 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualDiff: Dual-branch Diffusion Model for Autonomous Driving with Semantic Fusion
May 03, 2025Accurate and high-fidelity driving scene reconstruction relies on fully leveraging scene information as conditioning. However, existing approaches, which primarily use 3D bounding boxes and binary maps for foreground and background control, fall short in capturing the complexity of the scene and integrating multi-modal information. In this paper, we propose DualDiff, a dual-branch conditional diffusion model designed to enhance multi-view driving scene generation. We introduce Occupancy Ray Sampling (ORS), a semantic-rich 3D representation, alongside numerical driving scene representation, for comprehensive foreground and background control. To improve cross-modal information integration, we propose a Semantic Fusion Attention (SFA) mechanism that aligns and fuses features across modalities. Furthermore, we design a foreground-aware masked (FGM) loss to enhance the generation of tiny objects. DualDiff achieves state-of-the-art performance in FID score, as well as consistently better results in downstream BEV segmentation and 3D object detection tasks.
DualDiff+: Dual-Branch Diffusion for High-Fidelity Video Generation with Reward Guidance
Mar 05, 2025



Accurate and high-fidelity driving scene reconstruction demands the effective utilization of comprehensive scene information as conditional inputs. Existing methods predominantly rely on 3D bounding boxes and BEV road maps for foreground and background control, which fail to capture the full complexity of driving scenes and adequately integrate multimodal information. In this work, we present DualDiff, a dual-branch conditional diffusion model designed to enhance driving scene generation across multiple views and video sequences. Specifically, we introduce Occupancy Ray-shape Sampling (ORS) as a conditional input, offering rich foreground and background semantics alongside 3D spatial geometry to precisely control the generation of both elements. To improve the synthesis of fine-grained foreground objects, particularly complex and distant ones, we propose a Foreground-Aware Mask (FGM) denoising loss function. Additionally, we develop the Semantic Fusion Attention (SFA) mechanism to dynamically prioritize relevant information and suppress noise, enabling more effective multimodal fusion. Finally, to ensure high-quality image-to-video generation, we introduce the Reward-Guided Diffusion (RGD) framework, which maintains global consistency and semantic coherence in generated videos. Extensive experiments demonstrate that DualDiff achieves state-of-the-art (SOTA) performance across multiple datasets. On the NuScenes dataset, DualDiff reduces the FID score by 4.09% compared to the best baseline. In downstream tasks, such as BEV segmentation, our method improves vehicle mIoU by 4.50% and road mIoU by 1.70%, while in BEV 3D object detection, the foreground mAP increases by 1.46%. Code will be made available at https://github.com/yangzhaojason/DualDiff.
Exploring Hardware Friendly Bottleneck Architecture in CNN for Embedded Computing Systems
Mar 11, 2024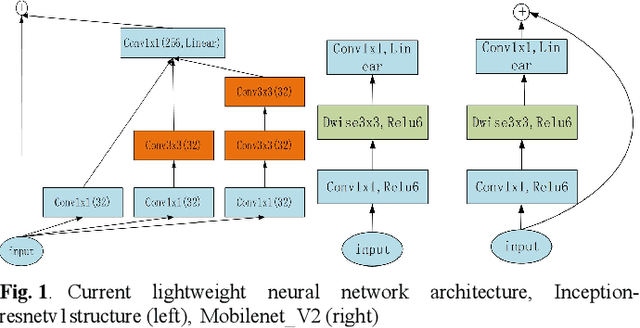

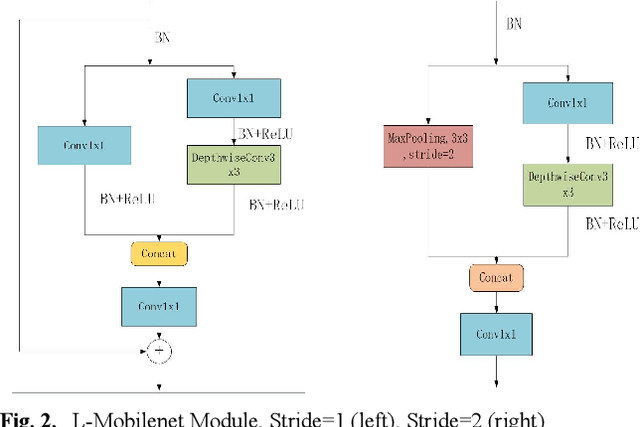
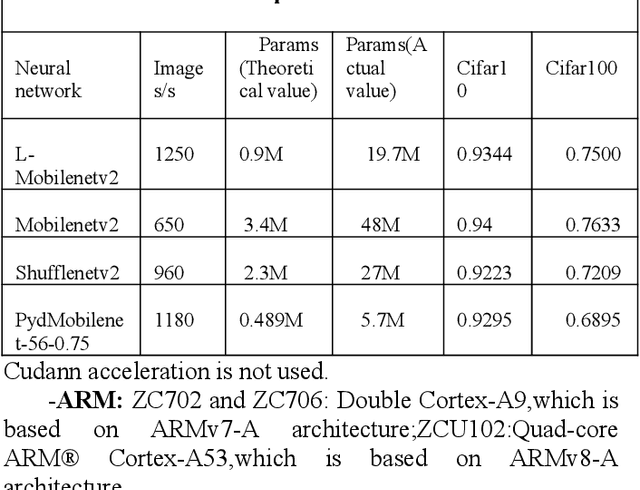
In this paper, we explore how to design lightweight CNN architecture for embedded computing systems. We propose L-Mobilenet model for ZYNQ based hardware platform. L-Mobilenet can adapt well to the hardware computing and accelerating, and its network structure is inspired by the state-of-the-art work of Inception-ResnetV1 and MobilenetV2, which can effectively reduce parameters and delay while maintaining the accuracy of inference. We deploy our L-Mobilenet model to ZYNQ embedded platform for fully evaluating the performance of our design. By measuring in cifar10 and cifar100 datasets, L-Mobilenet model is able to gain 3x speed up and 3.7x fewer parameters than MobileNetV2 while maintaining a similar accuracy. It also can obtain 2x speed up and 1.5x fewer parameters than ShufflenetV2 while maintaining the same accuracy. Experiments show that our network model can obtain better performance because of the special considerations for hardware accelerating and software-hardware co-design strategies in our L-Mobilenet bottleneck architecture.
IS-DARTS: Stabilizing DARTS through Precise Measurement on Candidate Importance
Dec 19, 2023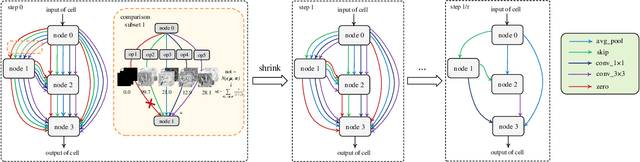
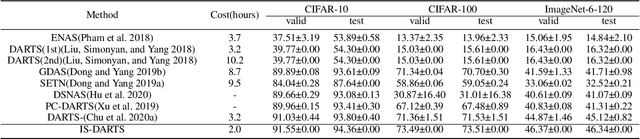
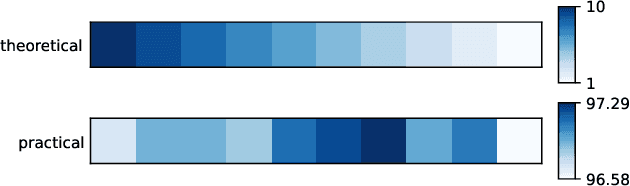
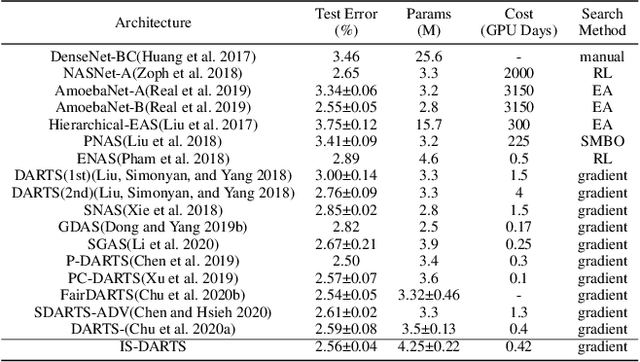
Among existing Neural Architecture Search methods, DARTS is known for its efficiency and simplicity. This approach applies continuous relaxation of network representation to construct a weight-sharing supernet and enables the identification of excellent subnets in just a few GPU days. However, performance collapse in DARTS results in deteriorating architectures filled with parameter-free operations and remains a great challenge to the robustness. To resolve this problem, we reveal that the fundamental reason is the biased estimation of the candidate importance in the search space through theoretical and experimental analysis, and more precisely select operations via information-based measurements. Furthermore, we demonstrate that the excessive concern over the supernet and inefficient utilization of data in bi-level optimization also account for suboptimal results. We adopt a more realistic objective focusing on the performance of subnets and simplify it with the help of the information-based measurements. Finally, we explain theoretically why progressively shrinking the width of the supernet is necessary and reduce the approximation error of optimal weights in DARTS. Our proposed method, named IS-DARTS, comprehensively improves DARTS and resolves the aforementioned problems. Extensive experiments on NAS-Bench-201 and DARTS-based search space demonstrate the effectiveness of IS-DARTS.