 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compositional Shape Priors for Few-Shot 3D Reconstruction
Jun 16, 2021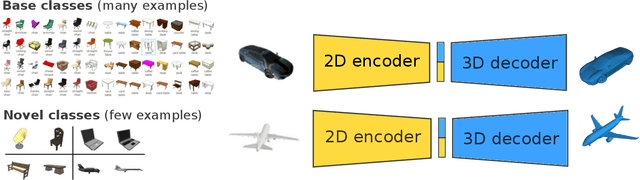
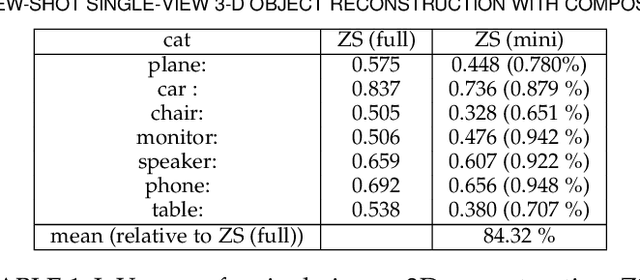
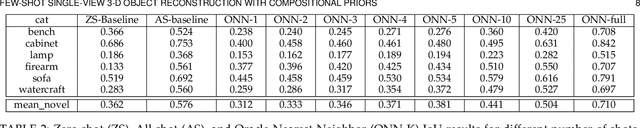
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. Recent work has challenged this belief, showing that, on standard benchmarks, complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per-category data. However, building large collections of 3D shapes for supervised training is a laborious process; a more realistic and less constraining task is inferring 3D shapes for categories with few available training examples, calling for a model that can successfully generalize to novel object classes. In this work we experimentally demonstrate that naive baselines fail in this few-shot learning setting, in which the network must learn informative shape priors for inference of new categories. We propose three ways to learn a class-specific global shape prior, directly from data. Using these techniques, we are able to capture multi-scale information about the 3D shape, and account for intra-class variability by virtue of an implicit compositional structure. Experiments on the popular ShapeNet dataset show that our method outperforms a zero-shot baseline by over 40%, and the current state-of-the-art by over 10%, in terms of relative performance, in the few-shot setting.
Rotation Coordinate Descent for Fast Globally Optimal Rotation Averaging
Mar 16, 2021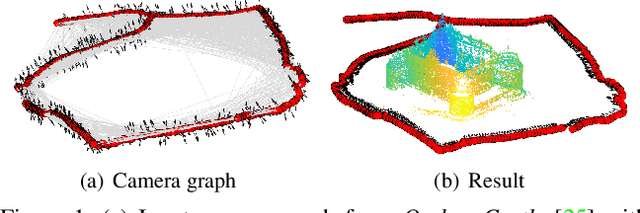
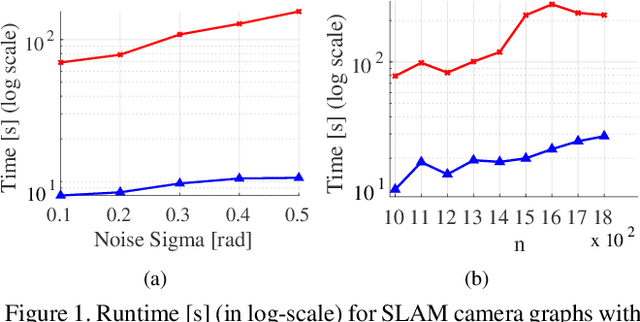
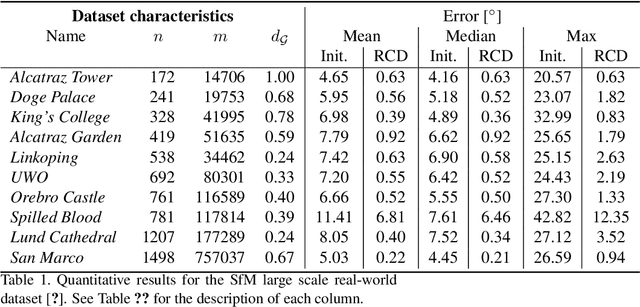
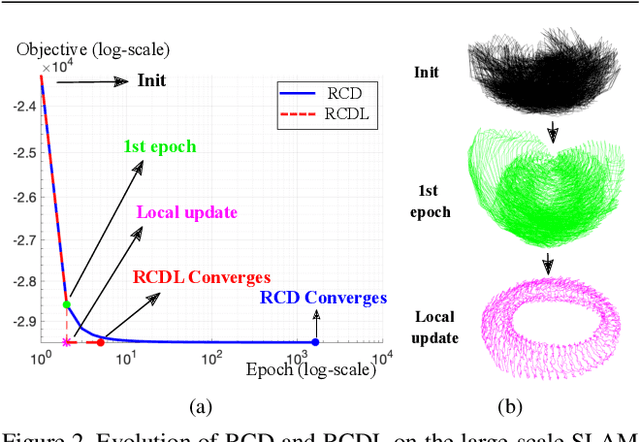
Under mild conditions on the noise level of the measurements, rotation averaging satisfies strong duality, which enables global solutions to be obtained via semidefinite programming (SDP) relaxation. However, generic solvers for SDP are rather slow in practice, even on rotation averaging instances of moderate size, thus developing specialised algorithms is vital. In this paper, we present a fast algorithm that achieves global optimality called rotation coordinate descent (RCD). Unlike block coordinate descent (BCD) which solves SDP by updating the semidefinite matrix in a row-by-row fashion, RCD directly maintains and updates all valid rotations throughout the iterations. This obviates the need to store a large dense semidefinite matrix. We mathematically prove the convergence of our algorithm and empirically show its superior efficiency over state-of-the-art global methods on a variety of problem configurations. Maintaining valid rotations also facilitates incorporating local optimisation routines for further speed-ups. Moreover, our algorithm is simple to implement; see supplementary material for a demonstration program.
Sparse Convolutions on Continuous Domains for Point Cloud and Event Stream Networks
Dec 02, 2020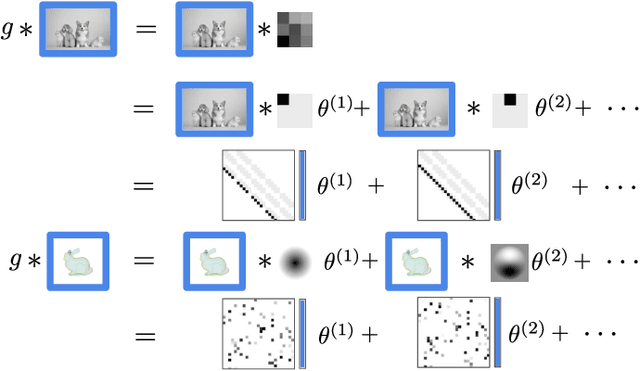
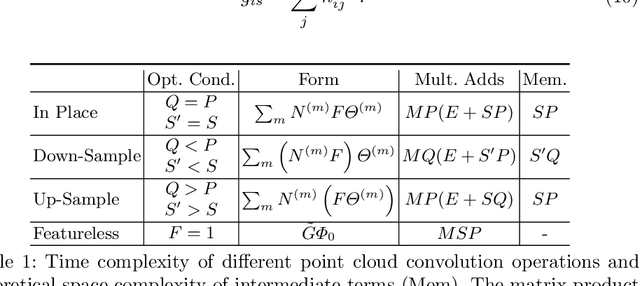
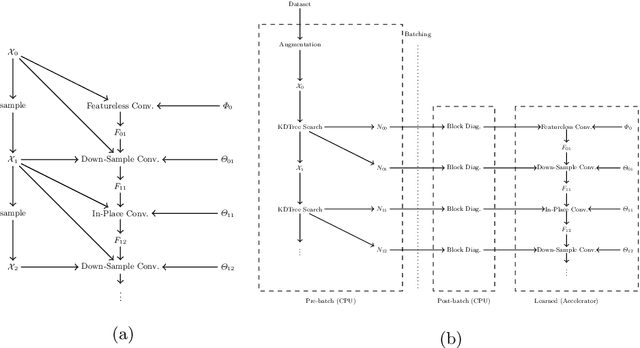
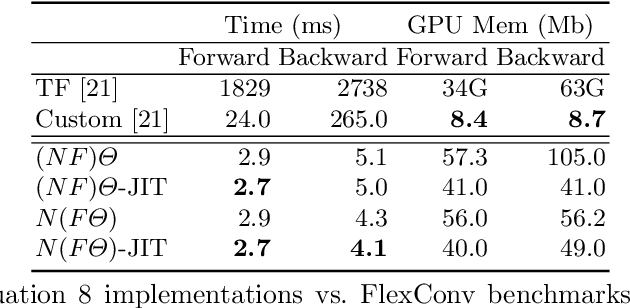
Image convolutions have been a cornerstone of a great number of deep learning advances in computer vision. The research community is yet to settle on an equivalent operator for sparse, unstructured continuous data like point clouds and event streams however. We present an elegant sparse matrix-based interpretation of the convolution operator for these cases, which is consistent with the mathematical definition of convolution and efficient during training. On benchmark point cloud classification problems we demonstrate networks built with these operations can train an order of magnitude or more faster than top existing methods, whilst maintaining comparable accuracy and requiring a tiny fraction of the memory. We also apply our operator to event stream processing, achieving state-of-the-art results on multiple tasks with streams of hundreds of thousands of events.
A Simple and Scalable Shape Representation for 3D Reconstruction
May 10, 2020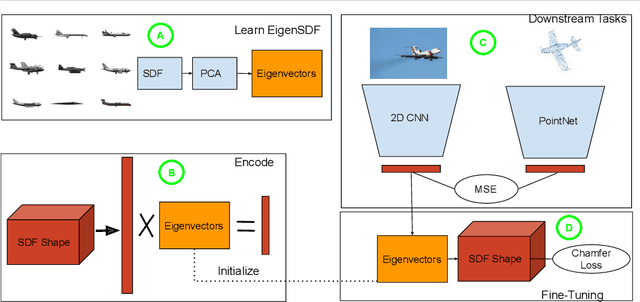
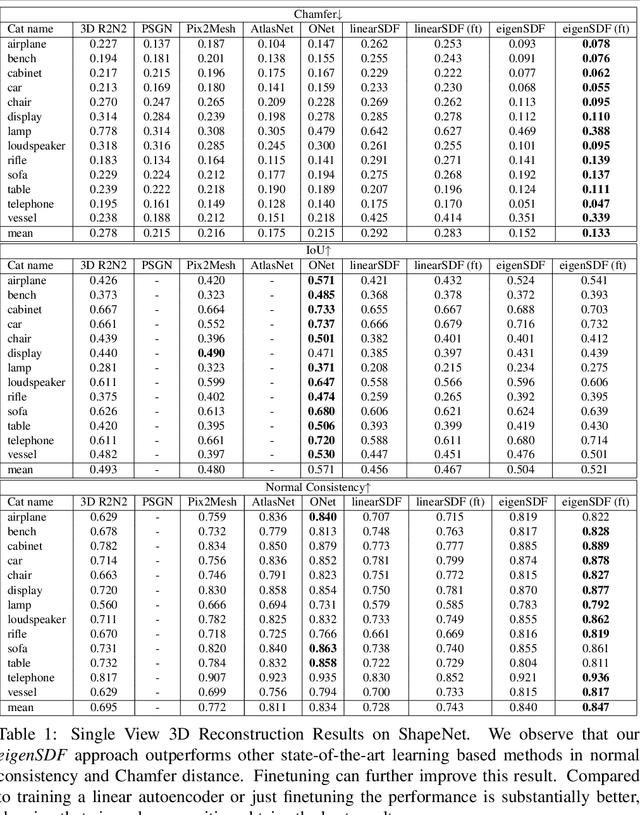
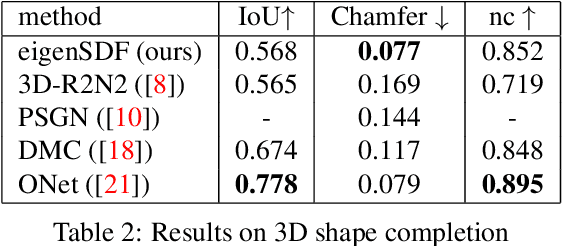
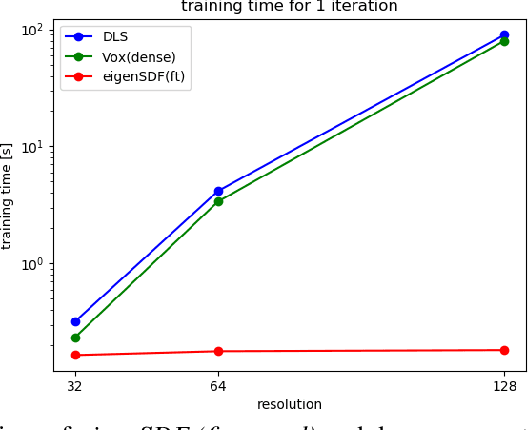
Deep learning applied to the reconstruction of 3D shapes has seen growing interest. A popular approach to 3D reconstruction and generation in recent years has been the CNN encoder-decoder model usually applied in voxel space. However, this often scales very poorly with the resolution limiting the effectiveness of these models. Several sophisticated alternatives for decoding to 3D shapes have been proposed typically relying on complex deep learning architectures for the decoder model. In this work, we show that this additional complexity is not necessary, and that we can actually obtain high quality 3D reconstruction using a linear decoder, obtained from principal component analysis on the signed distance function (SDF) of the surface. This approach allows easily scaling to larger resolutions. We show in multiple experiments that our approach is competitive with state-of-the-art methods. It also allows the decoder to be fine-tuned on the target task using a loss designed specifically for SDF transforms, obtaining further gains.
Few-Shot Single-View 3-D Object Reconstruction with Compositional Priors
May 03, 2020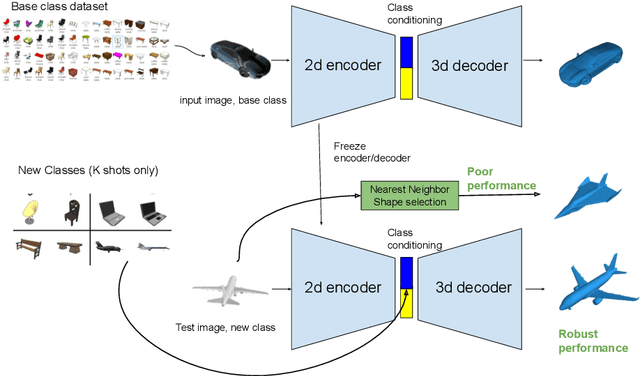
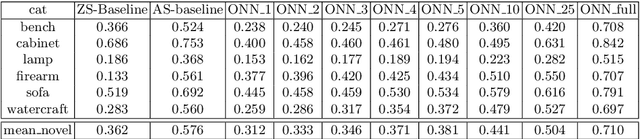
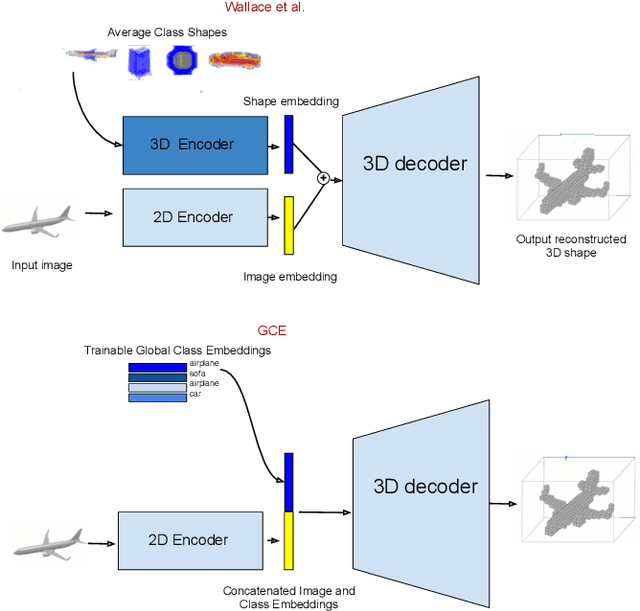
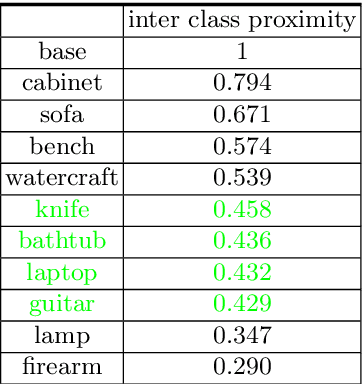
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. However, recent work has challenged this belief, showing that complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per category data in standard benchmarks. On the other hand settings where 3D shape must be inferred for new categories with few examples are more natural and require models that generalize about shapes. In this work we demonstrate experimentally that naive baselines do not apply when the goal is to learn to reconstruct novel objects using very few examples, and that in a \emph{few-shot} learning setting, the network must learn concepts that can be applied to new categories, avoiding rote memorization. To address deficiencies in existing approaches to this problem, we propose three approaches that efficiently integrate a class prior into a 3D reconstruction model, allowing to account for intra-class variability and imposing an implicit compositional structure that the model should learn. Experiments on the popular ShapeNet database demonstrate that our method significantly outperform existing baselines on this task in the few-shot setting.
Implicitly Defined Layers in Neural Networks
Mar 03, 2020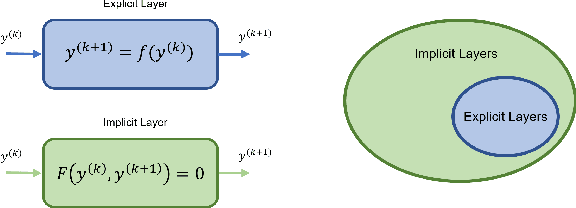

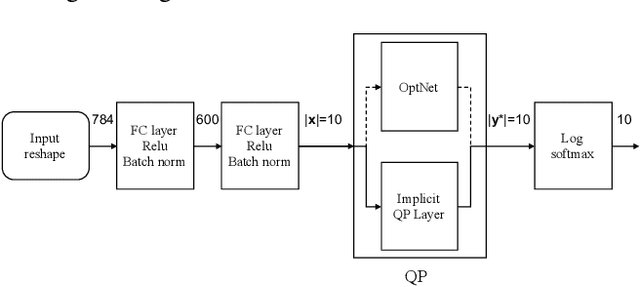
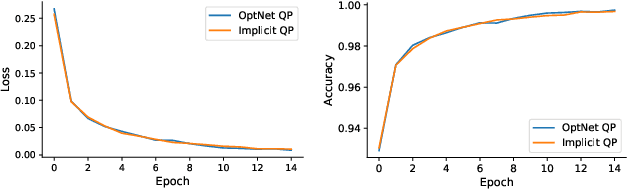
In conventional formulations of multilayer feedforward neural networks, the individual layers are customarily defined by explicit functions. In this paper we demonstrate that defining individual layers in a neural network \emph{implicitly} provide much richer representations over the standard explicit one, consequently enabling a vastly broader class of end-to-end trainable architectures. We present a general framework of implicitly defined layers, where much of the theoretical analysis of such layers can be addressed through the implicit function theorem. We also show how implicitly defined layers can be seamlessly incorporated into existing machine learning libraries. In particular with respect to current automatic differentiation techniques for use in backpropagation based training. Finally, we demonstrate the versatility and relevance of our proposed approach on a number of diverse example problems with promising results.
Visual SLAM: Why Bundle Adjust?
Feb 11, 2019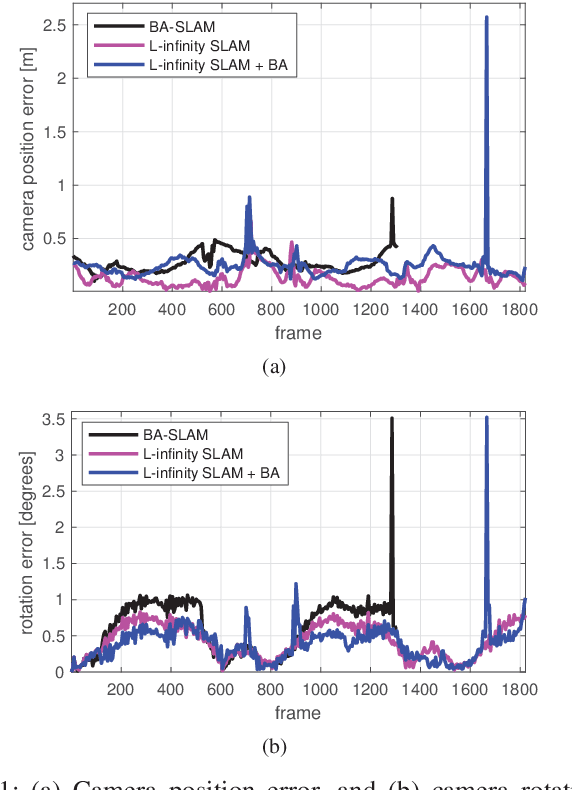
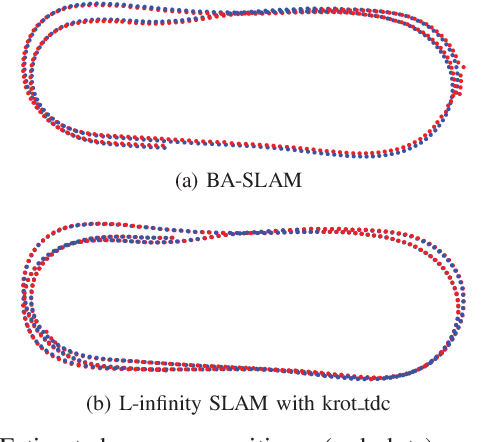

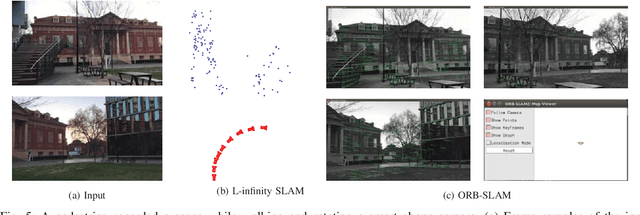
Bundle adjustment plays a vital role in feature-based monocular SLAM. In many modern SLAM pipelines, bundle adjustment is performed to estimate the 6DOF camera trajectory and 3D map (3D point cloud) from the input feature tracks. However, two fundamental weaknesses plague SLAM systems based on bundle adjustment. First, the need to carefully initialise bundle adjustment means that all variables, in particular the map, must be estimated as accurately as possible and maintained over time, which makes the overall algorithm cumbersome. Second, since estimating the 3D structure (which requires sufficient baseline) is inherent in bundle adjustment, the SLAM algorithm will encounter difficulties during periods of slow motion or pure rotational motion. We propose a different SLAM optimisation core: instead of bundle adjustment, we conduct rotation averaging to incrementally optimise only camera orientations. Given the orientations, we estimate the camera positions and 3D points via a quasi-convex formulation that can be solved efficiently and globally optimally. Our approach not only obviates the need to estimate and maintain the positions and 3D map at keyframe rate (which enables simpler SLAM systems), it is also more capable of handling slow motions or pure rotational motions.
SASSE: Scalable and Adaptable 6-DOF Pose Estimation
Feb 05, 2019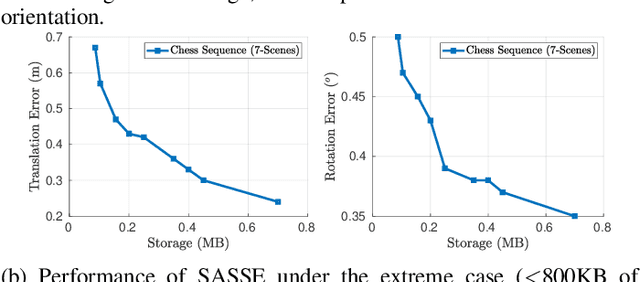
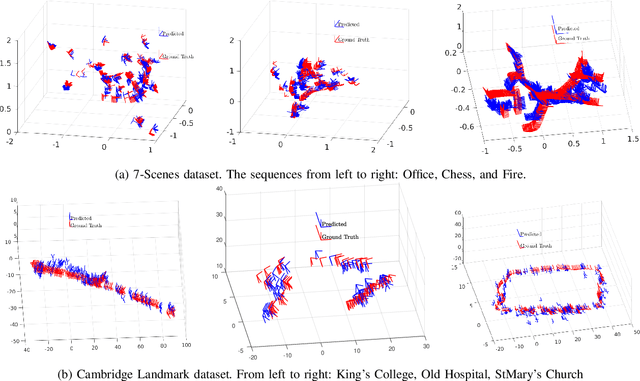
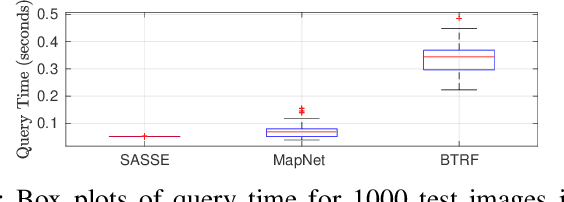

Visual localization has become a key enabling component of many place recognition and SLAM systems. Contemporary research has primarily focused on improving accuracy and precision-recall type metrics, with relatively little attention paid to a system's absolute storage scaling characteristics, its flexibility to adapt to available computational resources, and its longevity with respect to easily incorporating newly learned or hand-crafted image descriptors. Most significantly, improvement in one of these aspects typically comes at the cost of others: for example, a snapshot-based system that achieves sub-linear storage cost typically provides no metric pose estimation, or, a highly accurate pose estimation technique is often ossified in adapting to recent advances in appearance-invariant features. In this paper, we present a novel 6-DOF localization system that for the first time simultaneously achieves all the three characteristics: significantly sub-linear storage growth, agnosticism to image descriptors, and customizability to available storage and computational resources. The key features of our method are developed based on a novel adaptation of multiple-label learning, together with effective dimensional reduction and learning techniques that enable simple and efficient optimization. We evaluate our system on several large benchmarking datasets and provide detailed comparisons to state-of-the-art systems. The proposed method demonstrates competitive accuracy with existing pose estimation methods while achieving better sub-linear storage scaling, significantly reduced absolute storage requirements, and faster training and deployment speeds.
Deep Level Sets: Implicit Surface Representations for 3D Shape Inference
Jan 21, 2019
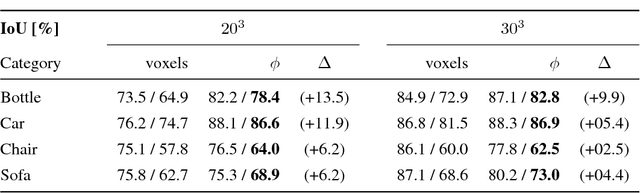


Existing 3D surface representation approaches are unable to accurately classify pixels and their orientation lying on the boundary of an object. Thus resulting in coarse representations which usually require post-processing steps to extract 3D surface meshes. To overcome this limitation, we propose an end-to-end trainable model that directly predicts implicit surface representations of arbitrary topology by optimising a novel geometric loss function. Specifically, we propose to represent the output as an oriented level set of a continuous embedding function, and incorporate this in a deep end-to-end learning framework by introducing a variational shape inference formulation. We investigate the benefits of our approach on the task of 3D surface prediction and demonstrate its ability to produce a more accurate reconstruction compared to voxel-based representations. We further show that our model is flexible and can be applied to a variety of shape inference problems.
Star Tracking using an Event Camera
Dec 07, 2018

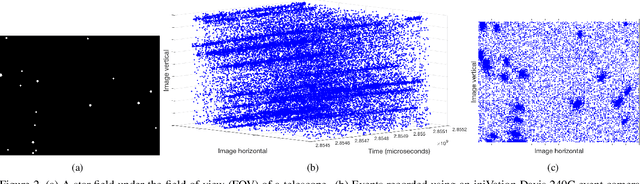
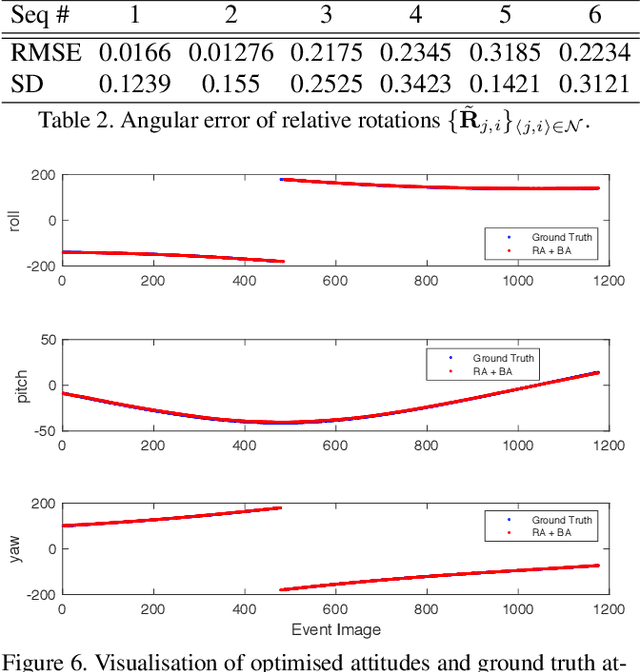
Star trackers are primarily optical devices that are used to estimate the attitude of a spacecraft by recognising and tracking star patterns. Currently, most star trackers use conventional optical sensors. In this application paper, we propose the usage of event sensors for star tracking. There are potentially two benefits of using event sensors for star tracking: lower power consumption and higher operating speeds. Our main contribution is to formulate an algorithmic pipeline for star tracking from event data that includes novel formulations of rotation averaging and bundle adjustment. In addition, we also release with this paper a dataset for star tracking using event cameras. With this work, we introduce the problem of star tracking using event cameras to the computer vision community, whose expertise in SLAM and geometric optimisation can be brought to bear on this commercially important application.