 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysMirror: Physics-Aware Mirror Object Generation
Jul 03, 2026Synthesizing physically accurate mirror reflections remains a fundamental challenge for modern text-to-image diffusion models, which are increasingly critical for generating synthetic training data for embodied AI and robotic perception. These models typically struggle with strict geometric constraints, leading to hallucinations that degrade the utility of the synthetic data. To address this, we introduce a novel, end-to-end physics-aware generation framework namely PhysMirror that natively enforces projective geometry through explicit 3D spatial priors. Our method automatically lifts prompted objects into 3D meshes and constructs a lightweight, mathematically exact mirror scene within a simulated environment. By rendering this explicit 3D scene, we extract precise 2D conditioning elements, such as depth maps and segmentation maps, that serve as robust guiding signals for downstream diffusion models, guiding them to generate images with physically correct mirror reflections. Moreover, we introduce Mirror Consistency Score (MCS), reference-free, fully automated metric that quantifies physical correctness using dense feature matching and vanishing point convergence. Experimental results on our newly constructed MirrOB dataset demonstrate that our approach outperforms state-of-the-art baselines in reflection accuracy and physical realism, while maintaining strong text-to-image semantic alignment, providing a reliable pipeline for embodied AI data generation. The source code is released at https://duyphuc0701.github.io/PhysMirror.
Depth Perspective-aware Multiple Object Tracking
Jul 10, 2022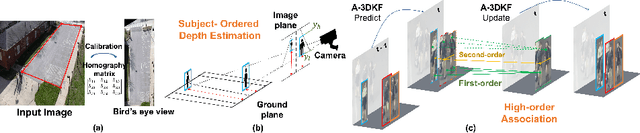
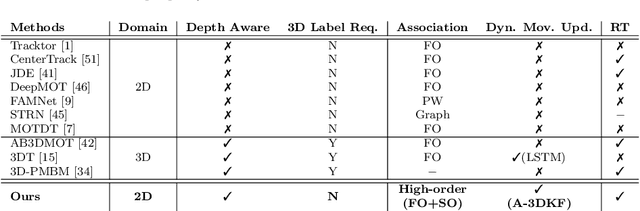
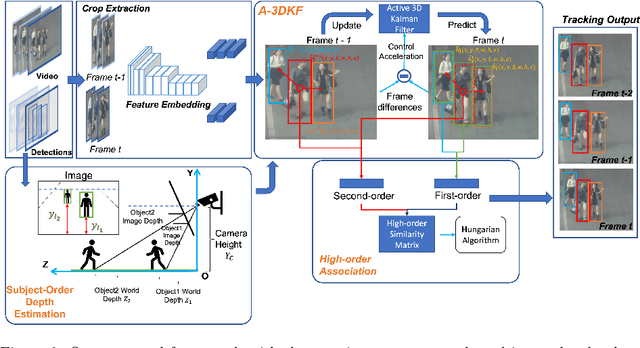
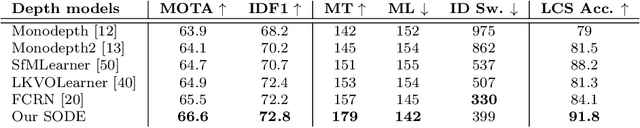
This paper aims to tackle Multiple Object Tracking (MOT), an important problem in computer vision but remains challenging due to many practical issues, especially occlusions. Indeed, we propose a new real-time Depth Perspective-aware Multiple Object Tracking (DP-MOT) approach to tackle the occlusion problem in MOT. A simple yet efficient Subject-Ordered Depth Estimation (SODE) is first proposed to automatically order the depth positions of detected subjects in a 2D scene in an unsupervised manner. Using the output from SODE, a new Active pseudo-3D Kalman filter, a simple but effective extension of Kalman filter with dynamic control variables, is then proposed to dynamically update the movement of objects. In addition, a new high-order association approach is presented in the data association step to incorporate first-order and second-order relationships between the detected objects. The proposed approach consistently achieves state-of-the-art performance compared to recent MOT methods on standard MOT benchmarks.
Fast Semantic-Assisted Outlier Removal for Large-scale Point Cloud Registration
Feb 21, 2022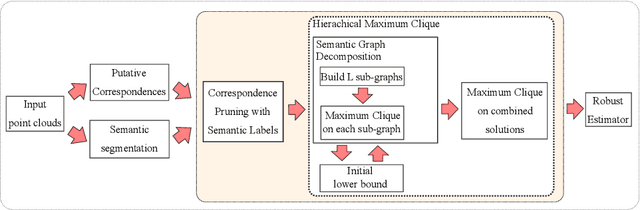
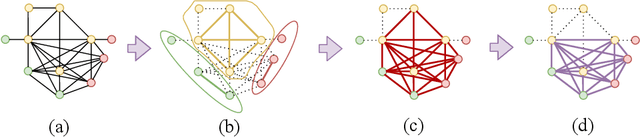

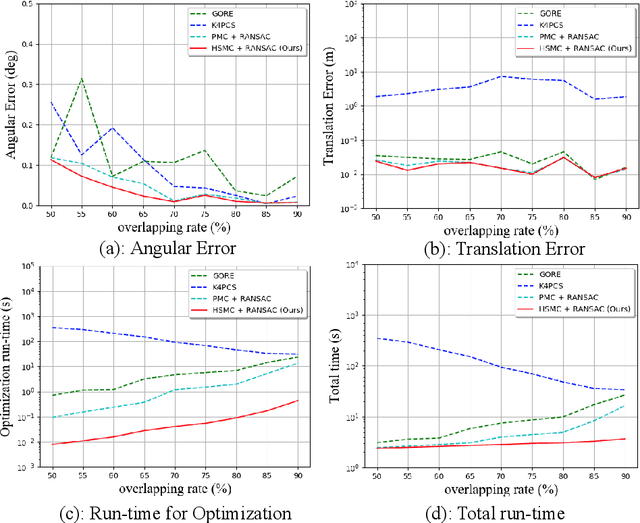
With current trends in sensors (cheaper, more volume of data) and applications (increasing affordability for new tasks, new ideas in what 3D data could be useful for); there is corresponding increasing interest in the ability to automatically, reliably, and cheaply, register together individual point clouds. The volume of data to handle, and still elusive need to have the registration occur fully reliably and fully automatically, mean there is a need to innovate further. One largely untapped area of innovation is that of exploiting the {\em semantic information} of the points in question. Points on a tree should match points on a tree, for example, and not points on car. Moreover, such a natural restriction is clearly human-like - a human would generally quickly eliminate candidate regions for matching based on semantics. Employing semantic information is not only efficient but natural. It is also timely - due to the recent advances in semantic classification capabilities. This paper advances this theme by demonstrating that state of the art registration techniques, in particular ones that rely on "preservation of length under rigid motion" as an underlying matching consistency constraint, can be augmented with semantic information. Semantic identity is of course also preserved under rigid-motion, but also under wider motions present in a scene. We demonstrate that not only the potential obstacle of cost of semantic segmentation, and the potential obstacle of the unreliability of semantic segmentation; are both no impediment to achieving both speed and accuracy in fully automatic registration of large scale point clouds.
AdaSTE: An Adaptive Straight-Through Estimator to Train Binary Neural Networks
Dec 06, 2021
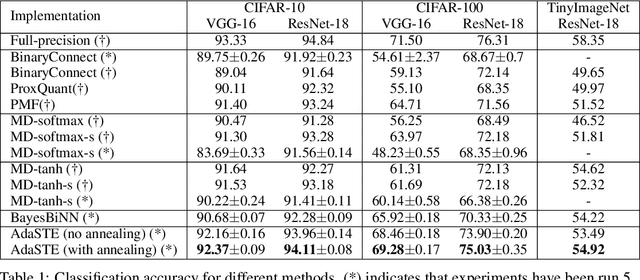
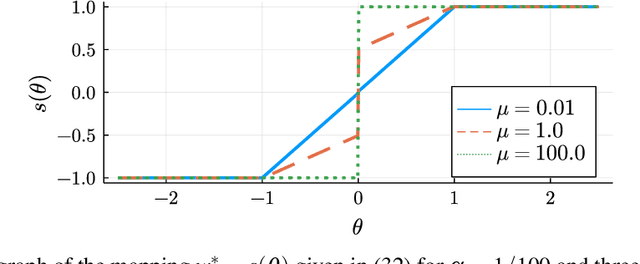
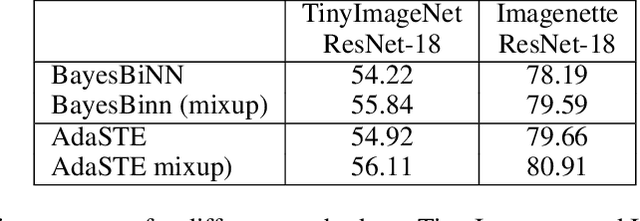
We propose a new algorithm for training deep neural networks (DNNs) with binary weights. In particular, we first cast the problem of training binary neural networks (BiNNs) as a bilevel optimization instance and subsequently construct flexible relaxations of this bilevel program. The resulting training method shares its algorithmic simplicity with several existing approaches to train BiNNs, in particular with the straight-through gradient estimator successfully employed in BinaryConnect and subsequent methods. In fact, our proposed method can be interpreted as an adaptive variant of the original straight-through estimator that conditionally (but not always) acts like a linear mapping in the backward pass of error propagation. Experimental results demonstrate that our new algorithm offers favorable performance compared to existing approaches.
DyGLIP: A Dynamic Graph Model with Link Prediction for Accurate Multi-Camera Multiple Object Tracking
Jun 12, 2021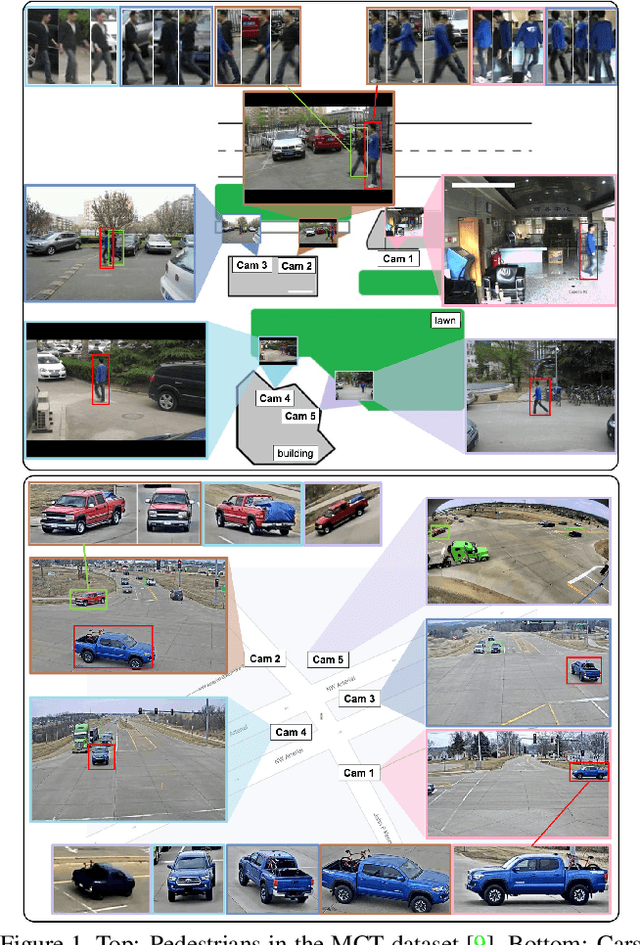
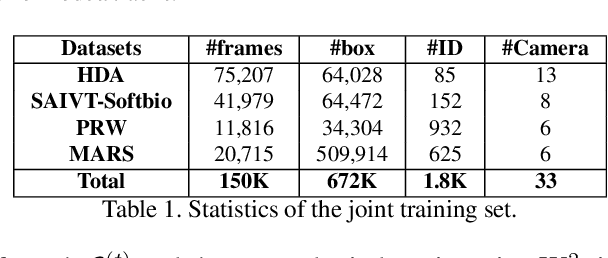
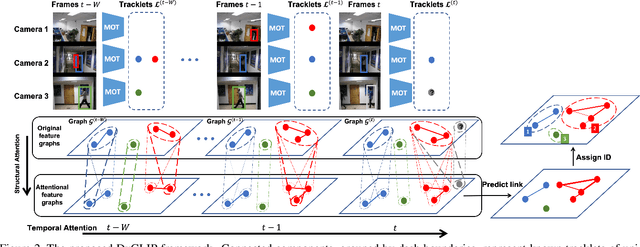
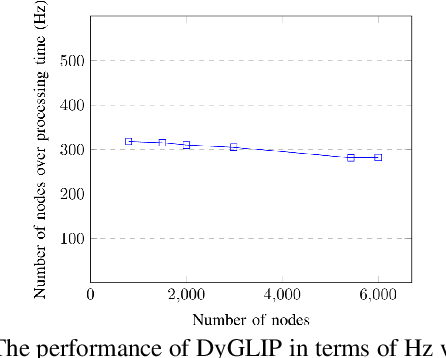
Multi-Camera Multiple Object Tracking (MC-MOT) is a significant computer vision problem due to its emerging applicability in several real-world applications. Despite a large number of existing works, solving the data association problem in any MC-MOT pipeline is arguably one of the most challenging tasks. Developing a robust MC-MOT system, however, is still highly challenging due to many practical issues such as inconsistent lighting conditions, varying object movement patterns, or the trajectory occlusions of the objects between the cameras. To address these problems, this work, therefore, proposes a new Dynamic Graph Model with Link Prediction (DyGLIP) approach to solve the data association task. Compared to existing methods, our new model offers several advantages, including better feature representations and the ability to recover from lost tracks during camera transitions. Moreover, our model works gracefully regardless of the overlapping ratios between the cameras. Experimental results show that we outperform existing MC-MOT algorithms by a large margin on several practical datasets. Notably, our model works favorably on online settings but can be extended to an incremental approach for large-scale datasets.
Unsupervised Learning for Robust Fitting:A Reinforcement Learning Approach
Mar 05, 2021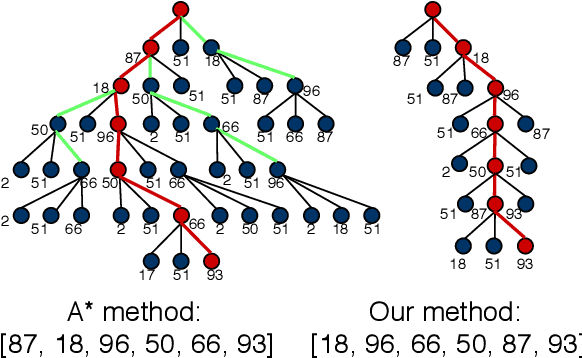
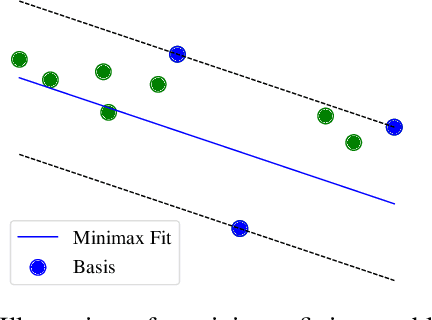
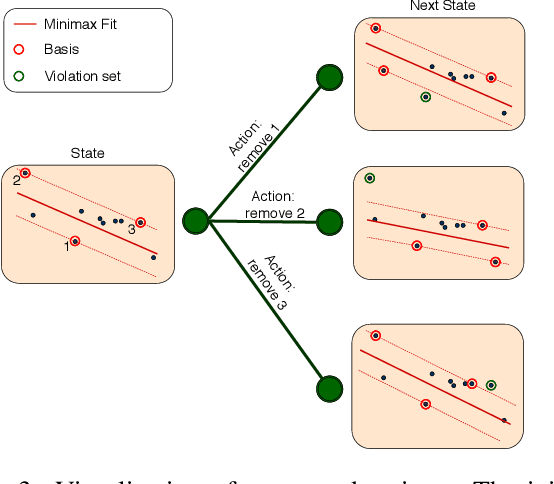
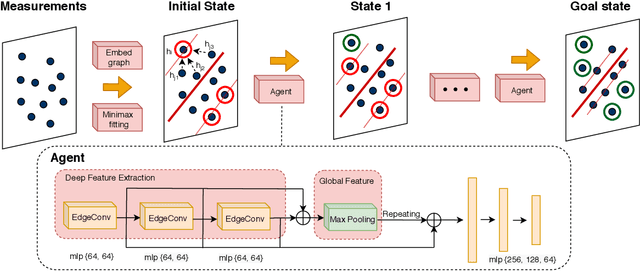
Robust model fitting is a core algorithm in a large number of computer vision applications. Solving this problem efficiently for datasets highly contaminated with outliers is, however, still challenging due to the underlying computational complexity. Recent literature has focused on learning-based algorithms. However, most approaches are supervised which require a large amount of labelled training data. In this paper, we introduce a novel unsupervised learning framework that learns to directly solve robust model fitting. Unlike other methods, our work is agnostic to the underlying input features, and can be easily generalized to a wide variety of LP-type problems with quasi-convex residuals. We empirically show that our method outperforms existing unsupervised learning approaches, and achieves competitive results compared to traditional methods on several important computer vision problems.
Escaping Poor Local Minima in Large Scale Robust Estimation
Feb 22, 2021
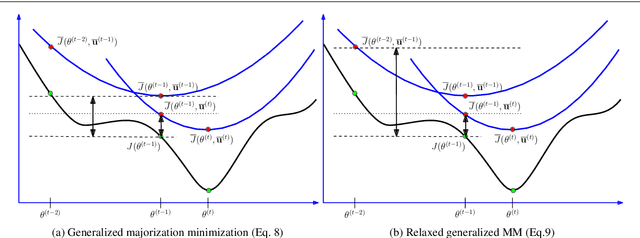
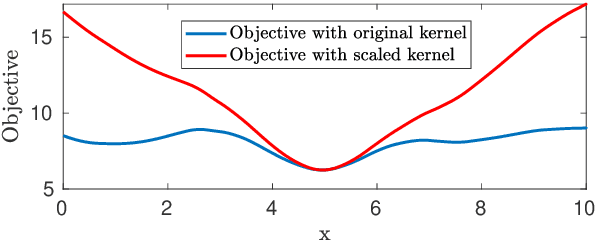
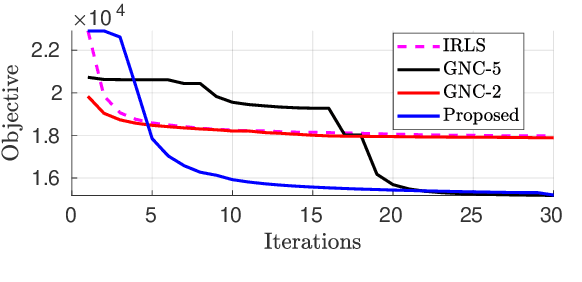
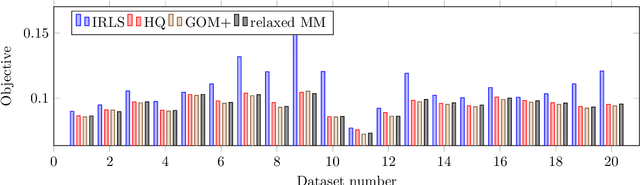
Robust parameter estimation is a crucial task in several 3D computer vision pipelines such as Structure from Motion (SfM). State-of-the-art algorithms for robust estimation, however, still suffer from difficulties in converging to satisfactory solutions due to the presence of many poor local minima or flat regions in the optimization landscapes. In this paper, we introduce two novel approaches for robust parameter estimation. The first algorithm utilizes the Filter Method (FM), which is a framework for constrained optimization allowing great flexibility in algorithmic choices, to derive an adaptive kernel scaling strategy that enjoys a strong ability to escape poor minima and achieves fast convergence rates. Our second algorithm combines a generalized Majorization Minimization (GeMM) framework with the half-quadratic lifting formulation to obtain a simple yet efficient solver for robust estimation. We empirically show that both proposed approaches show encouraging capability on avoiding poor local minima and achieve competitive results compared to existing state-of-the art robust fitting algorithms.
Progressive Batching for Efficient Non-linear Least Squares
Oct 21, 2020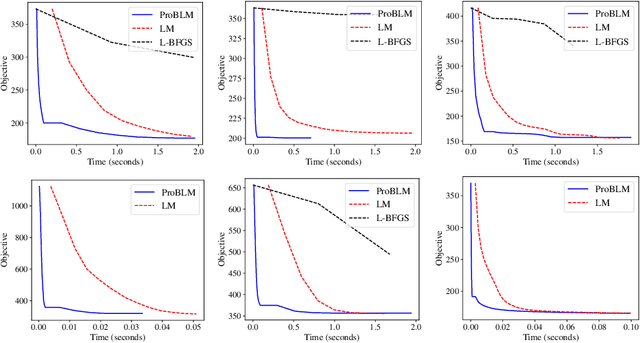
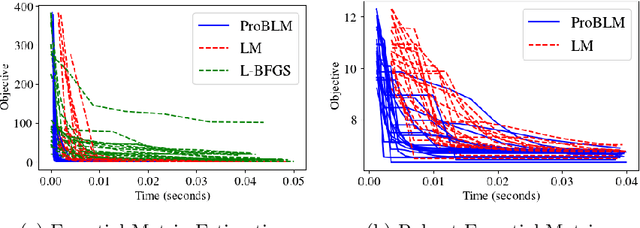
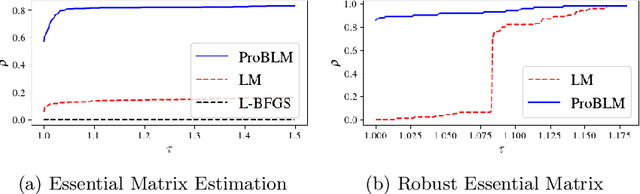
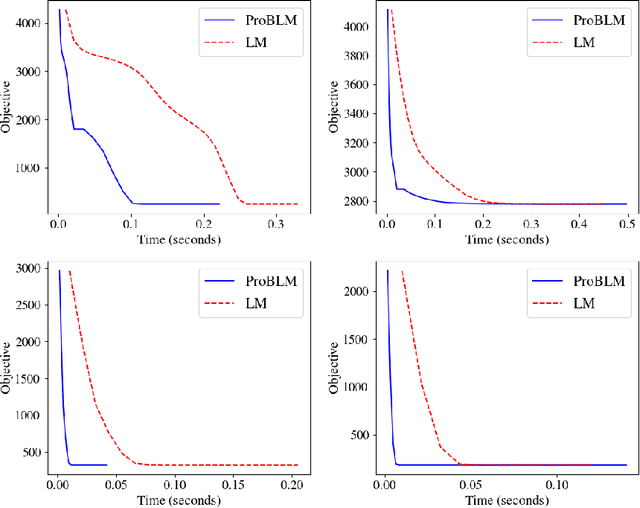
Non-linear least squares solvers are used across a broad range of offline and real-time model fitting problems. Most improvements of the basic Gauss-Newton algorithm tackle convergence guarantees or leverage the sparsity of the underlying problem structure for computational speedup. With the success of deep learning methods leveraging large datasets, stochastic optimization methods received recently a lot of attention. Our work borrows ideas from both stochastic machine learning and statistics, and we present an approach for non-linear least-squares that guarantees convergence while at the same time significantly reduces the required amount of computation. Empirical results show that our proposed method achieves competitive convergence rates compared to traditional second-order approaches on common computer vision problems, such as image alignment and essential matrix estimation, with very large numbers of residuals.
A Graduated Filter Method for Large Scale Robust Estimation
Mar 20, 2020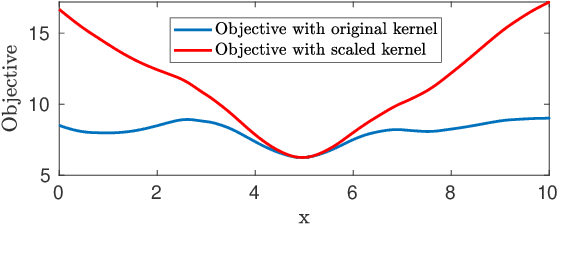
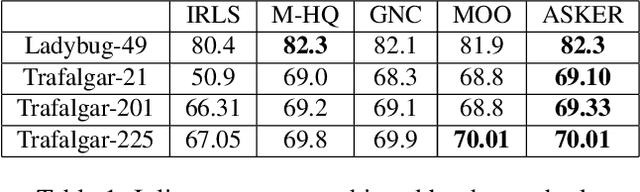
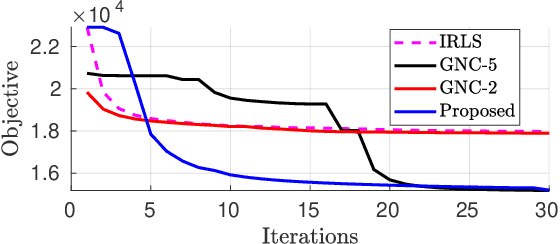
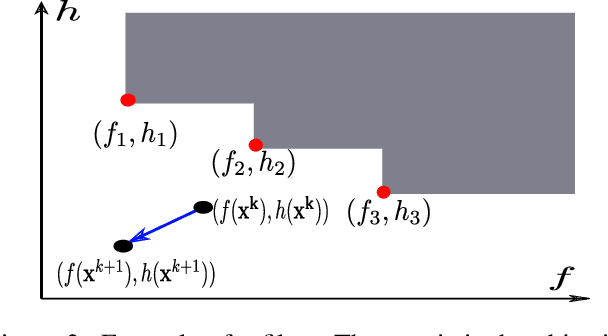
Due to the highly non-convex nature of large-scale robust parameter estimation, avoiding poor local minima is challenging in real-world applications where input data is contaminated by a large or unknown fraction of outliers. In this paper, we introduce a novel solver for robust estimation that possesses a strong ability to escape poor local minima. Our algorithm is built upon the class of traditional graduated optimization techniques, which are considered state-of-the-art local methods to solve problems having many poor minima. The novelty of our work lies in the introduction of an adaptive kernel (or residual) scaling scheme, which allows us to achieve faster convergence rates. Like other existing methods that aim to return good local minima for robust estimation tasks, our method relaxes the original robust problem but adapts a filter framework from non-linear constrained optimization to automatically choose the level of relaxation. Experimental results on real large-scale datasets such as bundle adjustment instances demonstrate that our proposed method achieves competitive results.
Truncated Inference for Latent Variable Optimization Problems: Application to Robust Estimation and Learning
Mar 12, 2020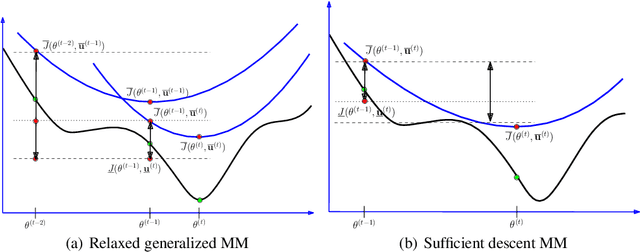


Optimization problems with an auxiliary latent variable structure in addition to the main model parameters occur frequently in computer vision and machine learning. The additional latent variables make the underlying optimization task expensive, either in terms of memory (by maintaining the latent variables), or in terms of runtime (repeated exact inference of latent variables). We aim to remove the need to maintain the latent variables and propose two formally justified methods, that dynamically adapt the required accuracy of latent variable inference. These methods have applications in large scale robust estimation and in learning energy-based models from labeled data.