 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Semantic Code Search with Multimodal Contrastive Learning and Soft Data Augmentation
Paper and Code
Apr 08, 2022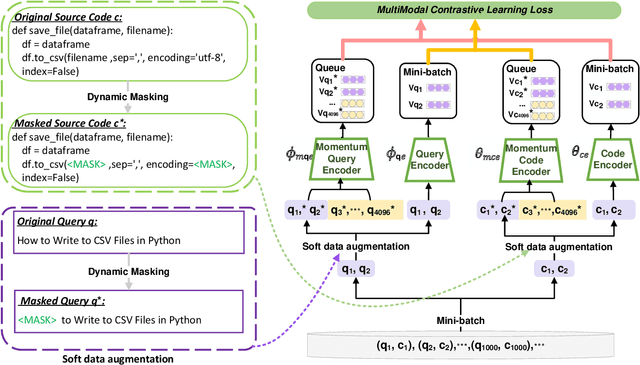
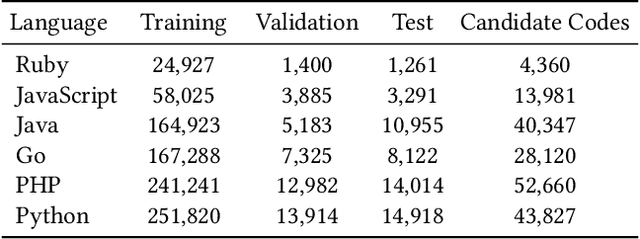
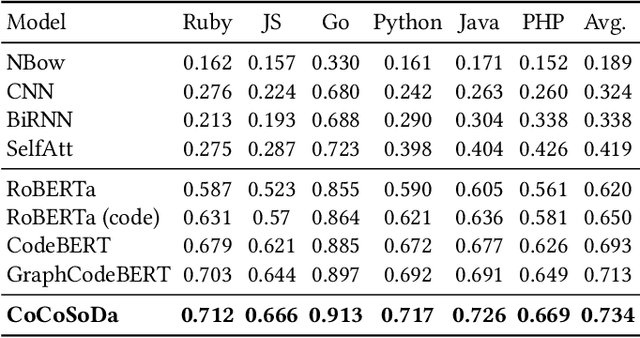
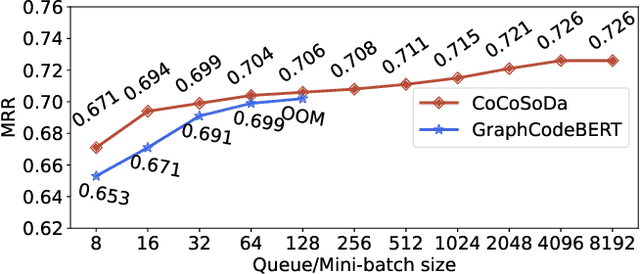
Code search aims to retrieve the most semantically relevant code snippet for a given natural language query. Recently, large-scale code pre-trained models such as CodeBERT and GraphCodeBERT learn generic representations of source code and have achieved substantial improvement on code search task. However, the high-quality sequence-level representations of code snippets have not been sufficiently explored. In this paper, we propose a new approach with multimodal contrastive learning and soft data augmentation for code search. Multimodal contrastive learning is used to pull together the representations of code-query pairs and push apart the unpaired code snippets and queries. Moreover, data augmentation is critical in contrastive learning for learning high-quality representations. However, only semantic-preserving augmentations for source code are considered in existing work. In this work, we propose to do soft data augmentation by dynamically masking and replacing some tokens in code sequences to generate code snippets that are similar but not necessarily semantic-preserving as positive samples for paired queries. We conduct extensive experiments to evaluate the effectiveness of our approach on a large-scale dataset with six programming languages. The experimental results show that our approach significantly outperforms the state-of-the-art methods. We also adapt our techniques to several pre-trained models such as RoBERTa and CodeBERT, and significantly boost their performance on the code search task.