 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Guided Transformable Bottleneck Networks for Motion Retargeting
Jun 14, 2021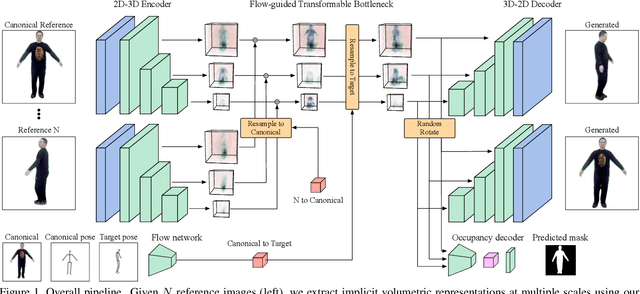


Human motion retargeting aims to transfer the motion of one person in a "driving" video or set of images to another person. Existing efforts leverage a long training video from each target person to train a subject-specific motion transfer model. However, the scalability of such methods is limited, as each model can only generate videos for the given target subject, and such training videos are labor-intensive to acquire and process. Few-shot motion transfer techniques, which only require one or a few images from a target, have recently drawn considerable attention. Methods addressing this task generally use either 2D or explicit 3D representations to transfer motion, and in doing so, sacrifice either accurate geometric modeling or the flexibility of an end-to-end learned representation. Inspired by the Transformable Bottleneck Network, which renders novel views and manipulations of rigid objects, we propose an approach based on an implicit volumetric representation of the image content, which can then be spatially manipulated using volumetric flow fields. We address the challenging question of how to aggregate information across different body poses, learning flow fields that allow for combining content from the appropriate regions of input images of highly non-rigid human subjects performing complex motions into a single implicit volumetric representation. This allows us to learn our 3D representation solely from videos of moving people. Armed with both 3D object understanding and end-to-end learned rendering, this categorically novel representation delivers state-of-the-art image generation quality, as shown by our quantitative and qualitative evaluations.
Motion Representations for Articulated Animation
Apr 22, 2021

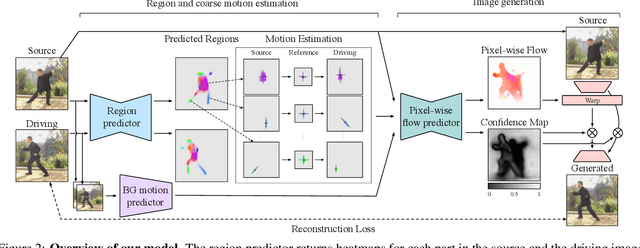

We propose novel motion representations for animating articulated objects consisting of distinct parts. In a completely unsupervised manner, our method identifies object parts, tracks them in a driving video, and infers their motions by considering their principal axes. In contrast to the previous keypoint-based works, our method extracts meaningful and consistent regions, describing locations, shape, and pose. The regions correspond to semantically relevant and distinct object parts, that are more easily detected in frames of the driving video. To force decoupling of foreground from background, we model non-object related global motion with an additional affine transformation. To facilitate animation and prevent the leakage of the shape of the driving object, we disentangle shape and pose of objects in the region space. Our model can animate a variety of objects, surpassing previous methods by a large margin on existing benchmarks. We present a challenging new benchmark with high-resolution videos and show that the improvement is particularly pronounced when articulated objects are considered, reaching 96.6% user preference vs. the state of the art.
Teachers Do More Than Teach: Compressing Image-to-Image Models
Mar 05, 2021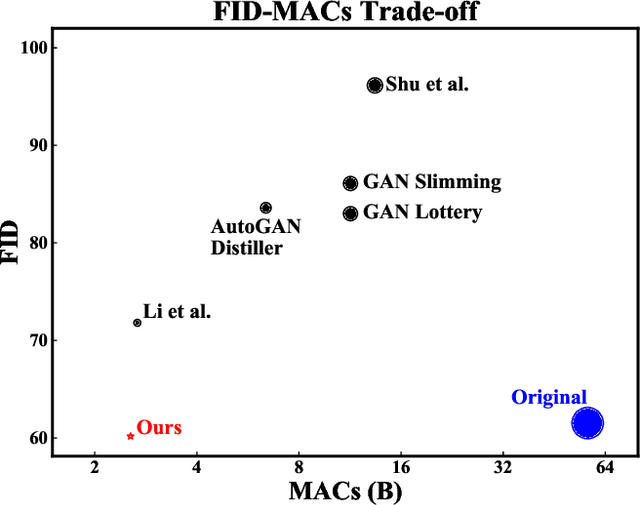
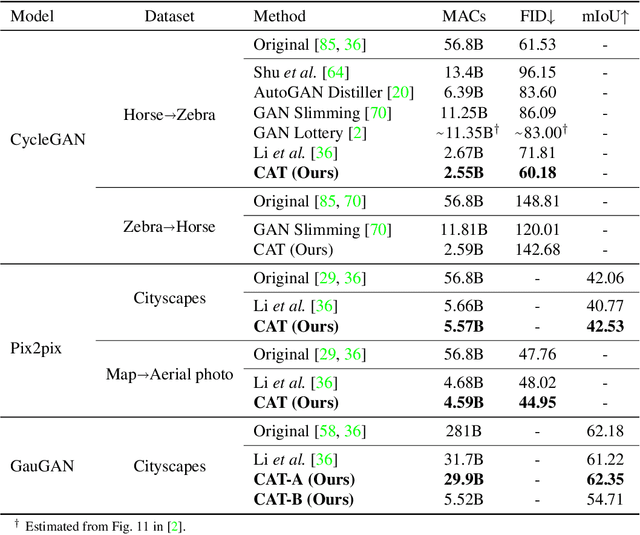
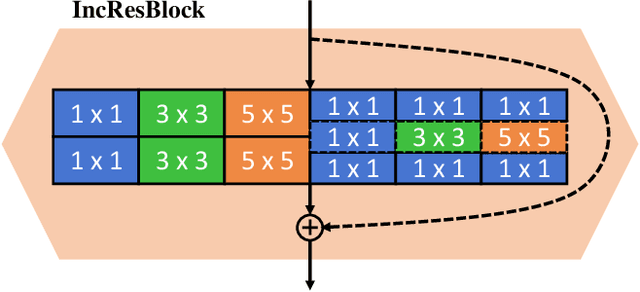
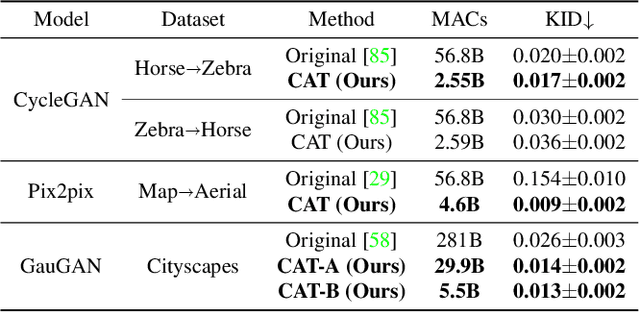
Generative Adversarial Networks (GANs) have achieved huge success in generating high-fidelity images, however, they suffer from low efficiency due to tremendous computational cost and bulky memory usage. Recent efforts on compression GANs show noticeable progress in obtaining smaller generators by sacrificing image quality or involving a time-consuming searching process. In this work, we aim to address these issues by introducing a teacher network that provides a search space in which efficient network architectures can be found, in addition to performing knowledge distillation. First, we revisit the search space of generative models, introducing an inception-based residual block into generators. Second, to achieve target computation cost, we propose a one-step pruning algorithm that searches a student architecture from the teacher model and substantially reduces searching cost. It requires no l1 sparsity regularization and its associated hyper-parameters, simplifying the training procedure. Finally, we propose to distill knowledge through maximizing feature similarity between teacher and student via an index named Global Kernel Alignment (GKA). Our compressed networks achieve similar or even better image fidelity (FID, mIoU) than the original models with much-reduced computational cost, e.g., MACs. Code will be released at https://github.com/snap-research/CAT.
Progressive Batching for Efficient Non-linear Least Squares
Oct 21, 2020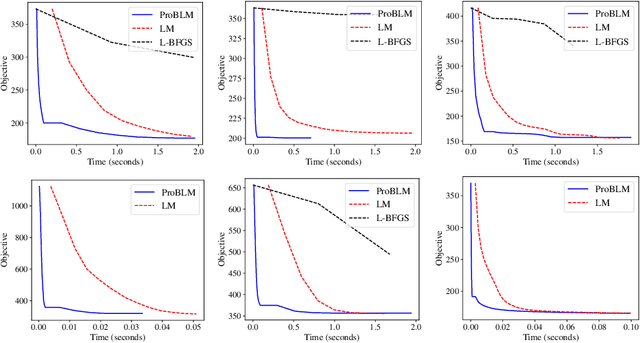
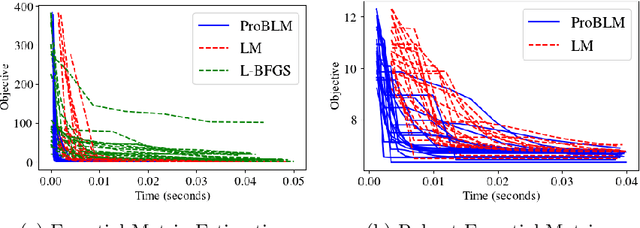
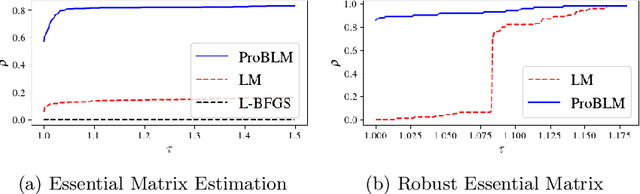
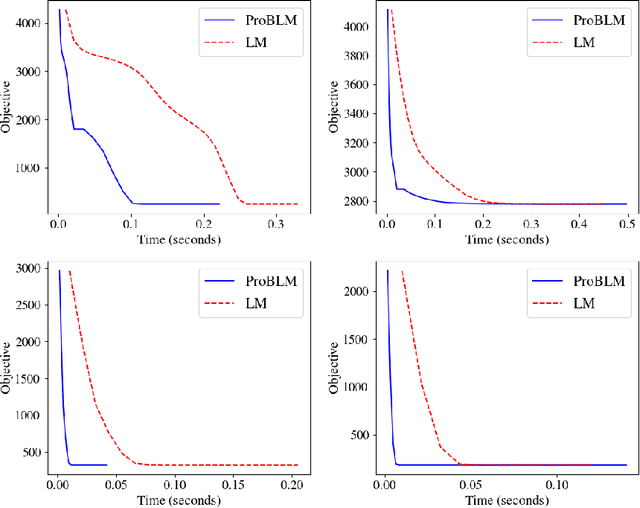
Non-linear least squares solvers are used across a broad range of offline and real-time model fitting problems. Most improvements of the basic Gauss-Newton algorithm tackle convergence guarantees or leverage the sparsity of the underlying problem structure for computational speedup. With the success of deep learning methods leveraging large datasets, stochastic optimization methods received recently a lot of attention. Our work borrows ideas from both stochastic machine learning and statistics, and we present an approach for non-linear least-squares that guarantees convergence while at the same time significantly reduces the required amount of computation. Empirical results show that our proposed method achieves competitive convergence rates compared to traditional second-order approaches on common computer vision problems, such as image alignment and essential matrix estimation, with very large numbers of residuals.
Large Scale Photometric Bundle Adjustment
Sep 10, 2020
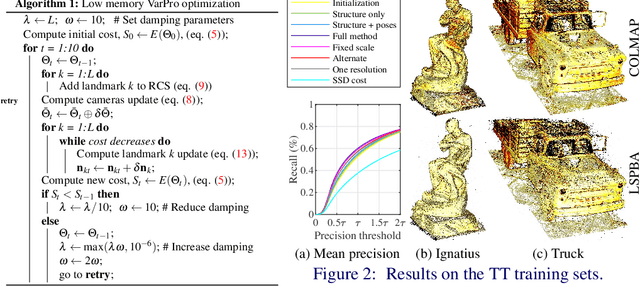

Direct methods have shown promise on visual odometry and SLAM, leading to greater accuracy and robustness over feature-based methods. However, offline 3-d reconstruction from internet images has not yet benefited from a joint, photometric optimization over dense geometry and camera parameters. Issues such as the lack of brightness constancy, and the sheer volume of data, make this a more challenging task. This work presents a framework for jointly optimizing millions of scene points and hundreds of camera poses and intrinsics, using a photometric cost that is invariant to local lighting changes. The improvement in metric reconstruction accuracy that it confers over feature-based bundle adjustment is demonstrated on the large-scale Tanks & Temples benchmark. We further demonstrate qualitative reconstruction improvements on an internet photo collection, with challenging diversity in lighting and camera intrinsics.
Using Normalized Cross Correlation in Least Squares Optimizations
Oct 10, 2018

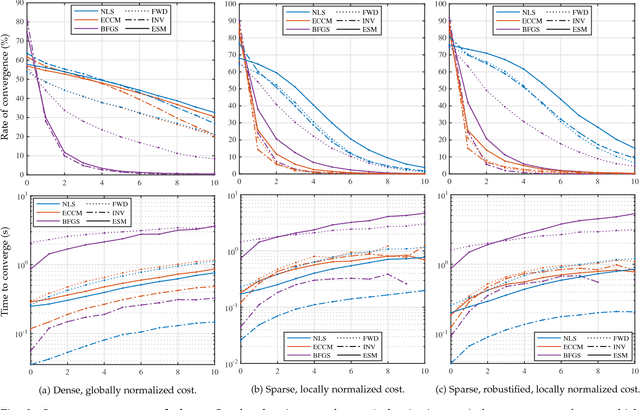
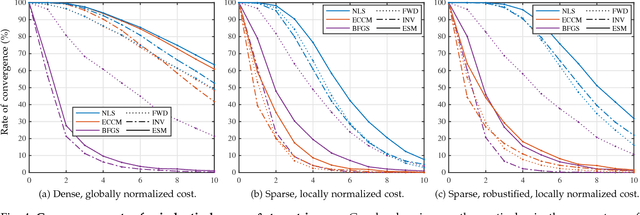
Direct methods for vision have widely used photometric least squares minimizations since the seminal 1981 work of Lucas & Kanade, and have leveraged normalized cross correlation since at least 1972. However, no work to our knowledge has successfully combined photometric least squares minimizations and normalized cross correlation: despite obvious complementary benefits of efficiency and accuracy on the one hand, and robustness to lighting changes on the other. This work shows that combining the two methods is not only possible, but also straightforward and efficient. The resulting minimization is shown to be superior to competing approaches, both in terms of convergence rate and computation time. Furthermore, a new, robust, sparse formulation is introduced to mitigate local intensity variations and partial occlusions.
Noise Models in Feature-based Stereo Visual Odometry
Jul 01, 2016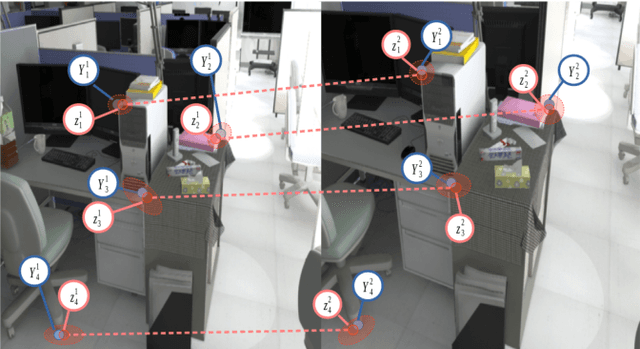
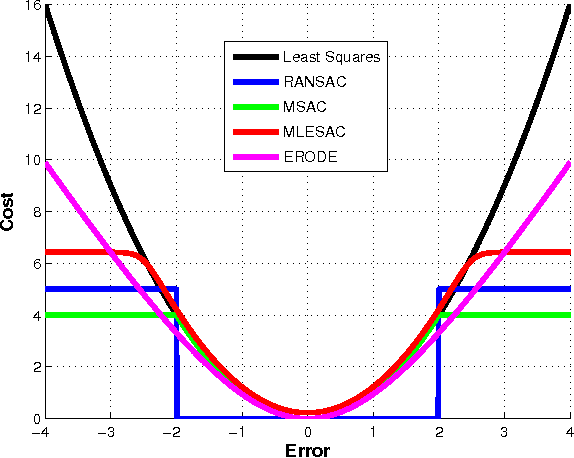
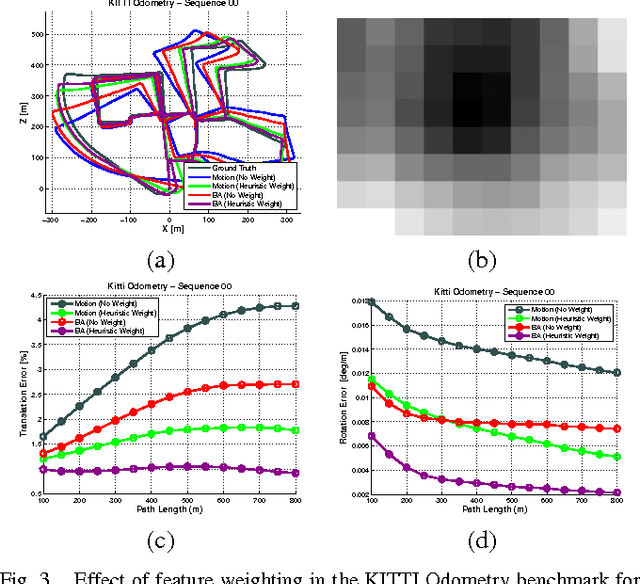
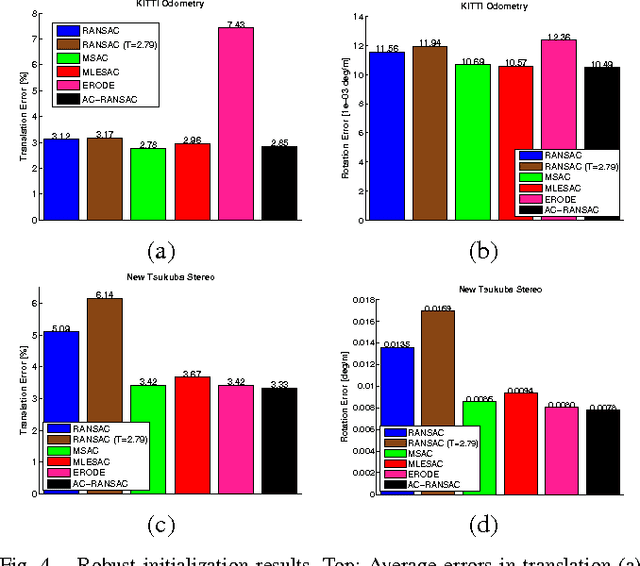
Feature-based visual structure and motion reconstruction pipelines, common in visual odometry and large-scale reconstruction from photos, use the location of corresponding features in different images to determine the 3D structure of the scene, as well as the camera parameters associated with each image. The noise model, which defines the likelihood of the location of each feature in each image, is a key factor in the accuracy of such pipelines, alongside optimization strategy. Many different noise models have been proposed in the literature; in this paper we investigate the performance of several. We evaluate these models specifically w.r.t. stereo visual odometry, as this task is both simple (camera intrinsics are constant and known; geometry can be initialized reliably) and has datasets with ground truth readily available (KITTI Odometry and New Tsukuba Stereo Dataset). Our evaluation shows that noise models which are more adaptable to the varying nature of noise generally perform better.