 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Routers, Switches and Interconnects Compute: A processing-in-interconnect Paradigm for Scalable Neuromorphic AI
Aug 27, 2025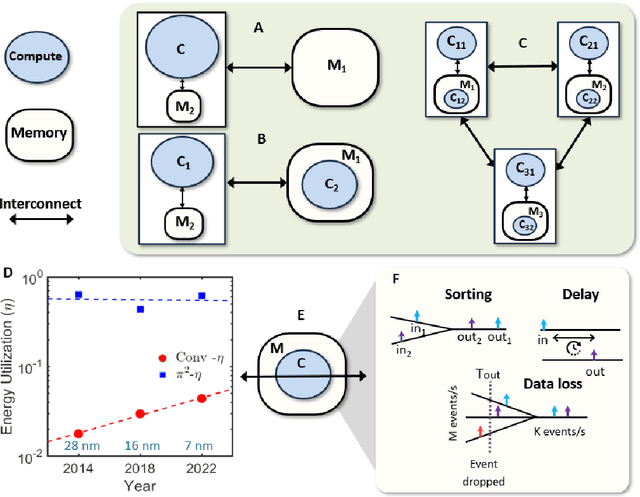
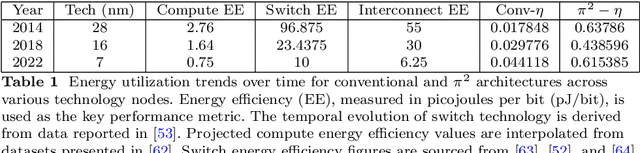
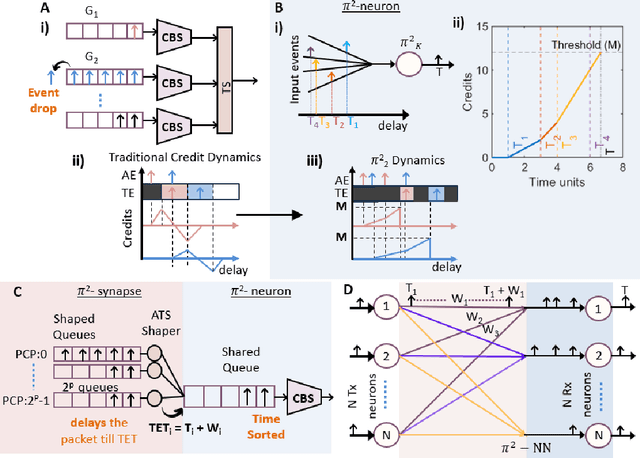

Routing, switching, and the interconnect fabric are essential for large-scale neuromorphic computing. While this fabric only plays a supporting role in the process of computing, for large AI workloads it ultimately determines energy consumption and speed. In this paper, we address this bottleneck by asking: (a) What computing paradigms are inherent in existing routing, switching, and interconnect systems, and how can they be used to implement a processing-in-Interconnect (\pi^2) computing paradigm? and (b) leveraging current and future interconnect trends, how will a \pi^2 system's performance scale compared to other neuromorphic architectures? For (a), we show that operations required for typical AI workloads can be mapped onto delays, causality, time-outs, packet drop, and broadcast operations -- primitives already implemented in packet-switching and packet-routing hardware. We show that existing buffering and traffic-shaping embedded algorithms can be leveraged to implement neuron models and synaptic operations. Additionally, a knowledge-distillation framework can train and cross-map well-established neural network topologies onto $\pi^2$ without degrading generalization performance. For (b), analytical modeling shows that, unlike other neuromorphic platforms, the energy scaling of $\pi^2$ improves with interconnect bandwidth and energy efficiency. We predict that by leveraging trends in interconnect technology, a \pi^2 architecture can be more easily scaled to execute brain-scale AI inference workloads with power consumption levels in the range of hundreds of watts.
KALAM: toolKit for Automating high-Level synthesis of Analog computing systeMs
Oct 30, 2024



Diverse computing paradigms have emerged to meet the growing needs for intelligent energy-efficient systems. The Margin Propagation (MP) framework, being one such initiative in the analog computing domain, stands out due to its scalability across biasing conditions, temperatures, and diminishing process technology nodes. However, the lack of digital-like automation tools for designing analog systems (including that of MP analog) hinders their adoption for designing large systems. The inherent scalability and modularity of MP systems present a unique opportunity in this regard. This paper introduces KALAM (toolKit for Automating high-Level synthesis of Analog computing systeMs), which leverages factor graphs as the foundational paradigm for synthesizing MP-based analog computing systems. Factor graphs are the basis of various signal processing tasks and, when coupled with MP, can be used to design scalable and energy-efficient analog signal processors. Using Python scripting language, the KALAM automation flow translates an input factor graph to its equivalent SPICE-compatible circuit netlist that can be used to validate the intended functionality. KALAM also allows the integration of design optimization strategies such as precision tuning, variable elimination, and mathematical simplification. We demonstrate KALAM's versatility for tasks such as Bayesian inference, Low-Density Parity Check (LDPC) decoding, and Artificial Neural Networks (ANN). Simulation results of the netlists align closely with software implementations, affirming the efficacy of our proposed automation tool.
ON-OFF Neuromorphic ISING Machines using Fowler-Nordheim Annealers
Jun 07, 2024We introduce NeuroSA, a neuromorphic architecture specifically designed to ensure asymptotic convergence to the ground state of an Ising problem using an annealing process that is governed by the physics of quantum mechanical tunneling using Fowler-Nordheim (FN). The core component of NeuroSA consists of a pair of asynchronous ON-OFF neurons, which effectively map classical simulated annealing (SA) dynamics onto a network of integrate-and-fire (IF) neurons. The threshold of each ON-OFF neuron pair is adaptively adjusted by an FN annealer which replicates the optimal escape mechanism and convergence of SA, particularly at low temperatures. To validate the effectiveness of our neuromorphic Ising machine, we systematically solved various benchmark MAX-CUT combinatorial optimization problems. Across multiple runs, NeuroSA consistently generates solutions that approach the state-of-the-art level with high accuracy (greater than 99%), and without any graph-specific hyperparameter tuning. For practical illustration, we present results from an implementation of NeuroSA on the SpiNNaker2 platform, highlighting the feasibility of mapping our proposed architecture onto a standard neuromorphic accelerator platform.
Energy-efficiency Limits on Training AI Systems using Learning-in-Memory
Feb 21, 2024Learning-in-memory (LIM) is a recently proposed paradigm to overcome fundamental memory bottlenecks in training machine learning systems. While compute-in-memory (CIM) approaches can address the so-called memory-wall (i.e. energy dissipated due to repeated memory read access) they are agnostic to the energy dissipated due to repeated memory writes at the precision required for training (the update-wall), and they don't account for the energy dissipated when transferring information between short-term and long-term memories (the consolidation-wall). The LIM paradigm proposes that these bottlenecks, too, can be overcome if the energy barrier of physical memories is adaptively modulated such that the dynamics of memory updates and consolidation match the Lyapunov dynamics of gradient-descent training of an AI model. In this paper, we derive new theoretical lower bounds on energy dissipation when training AI systems using different LIM approaches. The analysis presented here is model-agnostic and highlights the trade-off between energy efficiency and the speed of training. The resulting non-equilibrium energy-efficiency bounds have a similar flavor as that of Landauer's energy-dissipation bounds. We also extend these limits by taking into account the number of floating-point operations (FLOPs) used for training, the size of the AI model, and the precision of the training parameters. Our projections suggest that the energy-dissipation lower-bound to train a brain scale AI system (comprising of $10^{15}$ parameters) using LIM is $10^8 \sim 10^9$ Joules, which is on the same magnitude the Landauer's adiabatic lower-bound and $6$ to $7$ orders of magnitude lower than the projections obtained using state-of-the-art AI accelerator hardware lower-bounds.
Margin Propagation based XOR-SAT Solvers for Decoding of LDPC Codes
Feb 07, 2024Decoding of Low-Density Parity Check (LDPC) codes can be viewed as a special case of XOR-SAT problems, for which low-computational complexity bit-flipping algorithms have been proposed in the literature. However, a performance gap exists between the bit-flipping LDPC decoding algorithms and the benchmark LDPC decoding algorithms, such as the Sum-Product Algorithm (SPA). In this paper, we propose an XOR-SAT solver using log-sum-exponential functions and demonstrate its advantages for LDPC decoding. This is then approximated using the Margin Propagation formulation to attain a low-complexity LDPC decoder. The proposed algorithm uses soft information to decide the bit-flips that maximize the number of parity check constraints satisfied over an optimization function. The proposed solver can achieve results that are within $0.1$dB of the Sum-Product Algorithm for the same number of code iterations. It is also at least 10x lesser than other Gradient-Descent Bit Flipping decoding algorithms, which are also bit-flipping algorithms based on optimization functions. The approximation using the Margin Propagation formulation does not require any multipliers, resulting in significantly lower computational complexity than other soft-decision Bit-Flipping LDPC decoders.
Neuromorphic Computing with AER using Time-to-Event-Margin Propagation
Apr 27, 2023Address-Event-Representation (AER) is a spike-routing protocol that allows the scaling of neuromorphic and spiking neural network (SNN) architectures to a size that is comparable to that of digital neural network architectures. However, in conventional neuromorphic architectures, the AER protocol and, in general, any virtual interconnect plays only a passive role in computation, i.e., only for routing spikes and events. In this paper, we show how causal temporal primitives like delay, triggering, and sorting inherent in the AER protocol itself can be exploited for scalable neuromorphic computing using our proposed technique called Time-to-Event Margin Propagation (TEMP). The proposed TEMP-based AER architecture is fully asynchronous and relies on interconnect delays for memory and computing as opposed to conventional and local multiply-and-accumulate (MAC) operations. We show that the time-based encoding in the TEMP neural network produces a spatio-temporal representation that can encode a large number of discriminatory patterns. As a proof-of-concept, we show that a trained TEMP-based convolutional neural network (CNN) can demonstrate an accuracy greater than 99% on the MNIST dataset. Overall, our work is a biologically inspired computing paradigm that brings forth a new dimension of research to the field of neuromorphic computing.
Multiplierless In-filter Computing for tinyML Platforms
Apr 24, 2023



Wildlife conservation using continuous monitoring of environmental factors and biomedical classification, which generate a vast amount of sensor data, is a challenge due to limited bandwidth in the case of remote monitoring. It becomes critical to have classification where data is generated, and only classified data is used for monitoring. We present a novel multiplierless framework for in-filter acoustic classification using Margin Propagation (MP) approximation used in low-power edge devices deployable in remote areas with limited connectivity. The entire design of this classification framework is based on template-based kernel machine, which include feature extraction and inference, and uses basic primitives like addition/subtraction, shift, and comparator operations, for hardware implementation. Unlike full precision training methods for traditional classification, we use MP-based approximation for training, including backpropagation mitigating approximation errors. The proposed framework is general enough for acoustic classification. However, we demonstrate the hardware friendliness of this framework by implementing a parallel Finite Impulse Response (FIR) filter bank in a kernel machine classifier optimized for a Field Programmable Gate Array (FPGA). The FIR filter acts as the feature extractor and non-linear kernel for the kernel machine implemented using MP approximation and a downsampling method to reduce the order of the filters. The FPGA implementation on Spartan 7 shows that the MP-approximated in-filter kernel machine is more efficient than traditional classification frameworks with just less than 1K slices.
A Framework for Analyzing Online Cross-correlators using Price's Theorem and Piecewise-Linear Decomposition
Apr 18, 2023Precise estimation of cross-correlation or similarity between two random variables lies at the heart of signal detection, hyperdimensional computing, associative memories, and neural networks. Although a vast literature exists on different methods for estimating cross-correlations, the question what is the best and simplest method to estimate cross-correlations using finite samples ? is still not clear. In this paper, we first argue that the standard empirical approach might not be the optimal method even though the estimator exhibits uniform convergence to the true cross-correlation. Instead, we show that there exists a large class of simple non-linear functions that can be used to construct cross-correlators with a higher signal-to-noise ratio (SNR). To demonstrate this, we first present a general mathematical framework using Price's Theorem that allows us to analyze cross-correlators constructed using a mixture of piece-wise linear functions. Using this framework and high-dimensional embedding, we show that some of the most promising cross-correlators are based on Huber's loss functions, margin-propagation (MP) functions, and the log-sum-exp functions.
On-device Synaptic Memory Consolidation using Fowler-Nordheim Quantum-tunneling
Jun 27, 2022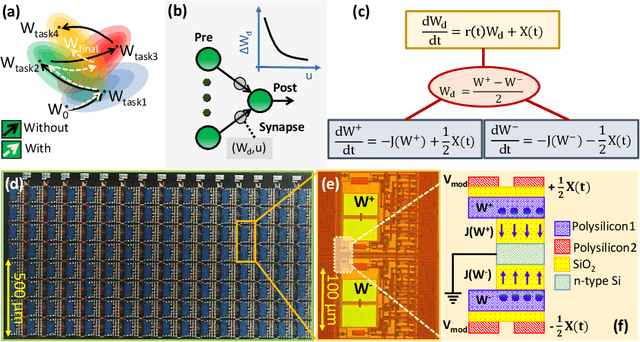
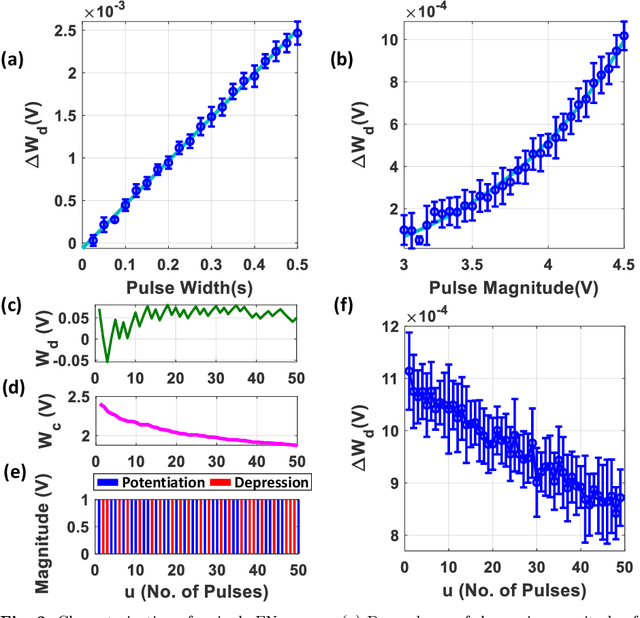
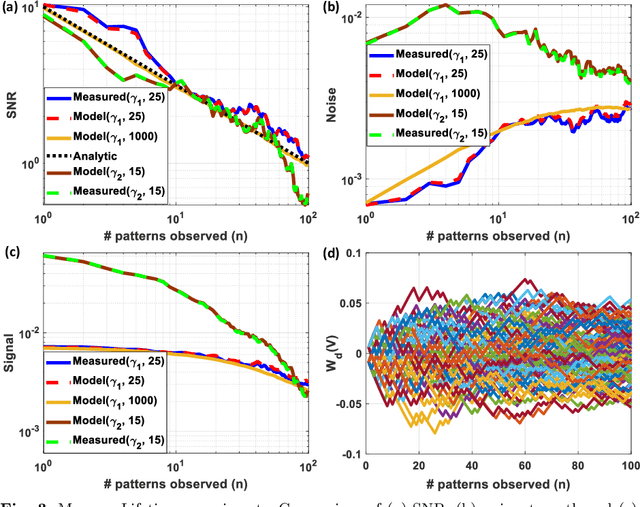
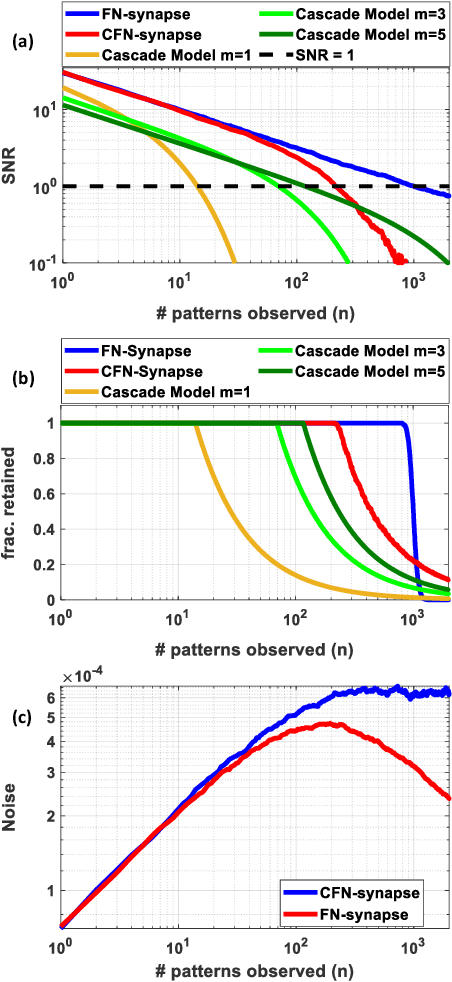
Synaptic memory consolidation has been heralded as one of the key mechanisms for supporting continual learning in neuromorphic Artificial Intelligence (AI) systems. Here we report that a Fowler-Nordheim (FN) quantum-tunneling device can implement synaptic memory consolidation similar to what can be achieved by algorithmic consolidation models like the cascade and the elastic weight consolidation (EWC) models. The proposed FN-synapse not only stores the synaptic weight but also stores the synapse's historical usage statistic on the device itself. We also show that the operation of the FN-synapse is near-optimal in terms of the synaptic lifetime and we demonstrate that a network comprising FN-synapses outperforms a comparable EWC network for a small benchmark continual learning task. With an energy footprint of femtojoules per synaptic update, we believe that the proposed FN-synapse provides an ultra-energy-efficient approach for implementing both synaptic memory consolidation and persistent learning.
Theory and Implementation of Process and Temperature Scalable Shape-based CMOS Analog Circuits
May 11, 2022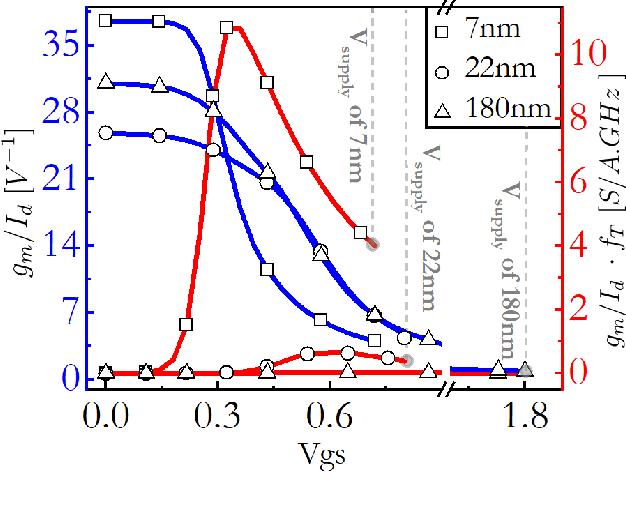
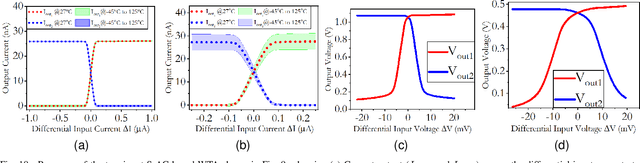
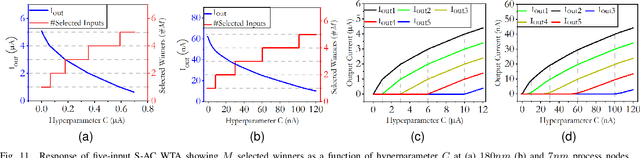
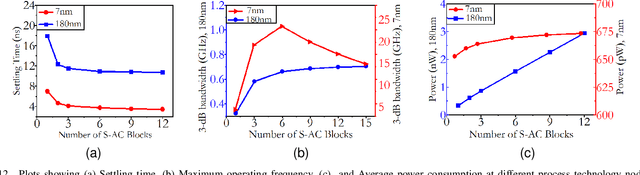
Analog computing is attractive to its digital counterparts due to its potential for achieving high compute density and energy efficiency. However, the device-to-device variability and challenges in porting existing designs to advance process nodes have posed a major hindrance in harnessing the full potential of analog computations for Machine Learning (ML) applications. This work proposes a novel analog computing framework for designing an analog ML processor similar to that of a digital design - where the designs can be scaled and ported to advanced process nodes without architectural changes. At the core of our work lies shape-based analog computing (S-AC). It utilizes device primitives to yield a robust proto-function through which other non-linear shapes can be derived. S-AC paradigm also allows the user to trade off computational precision with silicon circuit area and power. Thus allowing users to build a truly power-efficient and scalable analog architecture where the same synthesized analog circuit can operate across different biasing regimes of transistors and simultaneously scale across process nodes. As a proof of concept, we show the implementation of commonly used mathematical functions for carrying standard ML tasks in both planar CMOS 180nm and FinFET 7nm process nodes. The synthesized Shape-based ML architecture has been demonstrated for its classification accuracy on standard data sets at different process nodes.