 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQHyer: Q-conditioned Hybrid Attention-mamba Transformer for Offline Goal-conditioned RL
May 03, 2026Offline goal-conditioned RL (GCRL) learns goal-reaching policies from static datasets, but real-world datasets are often partially observable and history-dependent, exhibiting a mix of Markovian and non-Markovian that violate standard RL assumptions. History-aware sequence models such as Decision Transformer (DT) are a natural fit for long-term dependency modeling, yet pure attention is inefficient and brittle when handling local Markovian structure and long-range context simultaneously. Although recent hybrid architectures (e.g., LSDT) introduce local extractors to improve local dependencies modeling, the fixed-window extraction cannot adapt its effective memory to varying dependency lengths in temporally heterogeneous settings, often truncating long-range context rather than compressing its content adaptively. Moreover, sequential offline GCRL faces a key bottleneck: under sparse rewards, return-to-go (RTG) becomes non-discriminative across sub-trajectories, providing little guidance signal for stitching goal-reaching behaviors from diverse demonstrations. To address these, we propose \textbf{QHyer}, which replaces RTG with a flow-parameterized, state-conditioned goal-reaching Q-estimator to support stitching across demonstrations, and introduces a gated Hybrid Attention-Mamba backbone that performs content-adaptive history compression while preserving local dynamics. Extensive experiments demonstrate that \textbf{QHyer} achieves state-of-the-art performance on both non-Markovian and Markovian datasets, validating its effectiveness for diverse scenarios.
GCHR : Goal-Conditioned Hindsight Regularization for Sample-Efficient Reinforcement Learning
Aug 08, 2025



Goal-conditioned reinforcement learning (GCRL) with sparse rewards remains a fundamental challenge in reinforcement learning. While hindsight experience replay (HER) has shown promise by relabeling collected trajectories with achieved goals, we argue that trajectory relabeling alone does not fully exploit the available experiences in off-policy GCRL methods, resulting in limited sample efficiency. In this paper, we propose Hindsight Goal-conditioned Regularization (HGR), a technique that generates action regularization priors based on hindsight goals. When combined with hindsight self-imitation regularization (HSR), our approach enables off-policy RL algorithms to maximize experience utilization. Compared to existing GCRL methods that employ HER and self-imitation techniques, our hindsight regularizations achieve substantially more efficient sample reuse and the best performances, which we empirically demonstrate on a suite of navigation and manipulation tasks.
MGDA: Model-based Goal Data Augmentation for Offline Goal-conditioned Weighted Supervised Learning
Dec 16, 2024



Recently, a state-of-the-art family of algorithms, known as Goal-Conditioned Weighted Supervised Learning (GCWSL) methods, has been introduced to tackle challenges in offline goal-conditioned reinforcement learning (RL). GCWSL optimizes a lower bound of the goal-conditioned RL objective and has demonstrated outstanding performance across diverse goal-reaching tasks, providing a simple, effective, and stable solution. However, prior research has identified a critical limitation of GCWSL: the lack of trajectory stitching capabilities. To address this, goal data augmentation strategies have been proposed to enhance these methods. Nevertheless, existing techniques often struggle to sample suitable augmented goals for GCWSL effectively. In this paper, we establish unified principles for goal data augmentation, focusing on goal diversity, action optimality, and goal reachability. Based on these principles, we propose a Model-based Goal Data Augmentation (MGDA) approach, which leverages a learned dynamics model to sample more suitable augmented goals. MGDA uniquely incorporates the local Lipschitz continuity assumption within the learned model to mitigate the impact of compounding errors. Empirical results show that MGDA significantly enhances the performance of GCWSL methods on both state-based and vision-based maze datasets, surpassing previous goal data augmentation techniques in improving stitching capabilities.
Q-WSL:Leveraging Dynamic Programming for Weighted Supervised Learning in Goal-conditioned RL
Oct 10, 2024

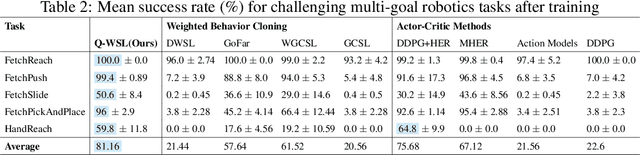
A novel class of advanced algorithms, termed Goal-Conditioned Weighted Supervised Learning (GCWSL), has recently emerged to tackle the challenges posed by sparse rewards in goal-conditioned reinforcement learning (RL). GCWSL consistently delivers strong performance across a diverse set of goal-reaching tasks due to its simplicity, effectiveness, and stability. However, GCWSL methods lack a crucial capability known as trajectory stitching, which is essential for learning optimal policies when faced with unseen skills during testing. This limitation becomes particularly pronounced when the replay buffer is predominantly filled with sub-optimal trajectories. In contrast, traditional TD-based RL methods, such as Q-learning, which utilize Dynamic Programming, do not face this issue but often experience instability due to the inherent difficulties in value function approximation. In this paper, we propose Q-learning Weighted Supervised Learning (Q-WSL), a novel framework designed to overcome the limitations of GCWSL by incorporating the strengths of Dynamic Programming found in Q-learning. Q-WSL leverages Dynamic Programming results to output the optimal action of (state, goal) pairs across different trajectories within the replay buffer. This approach synergizes the strengths of both Q-learning and GCWSL, effectively mitigating their respective weaknesses and enhancing overall performance. Empirical evaluations on challenging goal-reaching tasks demonstrate that Q-WSL surpasses other goal-conditioned approaches in terms of both performance and sample efficiency. Additionally, Q-WSL exhibits notable robustness in environments characterized by binary reward structures and environmental stochasticity.
Exploring Hardware Friendly Bottleneck Architecture in CNN for Embedded Computing Systems
Mar 11, 2024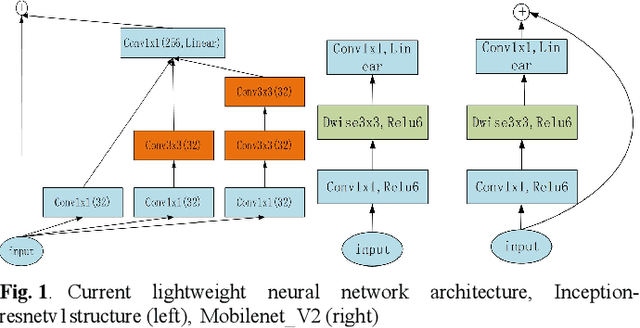

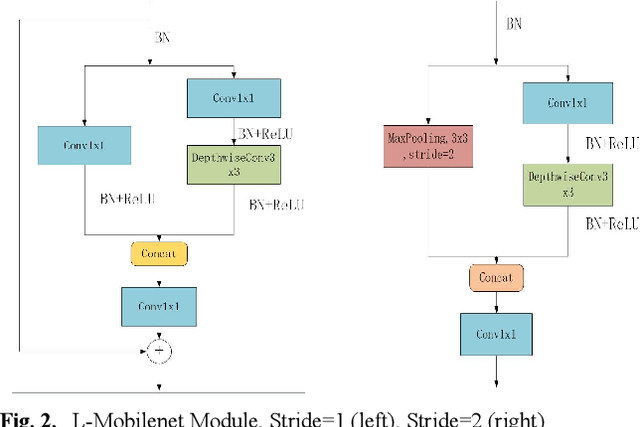
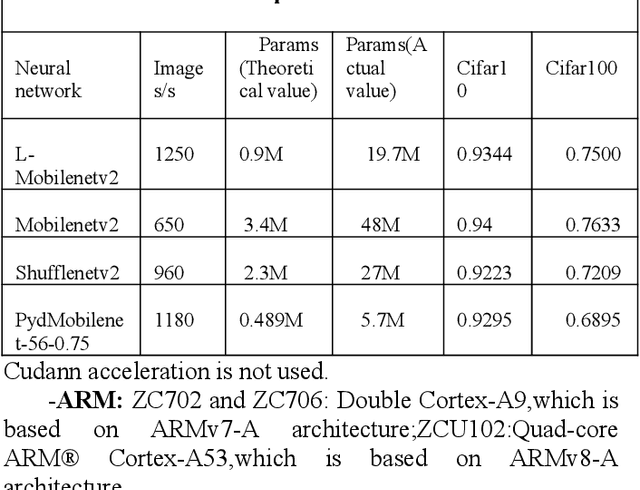
In this paper, we explore how to design lightweight CNN architecture for embedded computing systems. We propose L-Mobilenet model for ZYNQ based hardware platform. L-Mobilenet can adapt well to the hardware computing and accelerating, and its network structure is inspired by the state-of-the-art work of Inception-ResnetV1 and MobilenetV2, which can effectively reduce parameters and delay while maintaining the accuracy of inference. We deploy our L-Mobilenet model to ZYNQ embedded platform for fully evaluating the performance of our design. By measuring in cifar10 and cifar100 datasets, L-Mobilenet model is able to gain 3x speed up and 3.7x fewer parameters than MobileNetV2 while maintaining a similar accuracy. It also can obtain 2x speed up and 1.5x fewer parameters than ShufflenetV2 while maintaining the same accuracy. Experiments show that our network model can obtain better performance because of the special considerations for hardware accelerating and software-hardware co-design strategies in our L-Mobilenet bottleneck architecture.