Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncated Inference for Latent Variable Optimization Problems: Application to Robust Estimation and Learning
Paper and Code
Mar 12, 2020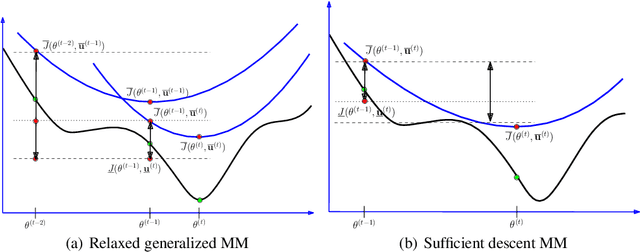

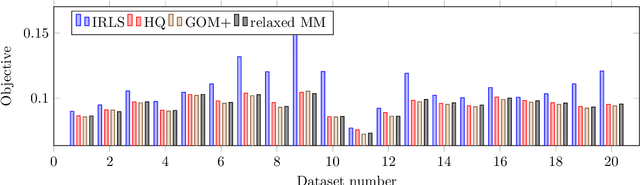

Optimization problems with an auxiliary latent variable structure in addition to the main model parameters occur frequently in computer vision and machine learning. The additional latent variables make the underlying optimization task expensive, either in terms of memory (by maintaining the latent variables), or in terms of runtime (repeated exact inference of latent variables). We aim to remove the need to maintain the latent variables and propose two formally justified methods, that dynamically adapt the required accuracy of latent variable inference. These methods have applications in large scale robust estimation and in learning energy-based models from labeled data.
* 16 pages
View paper on