 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Batching for Efficient Non-linear Least Squares
Oct 21, 2020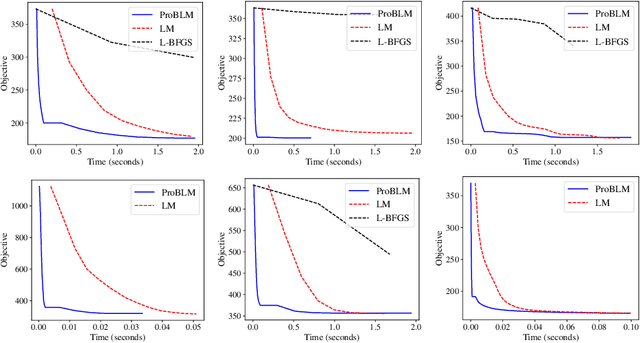
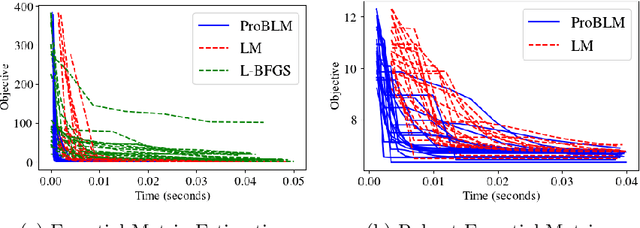
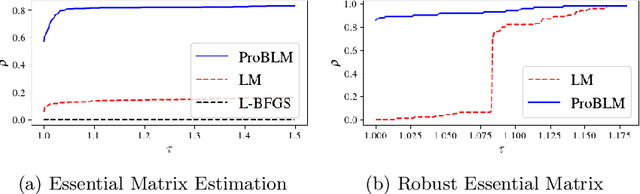
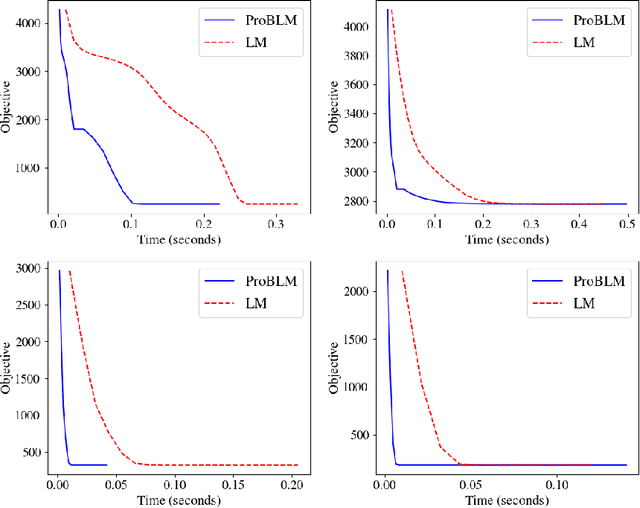
Non-linear least squares solvers are used across a broad range of offline and real-time model fitting problems. Most improvements of the basic Gauss-Newton algorithm tackle convergence guarantees or leverage the sparsity of the underlying problem structure for computational speedup. With the success of deep learning methods leveraging large datasets, stochastic optimization methods received recently a lot of attention. Our work borrows ideas from both stochastic machine learning and statistics, and we present an approach for non-linear least-squares that guarantees convergence while at the same time significantly reduces the required amount of computation. Empirical results show that our proposed method achieves competitive convergence rates compared to traditional second-order approaches on common computer vision problems, such as image alignment and essential matrix estimation, with very large numbers of residuals.
Large Scale Photometric Bundle Adjustment
Sep 10, 2020
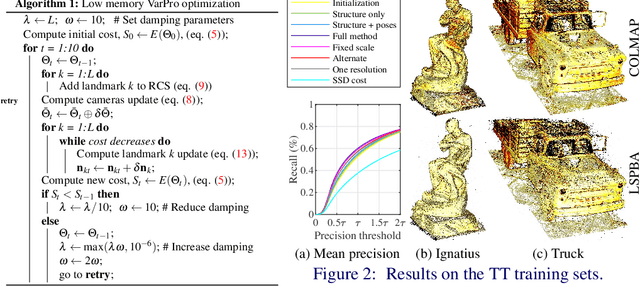

Direct methods have shown promise on visual odometry and SLAM, leading to greater accuracy and robustness over feature-based methods. However, offline 3-d reconstruction from internet images has not yet benefited from a joint, photometric optimization over dense geometry and camera parameters. Issues such as the lack of brightness constancy, and the sheer volume of data, make this a more challenging task. This work presents a framework for jointly optimizing millions of scene points and hundreds of camera poses and intrinsics, using a photometric cost that is invariant to local lighting changes. The improvement in metric reconstruction accuracy that it confers over feature-based bundle adjustment is demonstrated on the large-scale Tanks & Temples benchmark. We further demonstrate qualitative reconstruction improvements on an internet photo collection, with challenging diversity in lighting and camera intrinsics.
Y-Autoencoders: disentangling latent representations via sequential-encoding
Jul 25, 2019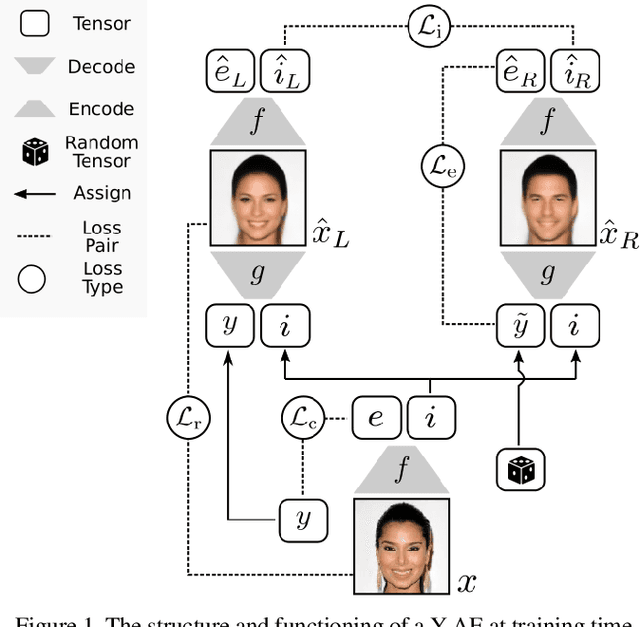

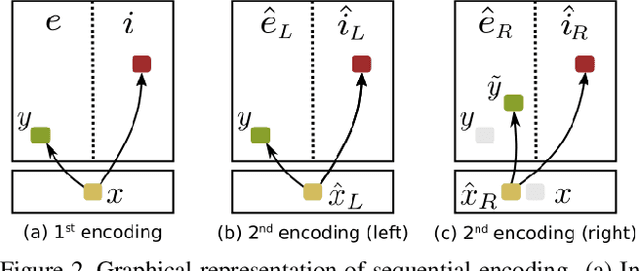

In the last few years there have been important advancements in generative models with the two dominant approaches being Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). However, standard Autoencoders (AEs) and closely related structures have remained popular because they are easy to train and adapt to different tasks. An interesting question is if we can achieve state-of-the-art performance with AEs while retaining their good properties. We propose an answer to this question by introducing a new model called Y-Autoencoder (Y-AE). The structure and training procedure of a Y-AE enclose a representation into an implicit and an explicit part. The implicit part is similar to the output of an autoencoder and the explicit part is strongly correlated with labels in the training set. The two parts are separated in the latent space by splitting the output of the encoder into two paths (forming a Y shape) before decoding and re-encoding. We then impose a number of losses, such as reconstruction loss, and a loss on dependence between the implicit and explicit parts. Additionally, the projection in the explicit manifold is monitored by a predictor, that is embedded in the encoder and trained end-to-end with no adversarial losses. We provide significant experimental results on various domains, such as separation of style and content, image-to-image translation, and inverse graphics.
Improved RANSAC performance using simple, iterative minimal-set solvers
Jul 08, 2010
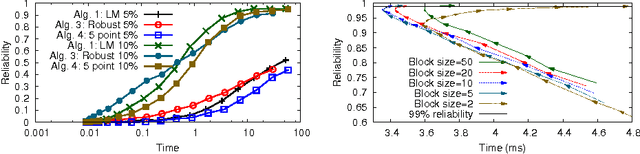

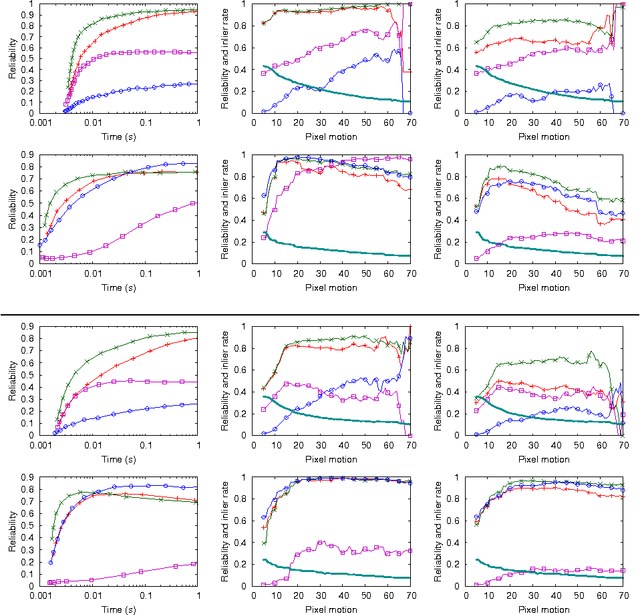
RANSAC is a popular technique for estimating model parameters in the presence of outliers. The best speed is achieved when the minimum possible number of points is used to estimate hypotheses for the model. Many useful problems can be represented using polynomial constraints (for instance, the determinant of a fundamental matrix must be zero) and so have a number of solutions which are consistent with a minimal set. A considerable amount of effort has been expended on finding the constraints of such problems, and these often require the solution of systems of polynomial equations. We show that better performance can be achieved by using a simple optimization based approach on minimal sets. For a given minimal set, the optimization approach is not guaranteed to converge to the correct solution. However, when used within RANSAC the greater speed and numerical stability results in better performance overall, and much simpler algorithms. We also show that by selecting more than the minimal number of points and using robust optimization can yield better results for very noisy by reducing the number of trials required. The increased speed of our method demonstrated with experiments on essential matrix estimation.
Automatic creation of urban velocity fields from aerial video
Dec 07, 2009

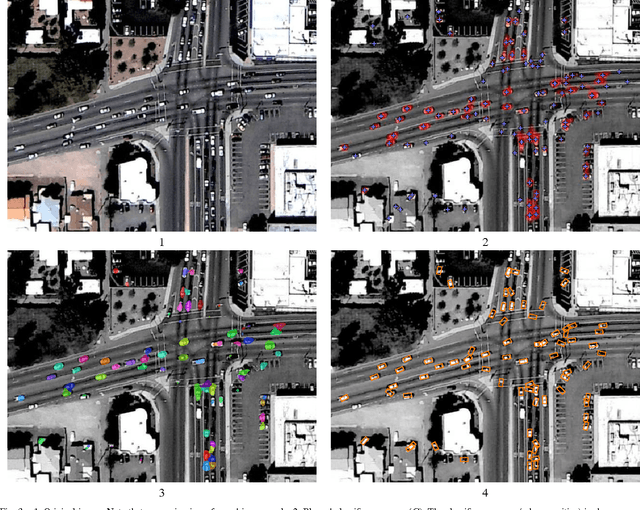
In this paper, we present a system for modelling vehicle motion in an urban scene from low frame-rate aerial video. In particular, the scene is modelled as a probability distribution over velocities at every pixel in the image. We describe the complete system for acquiring this model. The video is captured from a helicopter and stabilized by warping the images to match an orthorectified image of the area. A pixel classifier is applied to the stabilized images, and the response is segmented to determine car locations and orientations. The results are fed in to a tracking scheme which tracks cars for three frames, creating tracklets. This allows the tracker to use a combination of velocity, direction, appearance, and acceleration cues to keep only tracks likely to be correct. Each tracklet provides a measurement of the car velocity at every point along the tracklet's length, and these are then aggregated to create a histogram of vehicle velocities at every pixel in the image. The results demonstrate that the velocity probability distribution prior can be used to infer a variety of information about road lane directions, speed limits, vehicle speeds and common trajectories, and traffic bottlenecks, as well as providing a means of describing environmental knowledge about traffic rules that can be used in tracking.
Learning Object Location Predictors with Boosting and Grammar-Guided Feature Extraction
Jul 24, 2009
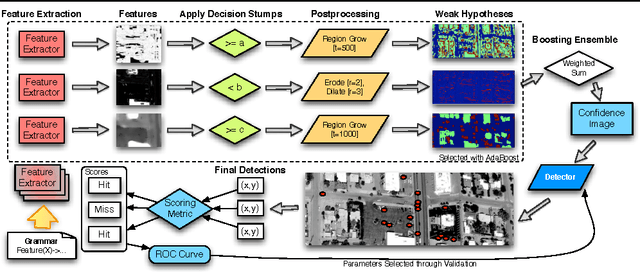

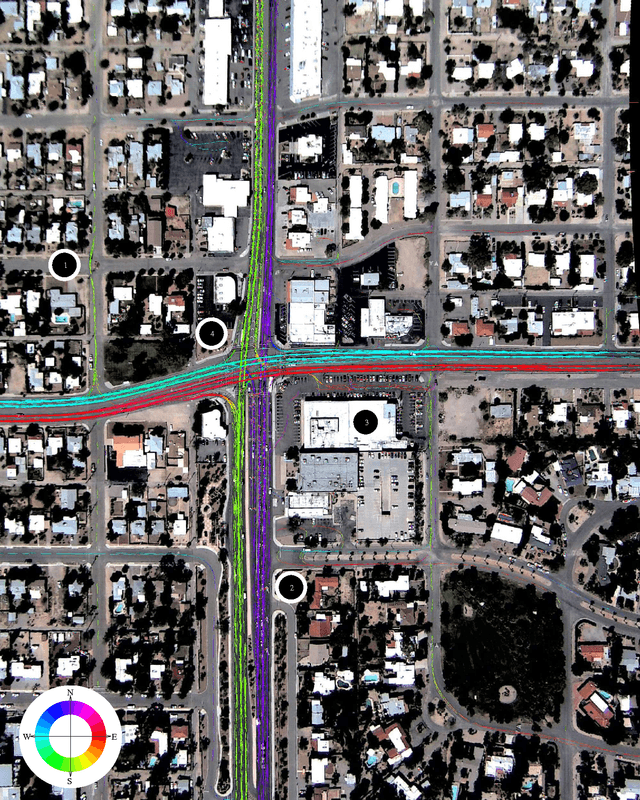
We present BEAMER: a new spatially exploitative approach to learning object detectors which shows excellent results when applied to the task of detecting objects in greyscale aerial imagery in the presence of ambiguous and noisy data. There are four main contributions used to produce these results. First, we introduce a grammar-guided feature extraction system, enabling the exploration of a richer feature space while constraining the features to a useful subset. This is specified with a rule-based generative grammar crafted by a human expert. Second, we learn a classifier on this data using a newly proposed variant of AdaBoost which takes into account the spatially correlated nature of the data. Third, we perform another round of training to optimize the method of converting the pixel classifications generated by boosting into a high quality set of (x, y) locations. Lastly, we carefully define three common problems in object detection and define two evaluation criteria that are tightly matched to these problems. Major strengths of this approach are: (1) a way of randomly searching a broad feature space, (2) its performance when evaluated on well-matched evaluation criteria, and (3) its use of the location prediction domain to learn object detectors as well as to generate detections that perform well on several tasks: object counting, tracking, and target detection. We demonstrate the efficacy of BEAMER with a comprehensive experimental evaluation on a challenging data set.
Camera distortion self-calibration using the plumb-line constraint and minimal Hough entropy
Jan 04, 2009
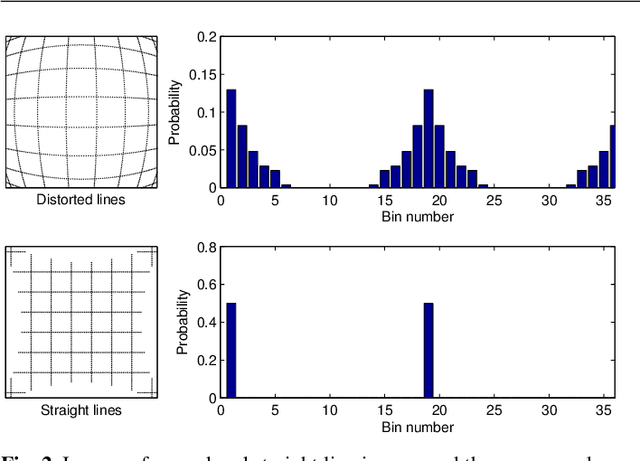


In this paper we present a simple and robust method for self-correction of camera distortion using single images of scenes which contain straight lines. Since the most common distortion can be modelled as radial distortion, we illustrate the method using the Harris radial distortion model, but the method is applicable to any distortion model. The method is based on transforming the edgels of the distorted image to a 1-D angular Hough space, and optimizing the distortion correction parameters which minimize the entropy of the corresponding normalized histogram. Properly corrected imagery will have fewer curved lines, and therefore less spread in Hough space. Since the method does not rely on any image structure beyond the existence of edgels sharing some common orientations and does not use edge fitting, it is applicable to a wide variety of image types. For instance, it can be applied equally well to images of texture with weak but dominant orientations, or images with strong vanishing points. Finally, the method is performed on both synthetic and real data revealing that it is particularly robust to noise.
Faster and better: a machine learning approach to corner detection
Oct 14, 2008
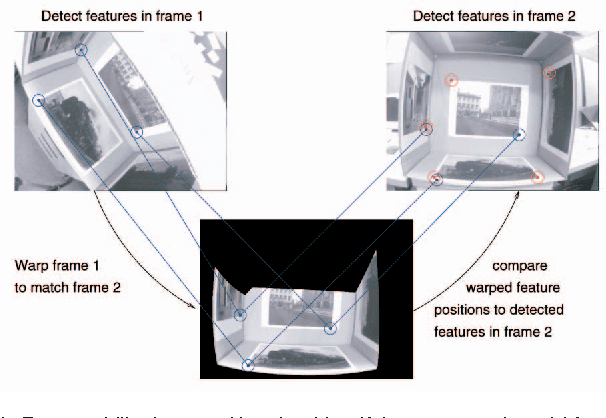
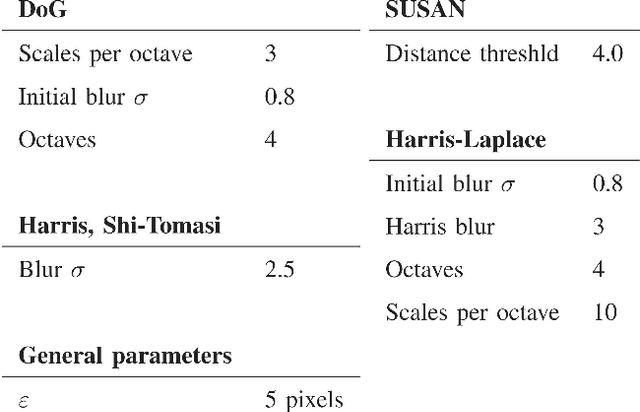
The repeatability and efficiency of a corner detector determines how likely it is to be useful in a real-world application. The repeatability is importand because the same scene viewed from different positions should yield features which correspond to the same real-world 3D locations [Schmid et al 2000]. The efficiency is important because this determines whether the detector combined with further processing can operate at frame rate. Three advances are described in this paper. First, we present a new heuristic for feature detection, and using machine learning we derive a feature detector from this which can fully process live PAL video using less than 5% of the available processing time. By comparison, most other detectors cannot even operate at frame rate (Harris detector 115%, SIFT 195%). Second, we generalize the detector, allowing it to be optimized for repeatability, with little loss of efficiency. Third, we carry out a rigorous comparison of corner detectors based on the above repeatability criterion applied to 3D scenes. We show that despite being principally constructed for speed, on these stringent tests, our heuristic detector significantly outperforms existing feature detectors. Finally, the comparison demonstrates that using machine learning produces significant improvements in repeatability, yielding a detector that is both very fast and very high quality.
* 35 pages, 11 figures