generation efficiency while preserving semantic equivalence and readability. In particular, we introduce: (1) ten syntax-level simplification rules for Python, derived from AST-preserving transformations, achieving 18.1% token reduction without functional compromise; (2) a hybrid data synthesis pipeline integrating rule-based rewriting with LLM-guided refinement, producing ShorterCodeBench, a corpus of validated tuples of original code and simplified code with semantic consistency; (3) a fine-tuning strategy that injects conciseness awareness into the base LLMs. Extensive experimental results demonstrate that ShortCoder consistently outperforms state-of-the-art methods on HumanEval, achieving an improvement of 18.1%-37.8% in generation efficiency over previous methods while ensuring the performance of code generation.
UCoder: Unsupervised Code Generation by Internal Probing of Large Language Models
Dec 19, 2025
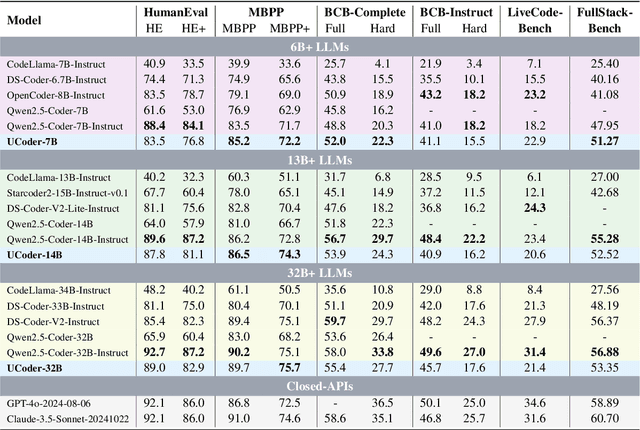
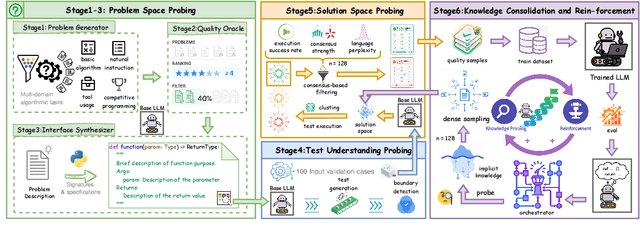
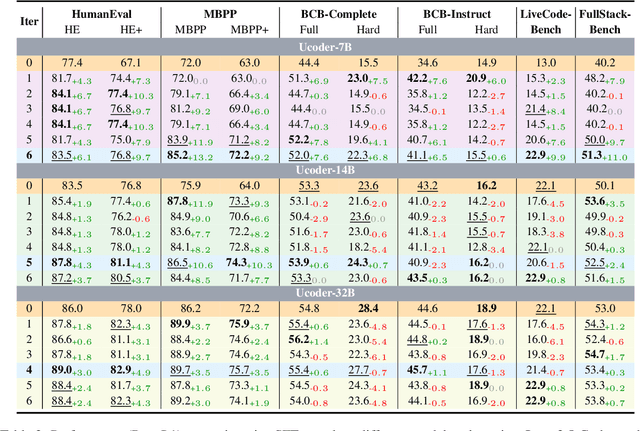
Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, their effectiveness heavily relies on supervised training with extensive labeled (e.g., question-answering pairs) or unlabeled datasets (e.g., code snippets), which are often expensive and difficult to obtain at scale. To address this limitation, this paper introduces a method IPC, an unsupervised framework that leverages Internal Probing of LLMs for Code generation without any external corpus, even unlabeled code snippets. We introduce the problem space probing, test understanding probing, solution space probing, and knowledge consolidation and reinforcement to probe the internal knowledge and confidence patterns existing in LLMs. Further, IPC identifies reliable code candidates through self-consistency mechanisms and representation-based quality estimation to train UCoder (coder with unsupervised learning). We validate the proposed approach across multiple code benchmarks, demonstrating that unsupervised methods can achieve competitive performance compared to supervised approaches while significantly reducing the dependency on labeled data and computational resources. Analytic experiments reveal that internal model states contain rich signals about code quality and correctness, and that properly harnessing these signals enables effective unsupervised learning for code generation tasks, opening new directions for training code LLMs in resource-constrained scenarios.
Towards an Understanding of Context Utilization in Code Intelligence
Apr 11, 2025Code intelligence is an emerging domain in software engineering, aiming to improve the effectiveness and efficiency of various code-related tasks. Recent research suggests that incorporating contextual information beyond the basic original task inputs (i.e., source code) can substantially enhance model performance. Such contextual signals may be obtained directly or indirectly from sources such as API documentation or intermediate representations like abstract syntax trees can significantly improve the effectiveness of code intelligence. Despite growing academic interest, there is a lack of systematic analysis of context in code intelligence. To address this gap, we conduct an extensive literature review of 146 relevant studies published between September 2007 and August 2024. Our investigation yields four main contributions. (1) A quantitative analysis of the research landscape, including publication trends, venues, and the explored domains; (2) A novel taxonomy of context types used in code intelligence; (3) A task-oriented analysis investigating context integration strategies across diverse code intelligence tasks; (4) A critical evaluation of evaluation methodologies for context-aware methods. Based on these findings, we identify fundamental challenges in context utilization in current code intelligence systems and propose a research roadmap that outlines key opportunities for future research.
How Well Do LLMs Generate Code for Different Application Domains? Benchmark and Evaluation
Dec 24, 2024



Recently, an increasing number of AI-driven programming assistants powered by code LLMs have been integrated into various real-world software development environments, significantly boosting developer productivity. However, existing code generation benchmarks primarily focus on general-purpose scenarios, leaving the code generation performance of LLMs for specific application domains largely unknown. In this paper, we introduce a new benchmark, MultiCodeBench, to fill this gap. MultiCodeBench comprises 2,400 programming tasks, covering 12 popular software development domains and 15 programming languages. Specifically, we perform in-depth research to identify these 12 application domains. Given that each domain may involve multiple technical frameworks, and that different frameworks present distinct challenges in the coding process, we categorize the commonly used frameworks and platforms within each domain. We then sample programming problems from GitHub repositories related to these subdomains. To ensure the quality of the tasks and mitigate data leakage issues, we invite annotators to rewrite the docstrings for each task in MultiCodeBench. Additionally, we build a static analysis-based dependency parsing tool to extract the dependencies in the ground truth for each task, enabling deeper performance analysis. Through extensive experiments on MultiCodeBench with eleven representative mainstream LLMs, we reveal the code generation performance of the LLMs across different application domains, providing practical insights for developers in downstream fields when selecting LLMs. Furthermore, we analyze the reasons behind the models' failures in completing software application development tasks, offering guidance for model developers to enhance domain-specific code generation capabilities.
Agents in Software Engineering: Survey, Landscape, and Vision
Sep 13, 2024



In recent years, Large Language Models (LLMs) have achieved remarkable success and have been widely used in various downstream tasks, especially in the tasks of the software engineering (SE) field. We find that many studies combining LLMs with SE have employed the concept of agents either explicitly or implicitly. However, there is a lack of an in-depth survey to sort out the development context of existing works, analyze how existing works combine the LLM-based agent technologies to optimize various tasks, and clarify the framework of LLM-based agents in SE. In this paper, we conduct the first survey of the studies on combining LLM-based agents with SE and present a framework of LLM-based agents in SE which includes three key modules: perception, memory, and action. We also summarize the current challenges in combining the two fields and propose future opportunities in response to existing challenges. We maintain a GitHub repository of the related papers at: https://github.com/DeepSoftwareAnalytics/Awesome-Agent4SE.
SoTaNa: The Open-Source Software Development Assistant
Aug 25, 2023



Software development plays a crucial role in driving innovation and efficiency across modern societies. To meet the demands of this dynamic field, there is a growing need for an effective software development assistant. However, existing large language models represented by ChatGPT suffer from limited accessibility, including training data and model weights. Although other large open-source models like LLaMA have shown promise, they still struggle with understanding human intent. In this paper, we present SoTaNa, an open-source software development assistant. SoTaNa utilizes ChatGPT to generate high-quality instruction-based data for the domain of software engineering and employs a parameter-efficient fine-tuning approach to enhance the open-source foundation model, LLaMA. We evaluate the effectiveness of \our{} in answering Stack Overflow questions and demonstrate its capabilities. Additionally, we discuss its capabilities in code summarization and generation, as well as the impact of varying the volume of generated data on model performance. Notably, SoTaNa can run on a single GPU, making it accessible to a broader range of researchers. Our code, model weights, and data are public at \url{https://github.com/DeepSoftwareAnalytics/SoTaNa}.
Towards Efficient Fine-tuning of Pre-trained Code Models: An Experimental Study and Beyond
Apr 11, 2023



Recently, fine-tuning pre-trained code models such as CodeBERT on downstream tasks has achieved great success in many software testing and analysis tasks. While effective and prevalent, fine-tuning the pre-trained parameters incurs a large computational cost. In this paper, we conduct an extensive experimental study to explore what happens to layer-wise pre-trained representations and their encoded code knowledge during fine-tuning. We then propose efficient alternatives to fine-tune the large pre-trained code model based on the above findings. Our experimental study shows that (1) lexical, syntactic and structural properties of source code are encoded in the lower, intermediate, and higher layers, respectively, while the semantic property spans across the entire model. (2) The process of fine-tuning preserves most of the code properties. Specifically, the basic code properties captured by lower and intermediate layers are still preserved during fine-tuning. Furthermore, we find that only the representations of the top two layers change most during fine-tuning for various downstream tasks. (3) Based on the above findings, we propose Telly to efficiently fine-tune pre-trained code models via layer freezing. The extensive experimental results on five various downstream tasks demonstrate that training parameters and the corresponding time cost are greatly reduced, while performances are similar or better. Replication package including source code, datasets, and online Appendix is available at: \url{https://github.com/DeepSoftwareAnalytics/Telly}.
Enhancing Semantic Code Search with Multimodal Contrastive Learning and Soft Data Augmentation
Apr 08, 2022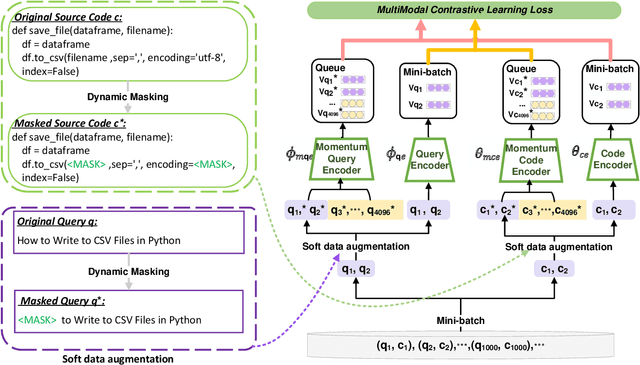
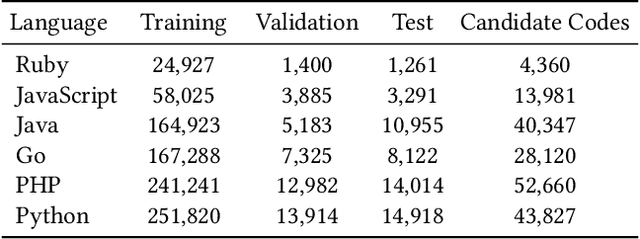
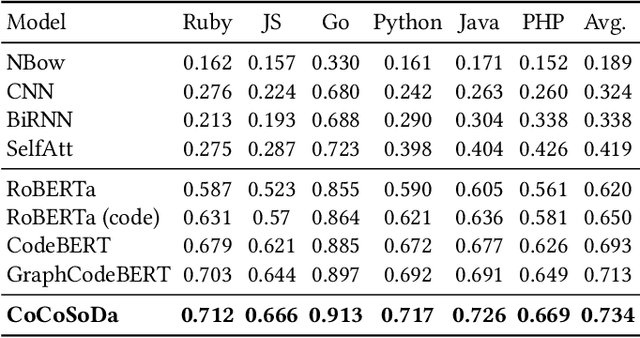
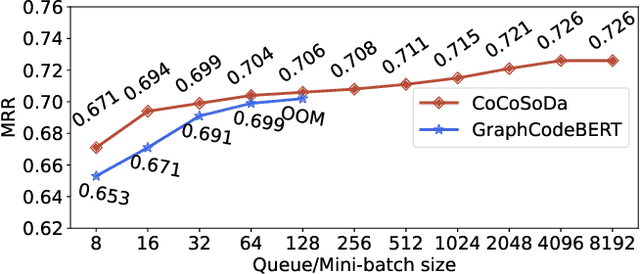
Code search aims to retrieve the most semantically relevant code snippet for a given natural language query. Recently, large-scale code pre-trained models such as CodeBERT and GraphCodeBERT learn generic representations of source code and have achieved substantial improvement on code search task. However, the high-quality sequence-level representations of code snippets have not been sufficiently explored. In this paper, we propose a new approach with multimodal contrastive learning and soft data augmentation for code search. Multimodal contrastive learning is used to pull together the representations of code-query pairs and push apart the unpaired code snippets and queries. Moreover, data augmentation is critical in contrastive learning for learning high-quality representations. However, only semantic-preserving augmentations for source code are considered in existing work. In this work, we propose to do soft data augmentation by dynamically masking and replacing some tokens in code sequences to generate code snippets that are similar but not necessarily semantic-preserving as positive samples for paired queries. We conduct extensive experiments to evaluate the effectiveness of our approach on a large-scale dataset with six programming languages. The experimental results show that our approach significantly outperforms the state-of-the-art methods. We also adapt our techniques to several pre-trained models such as RoBERTa and CodeBERT, and significantly boost their performance on the code search task.
On the Evaluation of Commit Message Generation Models: An Experimental Study
Jul 26, 2021



Commit messages are natural language descriptions of code changes, which are important for program understanding and maintenance. However, writing commit messages manually is time-consuming and laborious, especially when the code is updated frequently. Various approaches utilizing generation or retrieval techniques have been proposed to automatically generate commit messages. To achieve a better understanding of how the existing approaches perform in solving this problem, this paper conducts a systematic and in-depth analysis of the state-of-the-art models and datasets. We find that: (1) Different variants of the BLEU metric are used in previous works, which affects the evaluation and understanding of existing methods. (2) Most existing datasets are crawled only from Java repositories while repositories in other programming languages are not sufficiently explored. (3) Dataset splitting strategies can influence the performance of existing models by a large margin. Some models show better performance when the datasets are split by commit, while other models perform better when the datasets are split by timestamp or by project. Based on our findings, we conduct a human evaluation and find the BLEU metric that best correlates with the human scores for the task. We also collect a large-scale, information-rich, and multi-language commit message dataset MCMD and evaluate existing models on this dataset. Furthermore, we conduct extensive experiments under different dataset splitting strategies and suggest the suitable models under different scenarios. Based on the experimental results and findings, we provide feasible suggestions for comprehensively evaluating commit message generation models and discuss possible future research directions. We believe this work can help practitioners and researchers better evaluate and select models for automatic commit message generation.