 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicitly Defined Layers in Neural Networks
Mar 03, 2020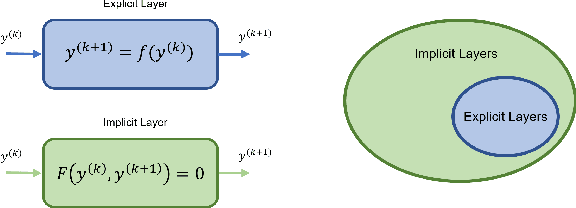

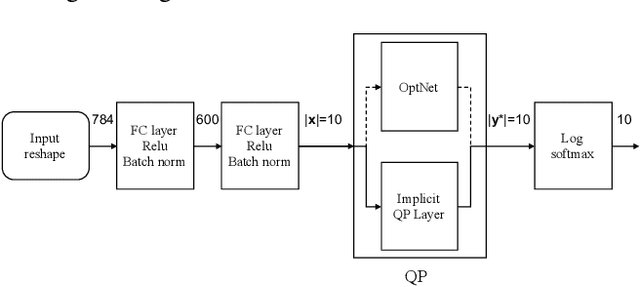
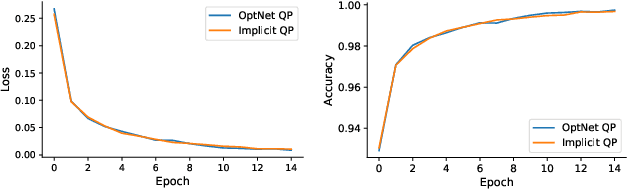
In conventional formulations of multilayer feedforward neural networks, the individual layers are customarily defined by explicit functions. In this paper we demonstrate that defining individual layers in a neural network \emph{implicitly} provide much richer representations over the standard explicit one, consequently enabling a vastly broader class of end-to-end trainable architectures. We present a general framework of implicitly defined layers, where much of the theoretical analysis of such layers can be addressed through the implicit function theorem. We also show how implicitly defined layers can be seamlessly incorporated into existing machine learning libraries. In particular with respect to current automatic differentiation techniques for use in backpropagation based training. Finally, we demonstrate the versatility and relevance of our proposed approach on a number of diverse example problems with promising results.
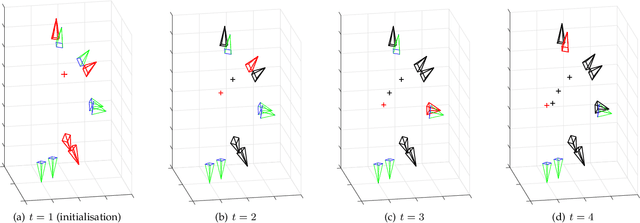
SASSE: Scalable and Adaptable 6-DOF Pose Estimation
Feb 05, 2019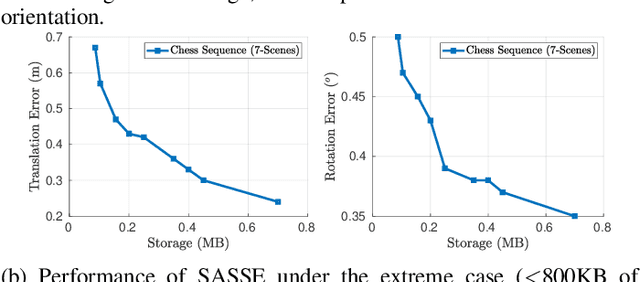
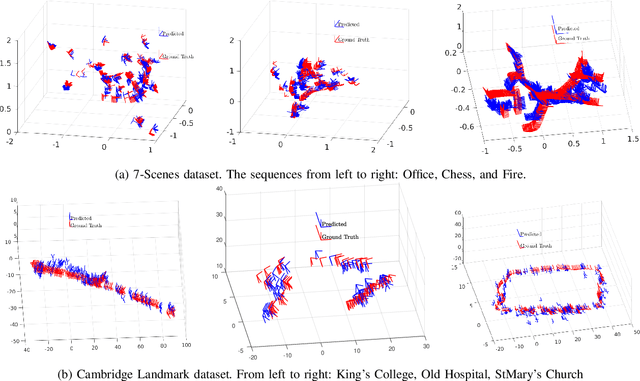
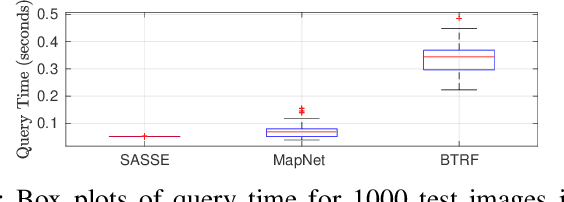

Visual localization has become a key enabling component of many place recognition and SLAM systems. Contemporary research has primarily focused on improving accuracy and precision-recall type metrics, with relatively little attention paid to a system's absolute storage scaling characteristics, its flexibility to adapt to available computational resources, and its longevity with respect to easily incorporating newly learned or hand-crafted image descriptors. Most significantly, improvement in one of these aspects typically comes at the cost of others: for example, a snapshot-based system that achieves sub-linear storage cost typically provides no metric pose estimation, or, a highly accurate pose estimation technique is often ossified in adapting to recent advances in appearance-invariant features. In this paper, we present a novel 6-DOF localization system that for the first time simultaneously achieves all the three characteristics: significantly sub-linear storage growth, agnosticism to image descriptors, and customizability to available storage and computational resources. The key features of our method are developed based on a novel adaptation of multiple-label learning, together with effective dimensional reduction and learning techniques that enable simple and efficient optimization. We evaluate our system on several large benchmarking datasets and provide detailed comparisons to state-of-the-art systems. The proposed method demonstrates competitive accuracy with existing pose estimation methods while achieving better sub-linear storage scaling, significantly reduced absolute storage requirements, and faster training and deployment speeds.
Coresets for Triangulation
Jul 18, 2017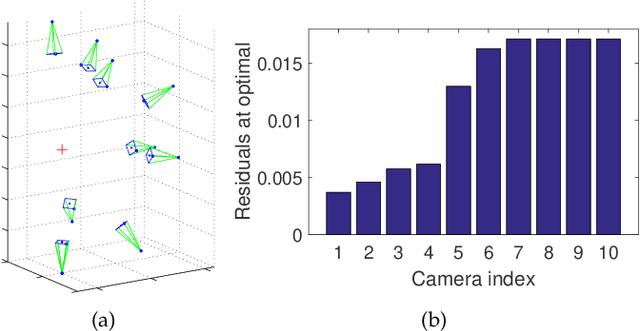
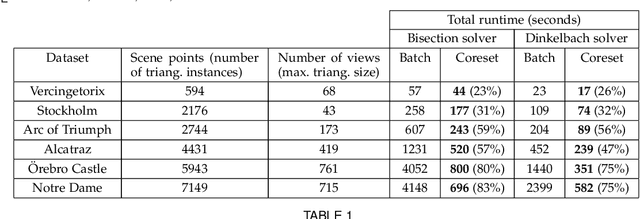

Multiple-view triangulation by $\ell_{\infty}$ minimisation has become established in computer vision. State-of-the-art $\ell_{\infty}$ triangulation algorithms exploit the quasiconvexity of the cost function to derive iterative update rules that deliver the global minimum. Such algorithms, however, can be computationally costly for large problem instances that contain many image measurements, e.g., from web-based photo sharing sites or long-term video recordings. In this paper, we prove that $\ell_{\infty}$ triangulation admits a coreset approximation scheme, which seeks small representative subsets of the input data called coresets. A coreset possesses the special property that the error of the $\ell_{\infty}$ solution on the coreset is within known bounds from the global minimum. We establish the necessary mathematical underpinnings of the coreset algorithm, specifically, by enacting the stopping criterion of the algorithm and proving that the resulting coreset gives the desired approximation accuracy. On large-scale triangulation problems, our method provides theoretically sound approximate solutions. Iterated until convergence, our coreset algorithm is also guaranteed to reach the true optimum. On practical datasets, we show that our technique can in fact attain the global minimiser much faster than current methods