 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Unlearn for Deep Neural Networks: Minimizing Unlearning Interference with Gradient Projection
Dec 07, 2023

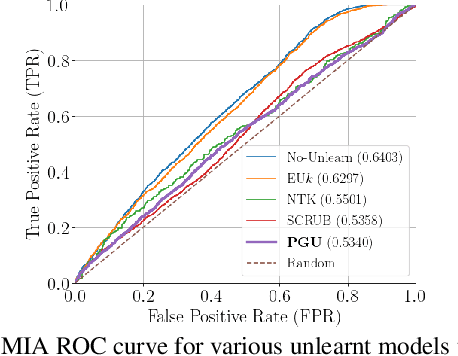

Recent data-privacy laws have sparked interest in machine unlearning, which involves removing the effect of specific training samples from a learnt model as if they were never present in the original training dataset. The challenge of machine unlearning is to discard information about the ``forget'' data in the learnt model without altering the knowledge about the remaining dataset and to do so more efficiently than the naive retraining approach. To achieve this, we adopt a projected-gradient based learning method, named as Projected-Gradient Unlearning (PGU), in which the model takes steps in the orthogonal direction to the gradient subspaces deemed unimportant for the retaining dataset, so as to its knowledge is preserved. By utilizing Stochastic Gradient Descent (SGD) to update the model weights, our method can efficiently scale to any model and dataset size. We provide empirically evidence to demonstrate that our unlearning method can produce models that behave similar to models retrained from scratch across various metrics even when the training dataset is no longer accessible. Our code is available at https://github.com/hnanhtuan/projected_gradient_unlearning.
Collaborative Multi-Teacher Knowledge Distillation for Learning Low Bit-width Deep Neural Networks
Oct 27, 2022Knowledge distillation which learns a lightweight student model by distilling knowledge from a cumbersome teacher model is an attractive approach for learning compact deep neural networks (DNNs). Recent works further improve student network performance by leveraging multiple teacher networks. However, most of the existing knowledge distillation-based multi-teacher methods use separately pretrained teachers. This limits the collaborative learning between teachers and the mutual learning between teachers and student. Network quantization is another attractive approach for learning compact DNNs. However, most existing network quantization methods are developed and evaluated without considering multi-teacher support to enhance the performance of quantized student model. In this paper, we propose a novel framework that leverages both multi-teacher knowledge distillation and network quantization for learning low bit-width DNNs. The proposed method encourages both collaborative learning between quantized teachers and mutual learning between quantized teachers and quantized student. During learning process, at corresponding layers, knowledge from teachers will form an importance-aware shared knowledge which will be used as input for teachers at subsequent layers and also be used to guide student. Our experimental results on CIFAR100 and ImageNet datasets show that the compact quantized student models trained with our method achieve competitive results compared to other state-of-the-art methods, and in some cases, indeed surpass the full precision models.
Multi-Modal Mutual Information Maximization: A Novel Approach for Unsupervised Deep Cross-Modal Hashing
Dec 13, 2021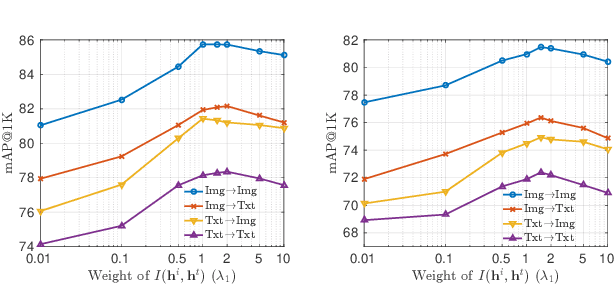
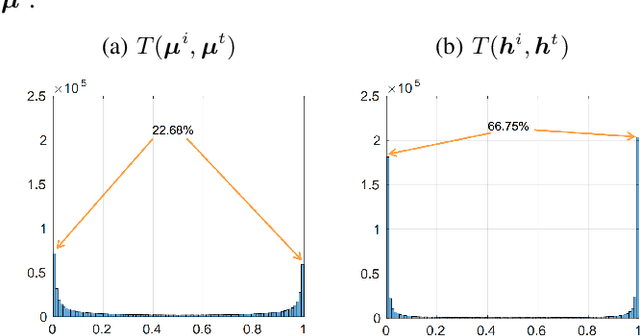
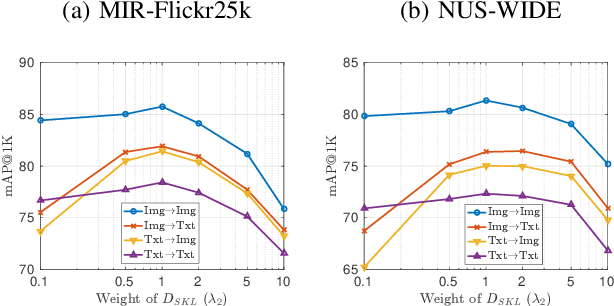
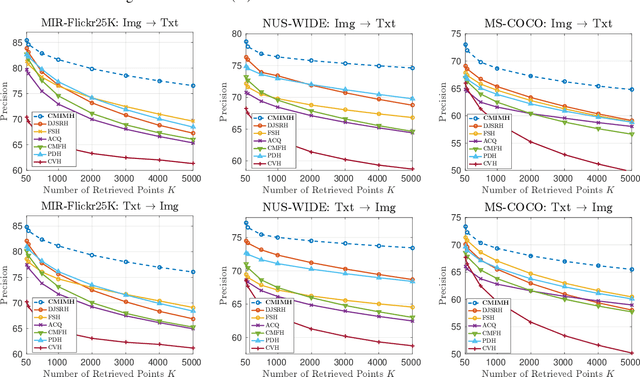
In this paper, we adopt the maximizing mutual information (MI) approach to tackle the problem of unsupervised learning of binary hash codes for efficient cross-modal retrieval. We proposed a novel method, dubbed Cross-Modal Info-Max Hashing (CMIMH). First, to learn informative representations that can preserve both intra- and inter-modal similarities, we leverage the recent advances in estimating variational lower-bound of MI to maximize the MI between the binary representations and input features and between binary representations of different modalities. By jointly maximizing these MIs under the assumption that the binary representations are modelled by multivariate Bernoulli distributions, we can learn binary representations, which can preserve both intra- and inter-modal similarities, effectively in a mini-batch manner with gradient descent. Furthermore, we find out that trying to minimize the modality gap by learning similar binary representations for the same instance from different modalities could result in less informative representations. Hence, balancing between reducing the modality gap and losing modality-private information is important for the cross-modal retrieval tasks. Quantitative evaluations on standard benchmark datasets demonstrate that the proposed method consistently outperforms other state-of-the-art cross-modal retrieval methods.
Direct Quantization for Training Highly Accurate Low Bit-width Deep Neural Networks
Dec 26, 2020



This paper proposes two novel techniques to train deep convolutional neural networks with low bit-width weights and activations. First, to obtain low bit-width weights, most existing methods obtain the quantized weights by performing quantization on the full-precision network weights. However, this approach would result in some mismatch: the gradient descent updates full-precision weights, but it does not update the quantized weights. To address this issue, we propose a novel method that enables {direct} updating of quantized weights {with learnable quantization levels} to minimize the cost function using gradient descent. Second, to obtain low bit-width activations, existing works consider all channels equally. However, the activation quantizers could be biased toward a few channels with high-variance. To address this issue, we propose a method to take into account the quantization errors of individual channels. With this approach, we can learn activation quantizers that minimize the quantization errors in the majority of channels. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on the image classification task, using AlexNet, ResNet and MobileNetV2 architectures on CIFAR-100 and ImageNet datasets.
Unsupervised Deep Cross-modality Spectral Hashing
Aug 18, 2020

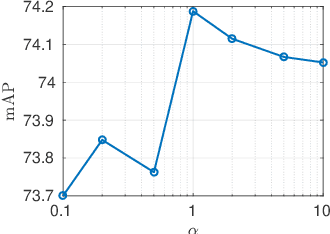
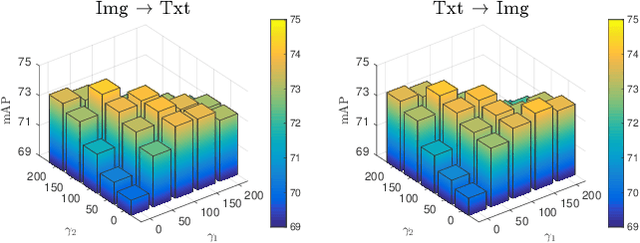
This paper presents a novel framework, namely Deep Cross-modality Spectral Hashing (DCSH), to tackle the unsupervised learning problem of binary hash codes for efficient cross-modal retrieval. The framework is a two-step hashing approach which decouples the optimization into (1) binary optimization and (2) hashing function learning. In the first step, we propose a novel spectral embedding-based algorithm to simultaneously learn single-modality and binary cross-modality representations. While the former is capable of well preserving the local structure of each modality, the latter reveals the hidden patterns from all modalities. In the second step, to learn mapping functions from informative data inputs (images and word embeddings) to binary codes obtained from the first step, we leverage the powerful CNN for images and propose a CNN-based deep architecture to learn text modality. Quantitative evaluations on three standard benchmark datasets demonstrate that the proposed DCSH method consistently outperforms other state-of-the-art methods.
BTEL: A Binary Tree Encoding Approach for Visual Localization
Jun 27, 2019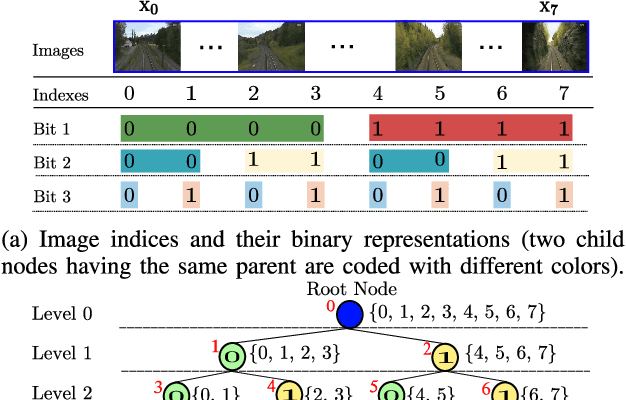
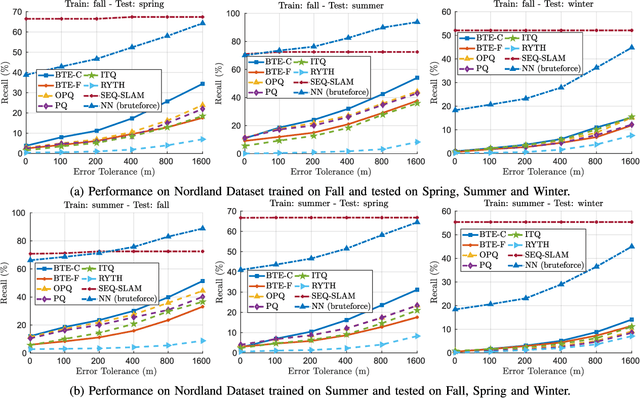
Visual localization algorithms have achieved significant improvements in performance thanks to recent advances in camera technology and vision-based techniques. However, there remains one critical caveat: all current approaches that are based on image retrieval currently scale at best linearly with the size of the environment with respect to both storage, and consequentially in most approaches, query time. This limitation severely curtails the capability of autonomous systems in a wide range of compute, power, storage, size, weight or cost constrained applications such as drones. In this work, we present a novel binary tree encoding approach for visual localization which can serve as an alternative for existing quantization and indexing techniques. The proposed tree structure allows us to derive a compressed training scheme that achieves sub-linearity in both required storage and inference time. The encoding memory can be easily configured to satisfy different storage constraints. Moreover, our approach is amenable to an optional sequence filtering mechanism to further improve the localization results, while maintaining the same amount of storage. Our system is entirely agnostic to the front-end descriptors, allowing it to be used on top of recent state-of-the-art image representations. Experimental results show that the proposed method significantly outperforms state-of-the-art approaches under limited storage constraints.
Simultaneous Feature Aggregating and Hashing for Compact Binary Code Learning
Apr 24, 2019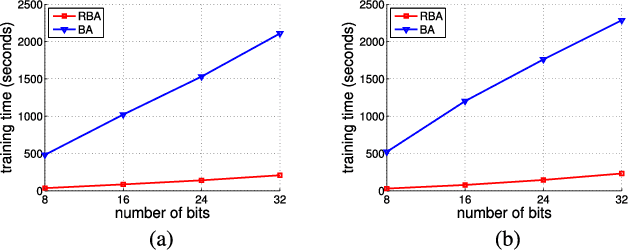
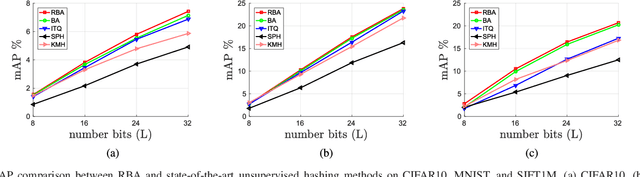
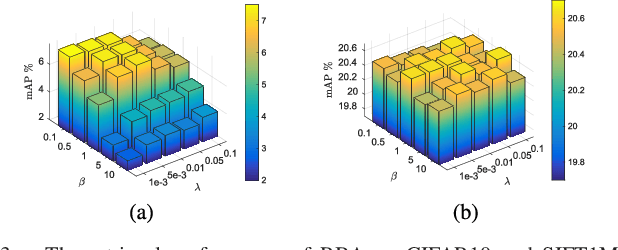
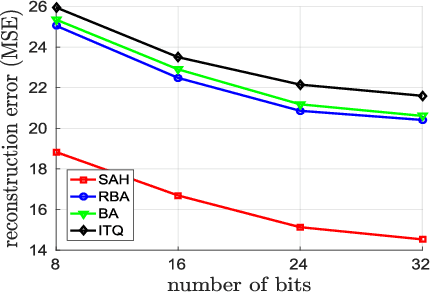
Representing images by compact hash codes is an attractive approach for large-scale content-based image retrieval. In most state-of-the-art hashing-based image retrieval systems, for each image, local descriptors are first aggregated as a global representation vector. This global vector is then subjected to a hashing function to generate a binary hash code. In previous works, the aggregating and the hashing processes are designed independently. Hence these frameworks may generate suboptimal hash codes. In this paper, we first propose a novel unsupervised hashing framework in which feature aggregating and hashing are designed simultaneously and optimized jointly. Specifically, our joint optimization generates aggregated representations that can be better reconstructed by some binary codes. This leads to more discriminative binary hash codes and improved retrieval accuracy. In addition, the proposed method is flexible. It can be extended for supervised hashing. When the data label is available, the framework can be adapted to learn binary codes which minimize the reconstruction loss w.r.t. label vectors. Furthermore, we also propose a fast version of the state-of-the-art hashing method Binary Autoencoder to be used in our proposed frameworks. Extensive experiments on benchmark datasets under various settings show that the proposed methods outperform state-of-the-art unsupervised and supervised hashing methods.
A Theoretically Sound Upper Bound on the Triplet Loss for Improving the Efficiency of Deep Distance Metric Learning
Apr 18, 2019



We propose a method that substantially improves the efficiency of deep distance metric learning based on the optimization of the triplet loss function. One epoch of such training process based on a naive optimization of the triplet loss function has a run-time complexity O(N^3), where N is the number of training samples. Such optimization scales poorly, and the most common approach proposed to address this high complexity issue is based on sub-sampling the set of triplets needed for the training process. Another approach explored in the field relies on an ad-hoc linearization (in terms of N) of the triplet loss that introduces class centroids, which must be optimized using the whole training set for each mini-batch - this means that a naive implementation of this approach has run-time complexity O(N^2). This complexity issue is usually mitigated with poor, but computationally cheap, approximate centroid optimization methods. In this paper, we first propose a solid theory on the linearization of the triplet loss with the use of class centroids, where the main conclusion is that our new linear loss represents a tight upper-bound to the triplet loss. Furthermore, based on the theory above, we propose a training algorithm that no longer requires the centroid optimization step, which means that our approach is the first in the field with a guaranteed linear run-time complexity. We show that the training of deep distance metric learning methods using the proposed upper-bound is substantially faster than triplet-based methods, while producing competitive retrieval accuracy results on benchmark datasets (CUB-200-2011 and CAR196).
SDRSAC: Semidefinite-Based Randomized Approach for Robust Point Cloud Registration without Correspondences
Apr 14, 2019



This paper presents a novel randomized algorithm for robust point cloud registration without correspondences. Most existing registration approaches require a set of putative correspondences obtained by extracting invariant descriptors. However, such descriptors could become unreliable in noisy and contaminated settings. In these settings, methods that directly handle input point sets are preferable. Without correspondences, however, conventional randomized techniques require a very large number of samples in order to reach satisfactory solutions. In this paper, we propose a novel approach to address this problem. In particular, our work enables the use of randomized methods for point cloud registration without the need of putative correspondences. By considering point cloud alignment as a special instance of graph matching and employing an efficient semi-definite relaxation, we propose a novel sampling mechanism, in which the size of the sampled subsets can be larger-than-minimal. Our tight relaxation scheme enables fast rejection of the outliers in the sampled sets, resulting in high-quality hypotheses. We conduct extensive experiments to demonstrate that our approach outperforms other state-of-the-art methods. Importantly, our proposed method serves as a generic framework which can be extended to problems with known correspondences.
SASSE: Scalable and Adaptable 6-DOF Pose Estimation
Feb 05, 2019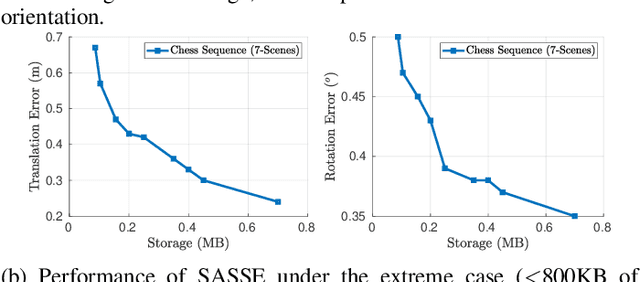
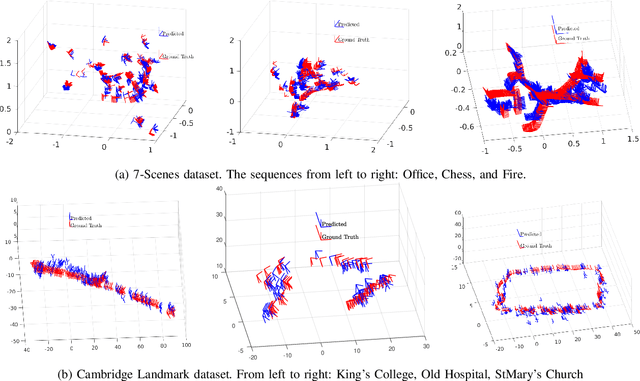
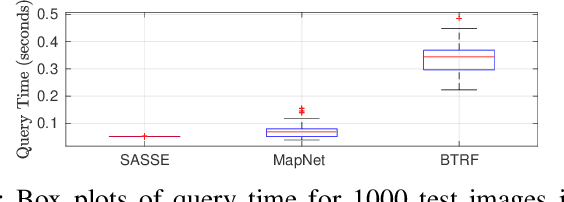

Visual localization has become a key enabling component of many place recognition and SLAM systems. Contemporary research has primarily focused on improving accuracy and precision-recall type metrics, with relatively little attention paid to a system's absolute storage scaling characteristics, its flexibility to adapt to available computational resources, and its longevity with respect to easily incorporating newly learned or hand-crafted image descriptors. Most significantly, improvement in one of these aspects typically comes at the cost of others: for example, a snapshot-based system that achieves sub-linear storage cost typically provides no metric pose estimation, or, a highly accurate pose estimation technique is often ossified in adapting to recent advances in appearance-invariant features. In this paper, we present a novel 6-DOF localization system that for the first time simultaneously achieves all the three characteristics: significantly sub-linear storage growth, agnosticism to image descriptors, and customizability to available storage and computational resources. The key features of our method are developed based on a novel adaptation of multiple-label learning, together with effective dimensional reduction and learning techniques that enable simple and efficient optimization. We evaluate our system on several large benchmarking datasets and provide detailed comparisons to state-of-the-art systems. The proposed method demonstrates competitive accuracy with existing pose estimation methods while achieving better sub-linear storage scaling, significantly reduced absolute storage requirements, and faster training and deployment speeds.