 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time CARFAC Cochlea Model Acceleration on FPGA for Underwater Acoustic Sensing Systems
Aug 11, 2025This paper presents a real-time, energy-efficient embedded system implementing an array of Cascade of Asymmetric Resonators with Fast-Acting Compression (CARFAC) cochlea models for underwater sound analysis. Built on the AMD Kria KV260 System-on-Module (SoM), the system integrates a Rust-based software framework on the processor for real-time interfacing and synchronization with multiple hydrophone inputs, and a hardware-accelerated implementation of the CARFAC models on a Field-Programmable Gate Array (FPGA) for real-time sound pre-processing. Compared to prior work, the CARFAC accelerator achieves improved scalability and processing speed while reducing resource usage through optimized time-multiplexing, pipelined design, and elimination of costly division circuits. Experimental results demonstrate 13.5% hardware utilization for a single 64-channel CARFAC instance and a whole board power consumption of 3.11 W when processing a 256 kHz input signal in real time.
Neuromorphic Retina: An FPGA-based Emulator
Jan 15, 2025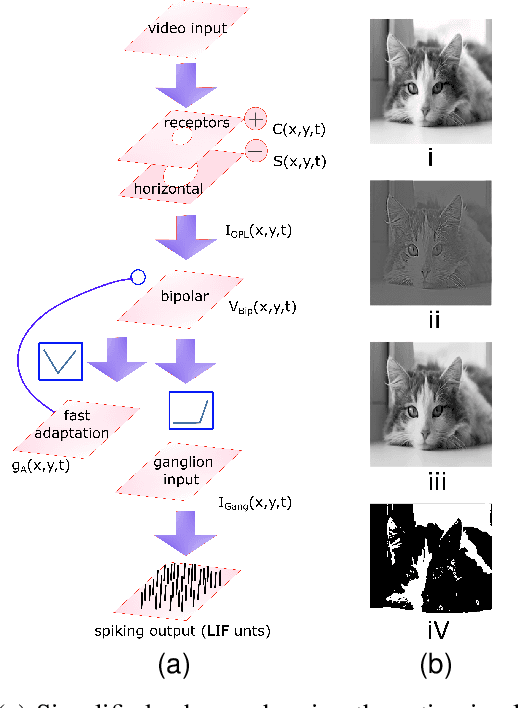

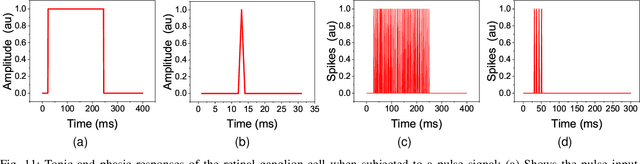
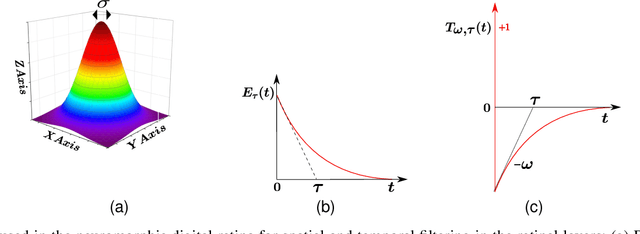
Implementing accurate models of the retina is a challenging task, particularly in the context of creating visual prosthetics and devices. Notwithstanding the presence of diverse artificial renditions of the retina, the imperative task persists to pursue a more realistic model. In this work, we are emulating a neuromorphic retina model on an FPGA. The key feature of this model is its powerful adaptation to luminance and contrast, which allows it to accurately emulate the sensitivity of the biological retina to changes in light levels. Phasic and tonic cells are realizable in the retina in the simplest way possible. Our FPGA implementation of the proposed biologically inspired digital retina, incorporating a receptive field with a center-surround structure, is reconfigurable and can support 128*128 pixel images at a frame rate of 200fps. It consumes 1720 slices, approximately 3.7k Look-Up Tables (LUTs), and Flip-Flops (FFs) on the FPGA. This implementation provides a high-performance, low-power, and small-area solution and could be a significant step forward in the development of biologically plausible retinal prostheses with enhanced information processing capabilities
An optimised deep spiking neural network architecture without gradients
Oct 12, 2021
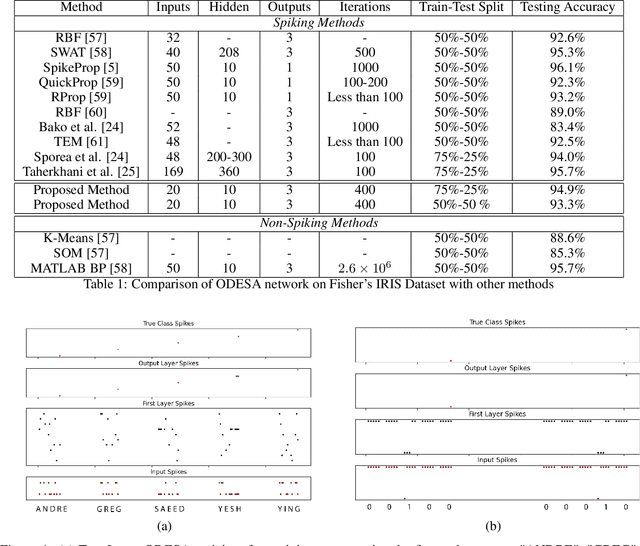
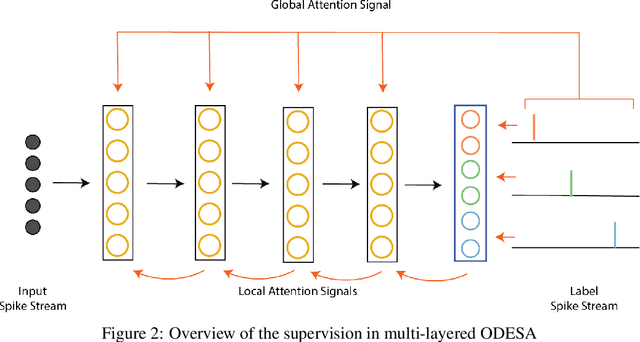

We present an end-to-end trainable modular event-driven neural architecture that uses local synaptic and threshold adaptation rules to perform transformations between arbitrary spatio-temporal spike patterns. The architecture represents a highly abstracted model of existing Spiking Neural Network (SNN) architectures. The proposed Optimized Deep Event-driven Spiking neural network Architecture (ODESA) can simultaneously learn hierarchical spatio-temporal features at multiple arbitrary time scales. ODESA performs online learning without the use of error back-propagation or the calculation of gradients. Through the use of simple local adaptive selection thresholds at each node, the network rapidly learns to appropriately allocate its neuronal resources at each layer for any given problem without using a real-valued error measure. These adaptive selection thresholds are the central feature of ODESA, ensuring network stability and remarkable robustness to noise as well as to the selection of initial system parameters. Network activations are inherently sparse due to a hard Winner-Take-All (WTA) constraint at each layer. We evaluate the architecture on existing spatio-temporal datasets, including the spike-encoded IRIS and TIDIGITS datasets, as well as a novel set of tasks based on International Morse Code that we created. These tests demonstrate the hierarchical spatio-temporal learning capabilities of ODESA. Through these tests, we demonstrate ODESA can optimally solve practical and highly challenging hierarchical spatio-temporal learning tasks with the minimum possible number of computing nodes.
Event-based Object Detection and Tracking for Space Situational Awareness
Nov 20, 2019

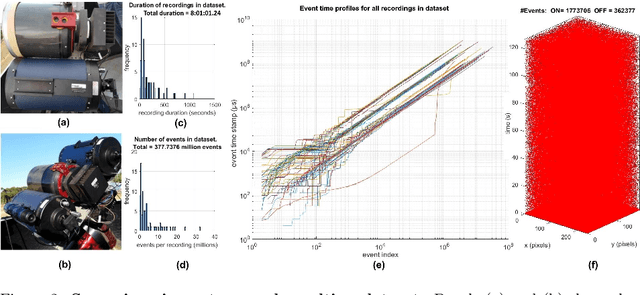

In this work, we present optical space imaging using an unconventional yet promising class of imaging devices known as neuromorphic event-based sensors. These devices, which are modeled on the human retina, do not operate with frames, but rather generate asynchronous streams of events in response to changes in log-illumination at each pixel. These devices are therefore extremely fast, do not have fixed exposure times, allow for imaging whilst the device is moving and enable low power space imaging during daytime as well as night without modification of the sensors. Recorded at multiple remote sites, we present the first event-based space imaging dataset including recordings from multiple event-based sensors from multiple providers, greatly lowering the barrier to entry for other researchers given the scarcity of such sensors and the expertise required to operate them. The dataset contains 236 separate recordings and 572 labeled resident space objects. The event-based imaging paradigm presents unique opportunities and challenges motivating the development of specialized event-based algorithms that can perform tasks such as detection and tracking in an event-based manner. Here we examine a range of such event-based algorithms for detection and tracking. The presented methods are designed specifically for space situational awareness applications and are evaluated in terms of accuracy and speed and suitability for implementation in neuromorphic hardware on remote or space-based imaging platforms.
Single-bit-per-weight deep convolutional neural networks without batch-normalization layers for embedded systems
Jul 22, 2019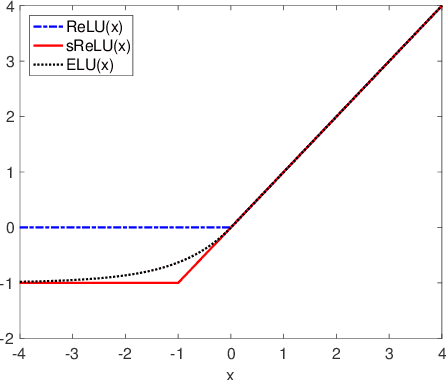
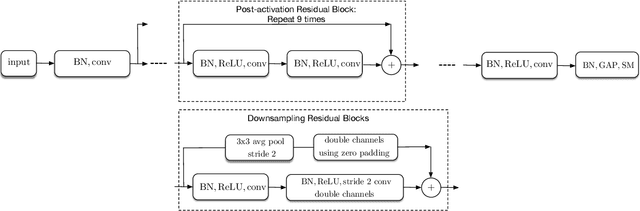
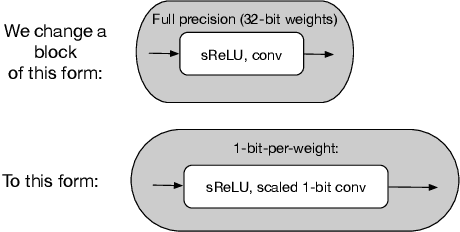
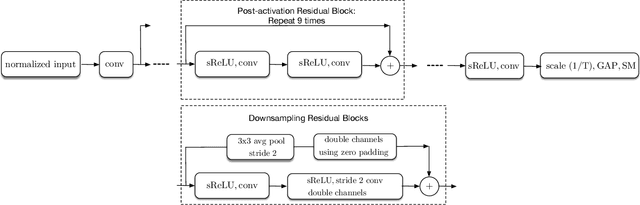
Batch-normalization (BN) layers are thought to be an integrally important layer type in today's state-of-the-art deep convolutional neural networks for computer vision tasks such as classification and detection. However, BN layers introduce complexity and computational overheads that are highly undesirable for training and/or inference on low-power custom hardware implementations of real-time embedded vision systems such as UAVs, robots and Internet of Things (IoT) devices. They are also problematic when batch sizes need to be very small during training, and innovations such as residual connections introduced more recently than BN layers could potentially have lessened their impact. In this paper we aim to quantify the benefits BN layers offer in image classification networks, in comparison with alternative choices. In particular, we study networks that use shifted-ReLU layers instead of BN layers. We found, following experiments with wide residual networks applied to the ImageNet, CIFAR 10 and CIFAR 100 image classification datasets, that BN layers do not consistently offer a significant advantage. We found that the accuracy margin offered by BN layers depends on the data set, the network size, and the bit-depth of weights. We conclude that in situations where BN layers are undesirable due to speed, memory or complexity costs, that using shifted-ReLU layers instead should be considered; we found they can offer advantages in all these areas, and often do not impose a significant accuracy cost.
Star Tracking using an Event Camera
Dec 07, 2018

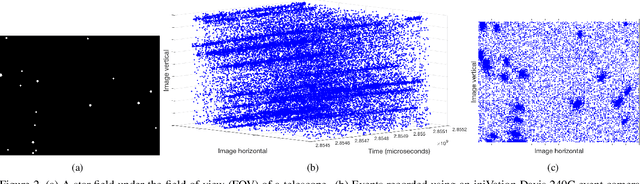
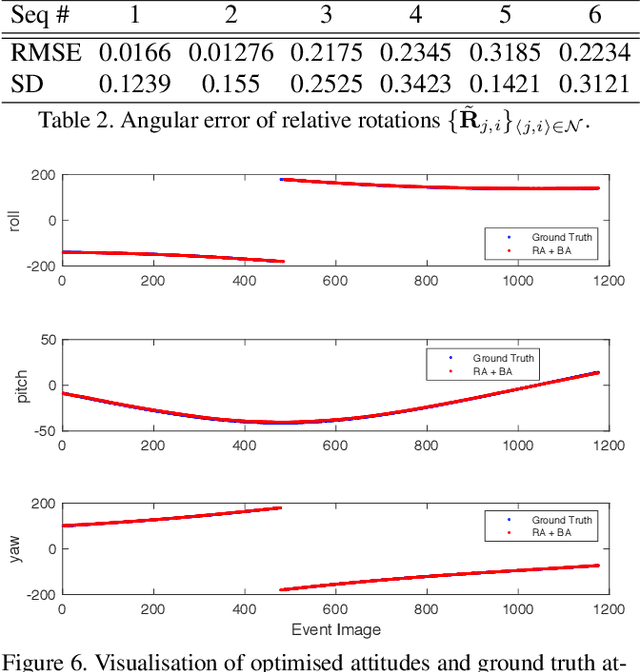
Star trackers are primarily optical devices that are used to estimate the attitude of a spacecraft by recognising and tracking star patterns. Currently, most star trackers use conventional optical sensors. In this application paper, we propose the usage of event sensors for star tracking. There are potentially two benefits of using event sensors for star tracking: lower power consumption and higher operating speeds. Our main contribution is to formulate an algorithmic pipeline for star tracking from event data that includes novel formulations of rotation averaging and bundle adjustment. In addition, we also release with this paper a dataset for star tracking using event cameras. With this work, we introduce the problem of star tracking using event cameras to the computer vision community, whose expertise in SLAM and geometric optimisation can be brought to bear on this commercially important application.
An FPGA-based Massively Parallel Neuromorphic Cortex Simulator
Mar 08, 2018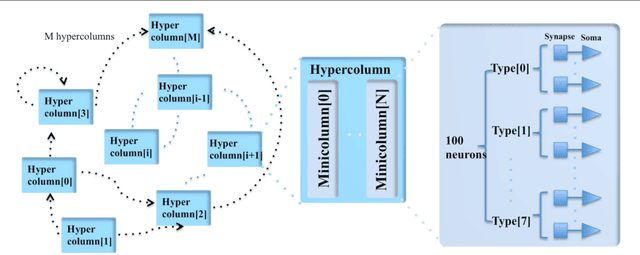

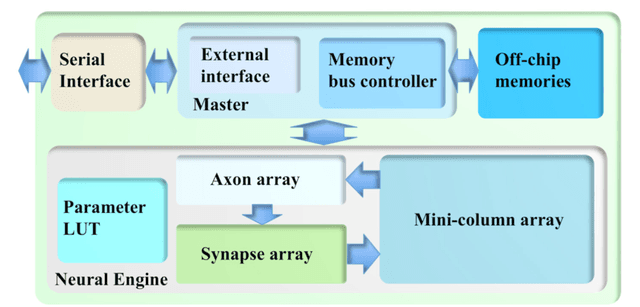

This paper presents a massively parallel and scalable neuromorphic cortex simulator designed for simulating large and structurally connected spiking neural networks, such as complex models of various areas of the cortex. The main novelty of this work is the abstraction of a neuromorphic architecture into clusters represented by minicolumns and hypercolumns, analogously to the fundamental structural units observed in neurobiology. Without this approach, simulating large-scale fully connected networks needs prohibitively large memory to store look-up tables for point-to-point connections. Instead, we use a novel architecture, based on the structural connectivity in the neocortex, such that all the required parameters and connections can be stored in on-chip memory. The cortex simulator can be easily reconfigured for simulating different neural networks without any change in hardware structure by programming the memory. A hierarchical communication scheme allows one neuron to have a fan-out of up to 200k neurons. As a proof-of-concept, an implementation on one Altera Stratix V FPGA was able to simulate 20 million to 2.6 billion leaky-integrate-and-fire (LIF) neurons in real time. We verified the system by emulating a simplified auditory cortex (with 100 million neurons). This cortex simulator achieved a low power dissipation of 1.62 {\mu}W per neuron. With the advent of commercially available FPGA boards, our system offers an accessible and scalable tool for the design, real-time simulation, and analysis of large-scale spiking neural networks.
Investigation of event-based memory surfaces for high-speed tracking, unsupervised feature extraction and object recognition
Nov 08, 2017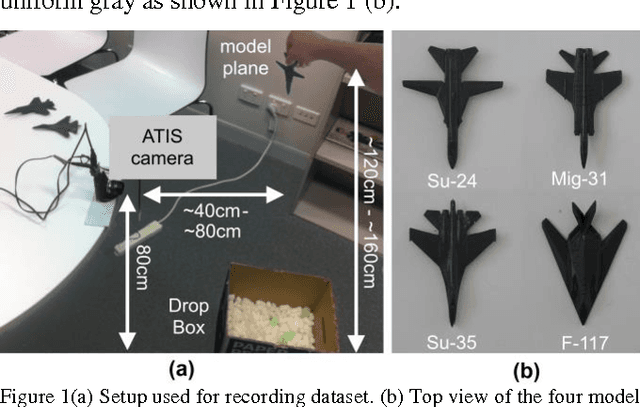
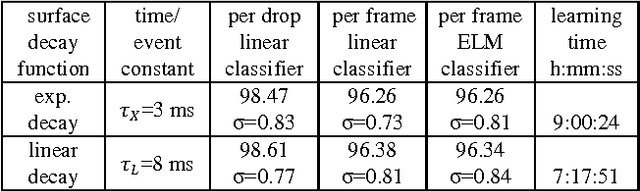

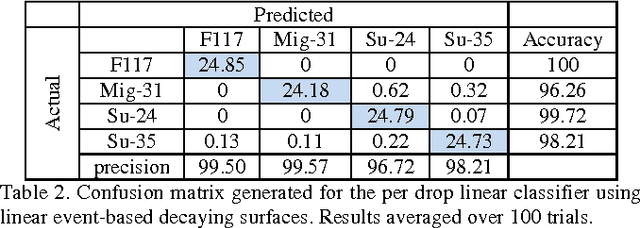
In this paper we compare event-based decaying and time based-decaying memory surfaces for high-speed eventbased tracking, feature extraction, and object classification using an event-based camera. The high-speed recognition task involves detecting and classifying model airplanes that are dropped free-hand close to the camera lens so as to generate a challenging dataset exhibiting significant variance in target velocity. This variance motivated the investigation of event-based decaying memory surfaces in comparison to time-based decaying memory surfaces to capture the temporal aspect of the event-based data. These surfaces are then used to perform unsupervised feature extraction, tracking and recognition. In order to generate the memory surfaces, event binning, linearly decaying kernels, and exponentially decaying kernels were investigated with exponentially decaying kernels found to perform best. Event-based decaying memory surfaces were found to outperform time-based decaying memory surfaces in recognition especially when invariance to target velocity was made a requirement. A range of network and receptive field sizes were investigated. The system achieves 98.75% recognition accuracy within 156 milliseconds of an airplane entering the field of view, using only twenty-five event-based feature extracting neurons in series with a linear classifier. By comparing the linear classifier results to an ELM classifier, we find that a small number of event-based feature extractors can effectively project the complex spatio-temporal event patterns of the dataset to an almost linearly separable representation in feature space.
An Online Learning Algorithm for Neuromorphic Hardware Implementation
Jul 30, 2017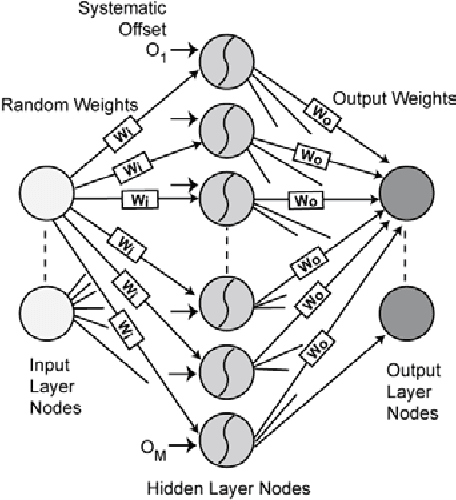

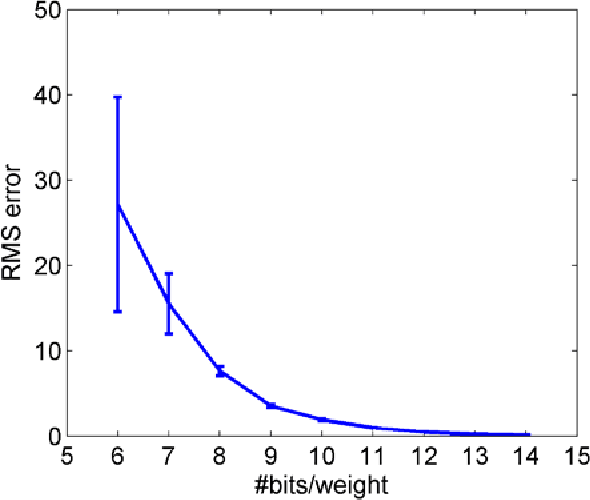

We propose a sign-based online learning (SOL) algorithm for a neuromorphic hardware framework called Trainable Analogue Block (TAB). The TAB framework utilises the principles of neural population coding, implying that it encodes the input stimulus using a large pool of nonlinear neurons. The SOL algorithm is a simple weight update rule that employs the sign of the hidden layer activation and the sign of the output error, which is the difference between the target output and the predicted output. The SOL algorithm is easily implementable in hardware, and can be used in any artificial neural network framework that learns weights by minimising a convex cost function. We show that the TAB framework can be trained for various regression tasks using the SOL algorithm.
A Reconfigurable Mixed-signal Implementation of a Neuromorphic ADC
Sep 03, 2015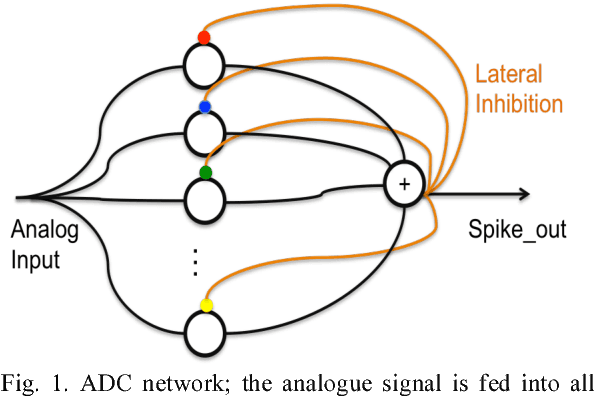
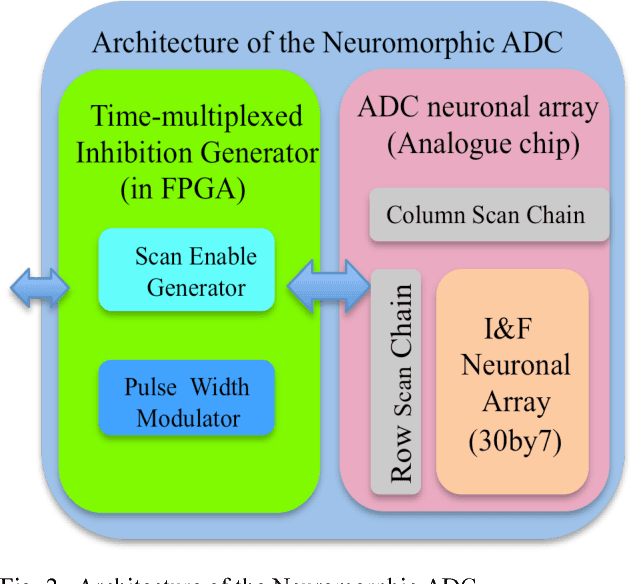
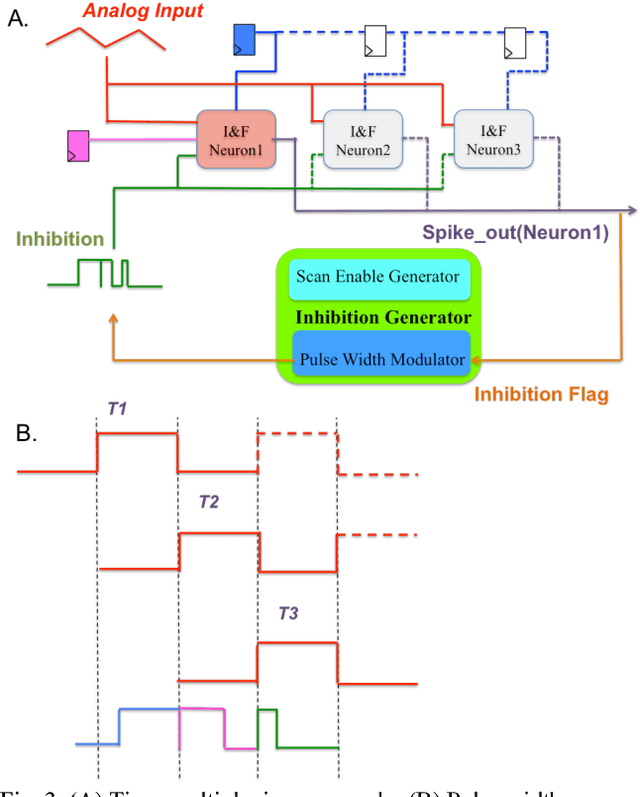
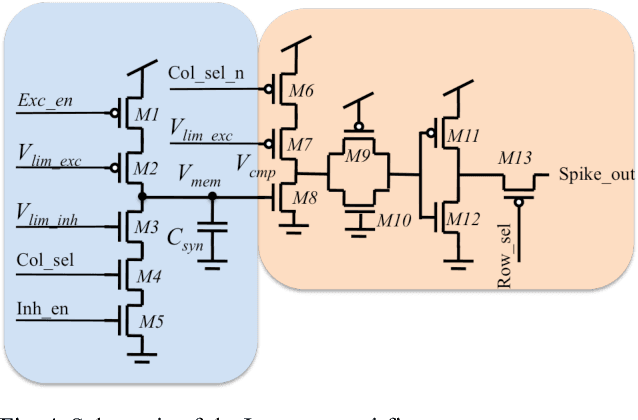
We present a neuromorphic Analogue-to-Digital Converter (ADC), which uses integrate-and-fire (I&F) neurons as the encoders of the analogue signal, with modulated inhibitions to decohere the neuronal spikes trains. The architecture consists of an analogue chip and a control module. The analogue chip comprises two scan chains and a twodimensional integrate-and-fire neuronal array. Individual neurons are accessed via the chains one by one without any encoder decoder or arbiter. The control module is implemented on an FPGA (Field Programmable Gate Array), which sends scan enable signals to the scan chains and controls the inhibition for individual neurons. Since the control module is implemented on an FPGA, it can be easily reconfigured. Additionally, we propose a pulse width modulation methodology for the lateral inhibition, which makes use of different pulse widths indicating different strengths of inhibition for each individual neuron to decohere neuronal spikes. Software simulations in this paper tested the robustness of the proposed ADC architecture to fixed random noise. A circuit simulation using ten neurons shows the performance and the feasibility of the architecture.