 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Routers, Switches and Interconnects Compute: A processing-in-interconnect Paradigm for Scalable Neuromorphic AI
Aug 27, 2025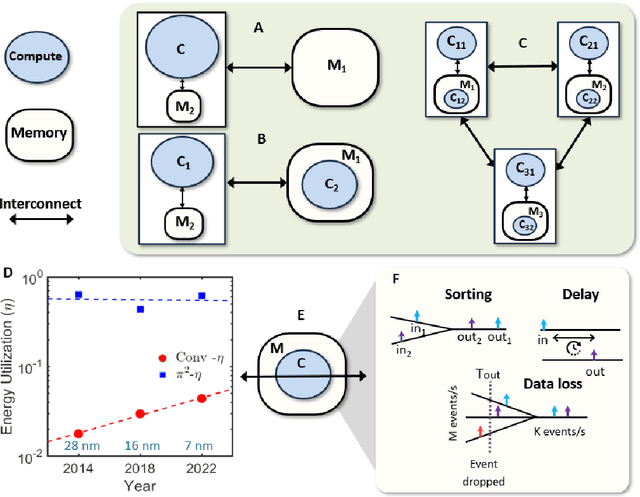
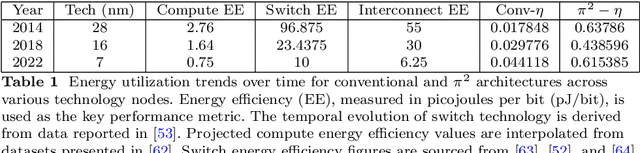
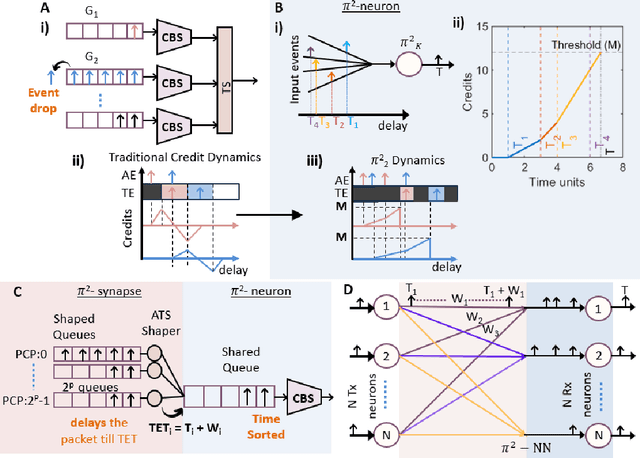

Routing, switching, and the interconnect fabric are essential for large-scale neuromorphic computing. While this fabric only plays a supporting role in the process of computing, for large AI workloads it ultimately determines energy consumption and speed. In this paper, we address this bottleneck by asking: (a) What computing paradigms are inherent in existing routing, switching, and interconnect systems, and how can they be used to implement a processing-in-Interconnect (\pi^2) computing paradigm? and (b) leveraging current and future interconnect trends, how will a \pi^2 system's performance scale compared to other neuromorphic architectures? For (a), we show that operations required for typical AI workloads can be mapped onto delays, causality, time-outs, packet drop, and broadcast operations -- primitives already implemented in packet-switching and packet-routing hardware. We show that existing buffering and traffic-shaping embedded algorithms can be leveraged to implement neuron models and synaptic operations. Additionally, a knowledge-distillation framework can train and cross-map well-established neural network topologies onto $\pi^2$ without degrading generalization performance. For (b), analytical modeling shows that, unlike other neuromorphic platforms, the energy scaling of $\pi^2$ improves with interconnect bandwidth and energy efficiency. We predict that by leveraging trends in interconnect technology, a \pi^2 architecture can be more easily scaled to execute brain-scale AI inference workloads with power consumption levels in the range of hundreds of watts.
EventSSEG: Event-driven Self-Supervised Segmentation with Probabilistic Attention
Aug 20, 2025Road segmentation is pivotal for autonomous vehicles, yet achieving low latency and low compute solutions using frame based cameras remains a challenge. Event cameras offer a promising alternative. To leverage their low power sensing, we introduce EventSSEG, a method for road segmentation that uses event only computing and a probabilistic attention mechanism. Event only computing poses a challenge in transferring pretrained weights from the conventional camera domain, requiring abundant labeled data, which is scarce. To overcome this, EventSSEG employs event-based self supervised learning, eliminating the need for extensive labeled data. Experiments on DSEC-Semantic and DDD17 show that EventSSEG achieves state of the art performance with minimal labeled events. This approach maximizes event cameras capabilities and addresses the lack of labeled events.
HOMI: Ultra-Fast EdgeAI platform for Event Cameras
Aug 18, 2025Event cameras offer significant advantages for edge robotics applications due to their asynchronous operation and sparse, event-driven output, making them well-suited for tasks requiring fast and efficient closed-loop control, such as gesture-based human-robot interaction. Despite this potential, existing event processing solutions remain limited, often lacking complete end-to-end implementations, exhibiting high latency, and insufficiently exploiting event data sparsity. In this paper, we present HOMI, an ultra-low latency, end-to-end edge AI platform comprising a Prophesee IMX636 event sensor chip with an Xilinx Zynq UltraScale+MPSoC FPGA chip, deploying an in-house developed AI accelerator. We have developed hardware-optimized pre-processing pipelines supporting both constant-time and constant-event modes for histogram accumulation, linear and exponential time surfaces. Our general-purpose implementation caters to both accuracy-driven and low-latency applications. HOMI achieves 94% accuracy on the DVS Gesture dataset as a use case when configured for high accuracy operation and provides a throughput of 1000 fps for low-latency configuration. The hardware-optimised pipeline maintains a compact memory footprint and utilises only 33% of the available LUT resources on the FPGA, leaving ample headroom for further latency reduction, model parallelisation, multi-task deployments, or integration of more complex architectures.
Neural Signal Compression using RAMAN tinyML Accelerator for BCI Applications
Apr 09, 2025High-quality, multi-channel neural recording is indispensable for neuroscience research and clinical applications. Large-scale brain recordings often produce vast amounts of data that must be wirelessly transmitted for subsequent offline analysis and decoding, especially in brain-computer interfaces (BCIs) utilizing high-density intracortical recordings with hundreds or thousands of electrodes. However, transmitting raw neural data presents significant challenges due to limited communication bandwidth and resultant excessive heating. To address this challenge, we propose a neural signal compression scheme utilizing Convolutional Autoencoders (CAEs), which achieves a compression ratio of up to 150 for compressing local field potentials (LFPs). The CAE encoder section is implemented on RAMAN, an energy-efficient tinyML accelerator designed for edge computing, and subsequently deployed on an Efinix Ti60 FPGA with 37.3k LUTs and 8.6k register utilization. RAMAN leverages sparsity in activation and weights through zero skipping, gating, and weight compression techniques. Additionally, we employ hardware-software co-optimization by pruning CAE encoder model parameters using a hardware-aware balanced stochastic pruning strategy, resolving workload imbalance issues and eliminating indexing overhead to reduce parameter storage requirements by up to 32.4%. Using the proposed compact depthwise separable convolutional autoencoder (DS-CAE) model, the compressed neural data from RAMAN is reconstructed offline with superior signal-to-noise and distortion ratios (SNDR) of 22.6 dB and 27.4 dB, along with R2 scores of 0.81 and 0.94, respectively, evaluated on two monkey neural recordings.
Neuromorphic Cameras in Astronomy: Unveiling the Future of Celestial Imaging Beyond Conventional Limits
Mar 20, 2025To deepen our understanding of optical astronomy, we must advance imaging technology to overcome conventional frame-based cameras' limited dynamic range and temporal resolution. Our Perspective paper examines how neuromorphic cameras can effectively address these challenges. Drawing inspiration from the human retina, neuromorphic cameras excel in speed and high dynamic range by utilizing asynchronous pixel operation and logarithmic photocurrent conversion, making them highly effective for celestial imaging. We use 1300 mm terrestrial telescope to demonstrate the neuromorphic camera's ability to simultaneously capture faint and bright celestial sources while preventing saturation effects. We illustrate its photometric capabilities through aperture photometry of a star field with faint stars. Detection of the faint gas cloud structure of the Trapezium cluster during a full moon night highlights the camera's high dynamic range, effectively mitigating static glare from lunar illumination. Our investigations also include detecting meteorite passing near the Moon and Earth, as well as imaging satellites and anthropogenic debris with exceptionally high temporal resolution using a 200mm telescope. Our observations show the immense potential of neuromorphic cameras in advancing astronomical optical imaging and pushing the boundaries of observational astronomy.
Neuromorphic Retina: An FPGA-based Emulator
Jan 15, 2025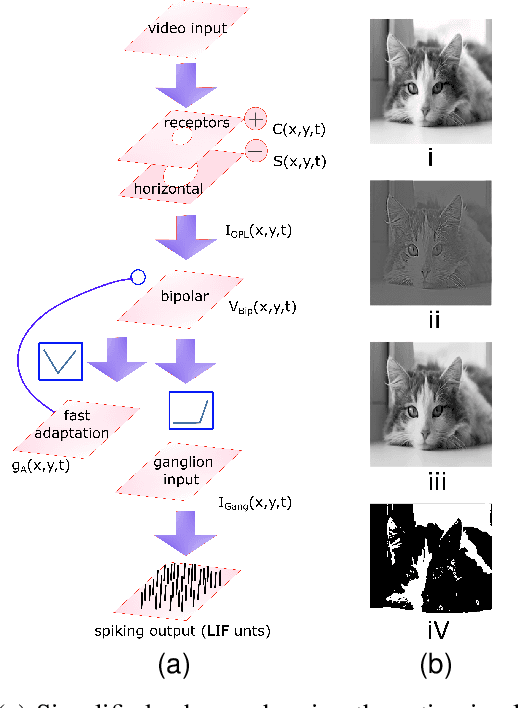

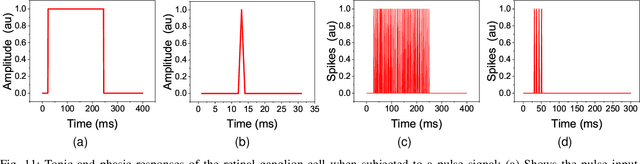
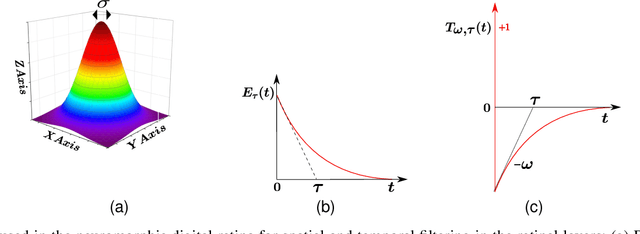
Implementing accurate models of the retina is a challenging task, particularly in the context of creating visual prosthetics and devices. Notwithstanding the presence of diverse artificial renditions of the retina, the imperative task persists to pursue a more realistic model. In this work, we are emulating a neuromorphic retina model on an FPGA. The key feature of this model is its powerful adaptation to luminance and contrast, which allows it to accurately emulate the sensitivity of the biological retina to changes in light levels. Phasic and tonic cells are realizable in the retina in the simplest way possible. Our FPGA implementation of the proposed biologically inspired digital retina, incorporating a receptive field with a center-surround structure, is reconfigurable and can support 128*128 pixel images at a frame rate of 200fps. It consumes 1720 slices, approximately 3.7k Look-Up Tables (LUTs), and Flip-Flops (FFs) on the FPGA. This implementation provides a high-performance, low-power, and small-area solution and could be a significant step forward in the development of biologically plausible retinal prostheses with enhanced information processing capabilities
KALAM: toolKit for Automating high-Level synthesis of Analog computing systeMs
Oct 30, 2024



Diverse computing paradigms have emerged to meet the growing needs for intelligent energy-efficient systems. The Margin Propagation (MP) framework, being one such initiative in the analog computing domain, stands out due to its scalability across biasing conditions, temperatures, and diminishing process technology nodes. However, the lack of digital-like automation tools for designing analog systems (including that of MP analog) hinders their adoption for designing large systems. The inherent scalability and modularity of MP systems present a unique opportunity in this regard. This paper introduces KALAM (toolKit for Automating high-Level synthesis of Analog computing systeMs), which leverages factor graphs as the foundational paradigm for synthesizing MP-based analog computing systems. Factor graphs are the basis of various signal processing tasks and, when coupled with MP, can be used to design scalable and energy-efficient analog signal processors. Using Python scripting language, the KALAM automation flow translates an input factor graph to its equivalent SPICE-compatible circuit netlist that can be used to validate the intended functionality. KALAM also allows the integration of design optimization strategies such as precision tuning, variable elimination, and mathematical simplification. We demonstrate KALAM's versatility for tasks such as Bayesian inference, Low-Density Parity Check (LDPC) decoding, and Artificial Neural Networks (ANN). Simulation results of the netlists align closely with software implementations, affirming the efficacy of our proposed automation tool.
Low-latency machine learning FPGA accelerator for multi-qubit state discrimination
Jul 04, 2024



Measuring a qubit is a fundamental yet error prone operation in quantum computing. These errors can stem from various sources such as crosstalk, spontaneous state-transitions, and excitation caused by the readout pulse. In this work, we utilize an integrated approach to deploy neural networks (NN) on to field programmable gate arrays (FPGA). We demonstrate that it is practical to design and implement a fully connected neural network accelerator for frequency-multiplexed readout balancing computational complexity with low latency requirements without significant loss in accuracy. The neural network is implemented by quantization of weights, activation functions, and inputs. The hardware accelerator performs frequency-multiplexed readout of 5 superconducting qubits in less than 50 ns on RFSoC ZCU111 FPGA which is first of its kind in the literature. These modules can be implemented and integrated in existing Quantum control and readout platforms using a RFSoC ZCU111 ready for experimental deployment.
Margin Propagation based XOR-SAT Solvers for Decoding of LDPC Codes
Feb 07, 2024Decoding of Low-Density Parity Check (LDPC) codes can be viewed as a special case of XOR-SAT problems, for which low-computational complexity bit-flipping algorithms have been proposed in the literature. However, a performance gap exists between the bit-flipping LDPC decoding algorithms and the benchmark LDPC decoding algorithms, such as the Sum-Product Algorithm (SPA). In this paper, we propose an XOR-SAT solver using log-sum-exponential functions and demonstrate its advantages for LDPC decoding. This is then approximated using the Margin Propagation formulation to attain a low-complexity LDPC decoder. The proposed algorithm uses soft information to decide the bit-flips that maximize the number of parity check constraints satisfied over an optimization function. The proposed solver can achieve results that are within $0.1$dB of the Sum-Product Algorithm for the same number of code iterations. It is also at least 10x lesser than other Gradient-Descent Bit Flipping decoding algorithms, which are also bit-flipping algorithms based on optimization functions. The approximation using the Margin Propagation formulation does not require any multipliers, resulting in significantly lower computational complexity than other soft-decision Bit-Flipping LDPC decoders.
RAMAN: A Re-configurable and Sparse tinyML Accelerator for Inference on Edge
Jun 10, 2023


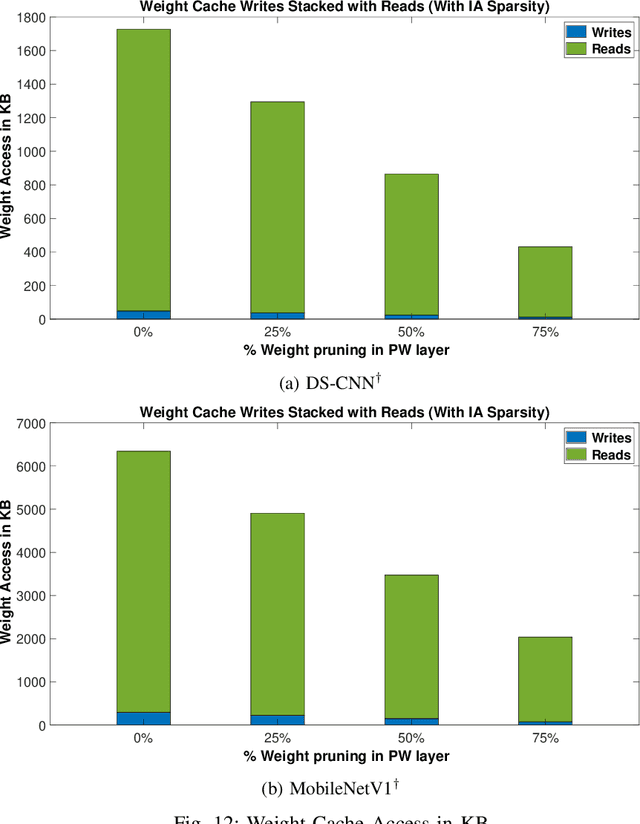
Deep Neural Network (DNN) based inference at the edge is challenging as these compute and data-intensive algorithms need to be implemented at low cost and low power while meeting the latency constraints of the target applications. Sparsity, in both activations and weights inherent to DNNs, is a key knob to leverage. In this paper, we present RAMAN, a Re-configurable and spArse tinyML Accelerator for infereNce on edge, architected to exploit the sparsity to reduce area (storage), power as well as latency. RAMAN can be configured to support a wide range of DNN topologies - consisting of different convolution layer types and a range of layer parameters (feature-map size and the number of channels). RAMAN can also be configured to support accuracy vs power/latency tradeoffs using techniques deployed at compile-time and run-time. We present the salient features of the architecture, provide implementation results and compare the same with the state-of-the-art. RAMAN employs novel dataflow inspired by Gustavson's algorithm that has optimal input activation (IA) and output activation (OA) reuse to minimize memory access and the overall data movement cost. The dataflow allows RAMAN to locally reduce the partial sum (Psum) within a processing element array to eliminate the Psum writeback traffic. Additionally, we suggest a method to reduce peak activation memory by overlapping IA and OA on the same memory space, which can reduce storage requirements by up to 50%. RAMAN was implemented on a low-power and resource-constrained Efinix Ti60 FPGA with 37.2K LUTs and 8.6K register utilization. RAMAN processes all layers of the MobileNetV1 model at 98.47 GOp/s/W and the DS-CNN model at 79.68 GOp/s/W by leveraging both weight and activation sparsity.