 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivating Wider Areas in Image Super-Resolution
Paper and Code
Mar 13, 2024

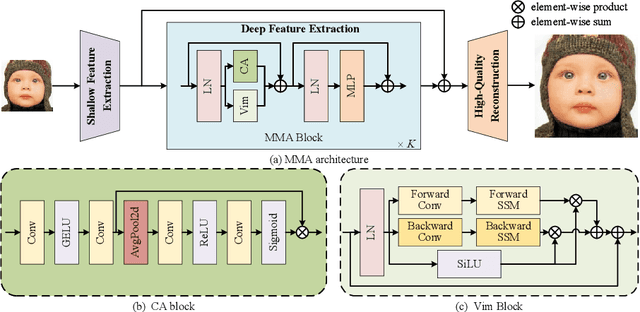

The prevalence of convolution neural networks (CNNs) and vision transformers (ViTs) has markedly revolutionized the area of single-image super-resolution (SISR). To further boost the SR performances, several techniques, such as residual learning and attention mechanism, are introduced, which can be largely attributed to a wider range of activated area, that is, the input pixels that strongly influence the SR results. However, the possibility of further improving SR performance through another versatile vision backbone remains an unresolved challenge. To address this issue, in this paper, we unleash the representation potential of the modern state space model, i.e., Vision Mamba (Vim), in the context of SISR. Specifically, we present three recipes for better utilization of Vim-based models: 1) Integration into a MetaFormer-style block; 2) Pre-training on a larger and broader dataset; 3) Employing complementary attention mechanism, upon which we introduce the MMA. The resulting network MMA is capable of finding the most relevant and representative input pixels to reconstruct the corresponding high-resolution images. Comprehensive experimental analysis reveals that MMA not only achieves competitive or even superior performance compared to state-of-the-art SISR methods but also maintains relatively low memory and computational overheads (e.g., +0.5 dB PSNR elevation on Manga109 dataset with 19.8 M parameters at the scale of 2). Furthermore, MMA proves its versatility in lightweight SR applications. Through this work, we aim to illuminate the potential applications of state space models in the broader realm of image processing rather than SISR, encouraging further exploration in this innovative direction.