 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-WSL:Leveraging Dynamic Programming for Weighted Supervised Learning in Goal-conditioned RL
Paper and Code
Oct 10, 2024

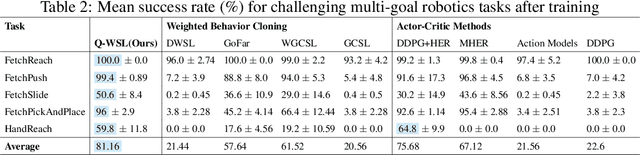
A novel class of advanced algorithms, termed Goal-Conditioned Weighted Supervised Learning (GCWSL), has recently emerged to tackle the challenges posed by sparse rewards in goal-conditioned reinforcement learning (RL). GCWSL consistently delivers strong performance across a diverse set of goal-reaching tasks due to its simplicity, effectiveness, and stability. However, GCWSL methods lack a crucial capability known as trajectory stitching, which is essential for learning optimal policies when faced with unseen skills during testing. This limitation becomes particularly pronounced when the replay buffer is predominantly filled with sub-optimal trajectories. In contrast, traditional TD-based RL methods, such as Q-learning, which utilize Dynamic Programming, do not face this issue but often experience instability due to the inherent difficulties in value function approximation. In this paper, we propose Q-learning Weighted Supervised Learning (Q-WSL), a novel framework designed to overcome the limitations of GCWSL by incorporating the strengths of Dynamic Programming found in Q-learning. Q-WSL leverages Dynamic Programming results to output the optimal action of (state, goal) pairs across different trajectories within the replay buffer. This approach synergizes the strengths of both Q-learning and GCWSL, effectively mitigating their respective weaknesses and enhancing overall performance. Empirical evaluations on challenging goal-reaching tasks demonstrate that Q-WSL surpasses other goal-conditioned approaches in terms of both performance and sample efficiency. Additionally, Q-WSL exhibits notable robustness in environments characterized by binary reward structures and environmental stochasticity.