 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBK-GNN: Gated Bi-Kernel Graph Neural Networks for Modeling Both Homophily and Heterophily
Oct 29, 2021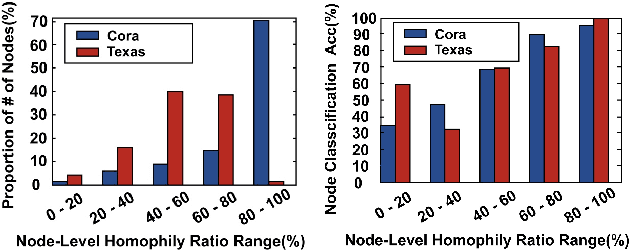
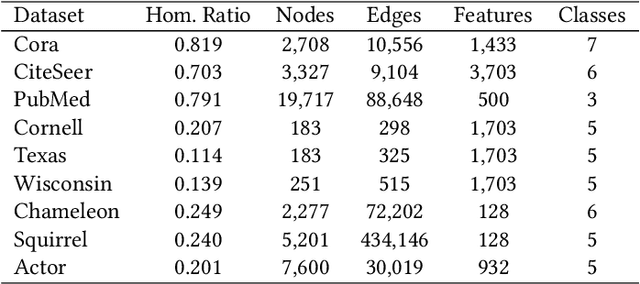
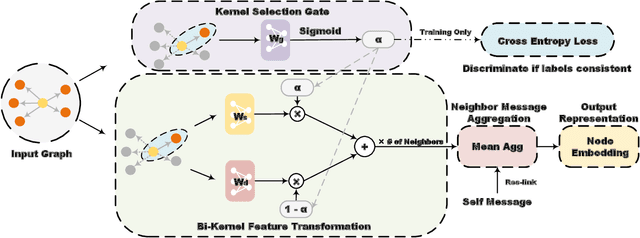
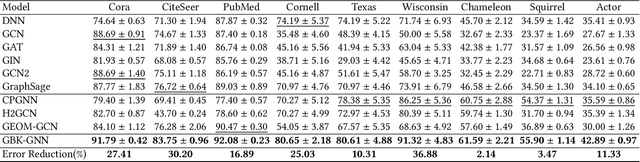
Graph Neural Networks (GNNs) are widely used on a variety of graph-based machine learning tasks. For node-level tasks, GNNs have strong power to model the homophily property of graphs (i.e., connected nodes are more similar) while their ability to capture heterophily property is often doubtful. This is partially caused by the design of the feature transformation with the same kernel for the nodes in the same hop and the followed aggregation operator. One kernel cannot model the similarity and the dissimilarity (i.e., the positive and negative correlation) between node features simultaneously even though we use attention mechanisms like Graph Attention Network (GAT), since the weight calculated by attention is always a positive value. In this paper, we propose a novel GNN model based on a bi-kernel feature transformation and a selection gate. Two kernels capture homophily and heterophily information respectively, and the gate is introduced to select which kernel we should use for the given node pairs. We conduct extensive experiments on various datasets with different homophily-heterophily properties. The experimental results show consistent and significant improvements against state-of-the-art GNN methods.
Is a Single Model Enough? MuCoS: A Multi-Model Ensemble Learning for Semantic Code Search
Jul 13, 2021
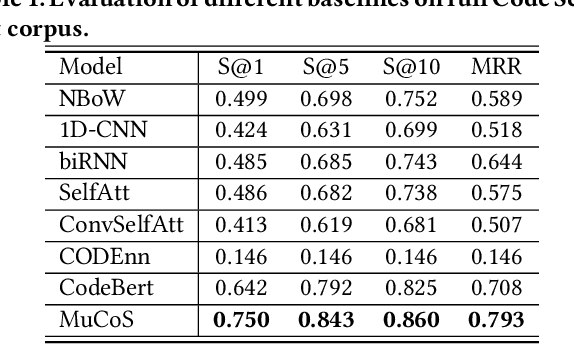

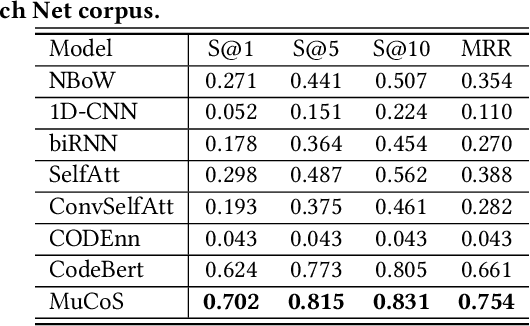
Recently, deep learning methods have become mainstream in code search since they do better at capturing semantic correlations between code snippets and search queries and have promising performance. However, code snippets have diverse information from different dimensions, such as business logic, specific algorithm, and hardware communication, so it is hard for a single code representation module to cover all the perspectives. On the other hand, as a specific query may focus on one or several perspectives, it is difficult for a single query representation module to represent different user intents. In this paper, we propose MuCoS, a multi-model ensemble learning architecture for semantic code search. It combines several individual learners, each of which emphasizes a specific perspective of code snippets. We train the individual learners on different datasets which contain different perspectives of code information, and we use a data augmentation strategy to get these different datasets. Then we ensemble the learners to capture comprehensive features of code snippets.