 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarable Platform with Integrated Simultaneous EEG Sensing and Auditory Stimulation
Apr 24, 2026Conventional scalp-based EEG systems are cumbersome to use, requiring extensive setup, restrictive wiring, and conductive gels that can dry out and limit long-term monitoring, while also carrying social stigma. As a result, there is increasing interest in in-ear EEG technology to improve comfort, convenience, and discretion for users. This work presents a personalized in-ear EEG monitor (IEEM) that simultaneously captures EEG signals from the outer ear while delivering audio playback through the same device. The earpiece is custom-molded to precisely match the user's ear anatomy, providing effective sound isolation from the environment and enabling direct audio transmission into the ear canal. Testing of the assembled earpiece shows successful detection of electrooculography (EOG), eye blinks, jaw clenches, auditory steady-state responses (ASSR), and alpha modulation. Electrochemical impedance spectroscopy (EIS) measurements confirm stable electrode-skin contact, with impedance values similar to those of traditional dry electrodes. The integrated approach enables potential closed-loop neuromodulation applications all in the ear where brain activity can be monitored in real-time and corresponding acoustic stimulation delivered adaptively.
AI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
NeuroAI and Beyond
Jan 27, 2026Neuroscience and Artificial Intelligence (AI) have made significant progress in the past few years but have only been loosely inter-connected. Based on a workshop held in August 2025, we identify current and future areas of synergism between these two fields. We focus on the subareas of embodiment, language and communication, robotics, learning in humans and machines and Neuromorphic engineering to take stock of the progress made so far, and possible promising new future avenues. Overall, we advocate for the development of NeuroAI, a type of Neuroscience-informed Artificial Intelligence that, we argue, has the potential for significantly improving the scope and efficiency of AI algorithms while simultaneously changing the way we understand biological neural computations. We include personal statements from several leading researchers on their diverse views of NeuroAI. Two Strength-Weakness-Opportunities-Threat (SWOT) analyses by researchers and trainees are appended that describe the benefits and risks offered by NeuroAI.
Clo-HDnn: A 4.66 TFLOPS/W and 3.78 TOPS/W Continual On-Device Learning Accelerator with Energy-efficient Hyperdimensional Computing via Progressive Search
Jul 23, 2025Clo-HDnn is an on-device learning (ODL) accelerator designed for emerging continual learning (CL) tasks. Clo-HDnn integrates hyperdimensional computing (HDC) along with low-cost Kronecker HD Encoder and weight clustering feature extraction (WCFE) to optimize accuracy and efficiency. Clo-HDnn adopts gradient-free CL to efficiently update and store the learned knowledge in the form of class hypervectors. Its dual-mode operation enables bypassing costly feature extraction for simpler datasets, while progressive search reduces complexity by up to 61% by encoding and comparing only partial query hypervectors. Achieving 4.66 TFLOPS/W (FE) and 3.78 TOPS/W (classifier), Clo-HDnn delivers 7.77x and 4.85x higher energy efficiency compared to SOTA ODL accelerators.
Graph Representations for Reading Comprehension Analysis using Large Language Model and Eye-Tracking Biomarker
Jul 16, 2025Reading comprehension is a fundamental skill in human cognitive development. With the advancement of Large Language Models (LLMs), there is a growing need to compare how humans and LLMs understand language across different contexts and apply this understanding to functional tasks such as inference, emotion interpretation, and information retrieval. Our previous work used LLMs and human biomarkers to study the reading comprehension process. The results showed that the biomarkers corresponding to words with high and low relevance to the inference target, as labeled by the LLMs, exhibited distinct patterns, particularly when validated using eye-tracking data. However, focusing solely on individual words limited the depth of understanding, which made the conclusions somewhat simplistic despite their potential significance. This study used an LLM-based AI agent to group words from a reading passage into nodes and edges, forming a graph-based text representation based on semantic meaning and question-oriented prompts. We then compare the distribution of eye fixations on important nodes and edges. Our findings indicate that LLMs exhibit high consistency in language understanding at the level of graph topological structure. These results build on our previous findings and offer insights into effective human-AI co-learning strategies.
Quantifying Data Requirements for EEG Independent Component Analysis Using AMICA
Jun 11, 2025
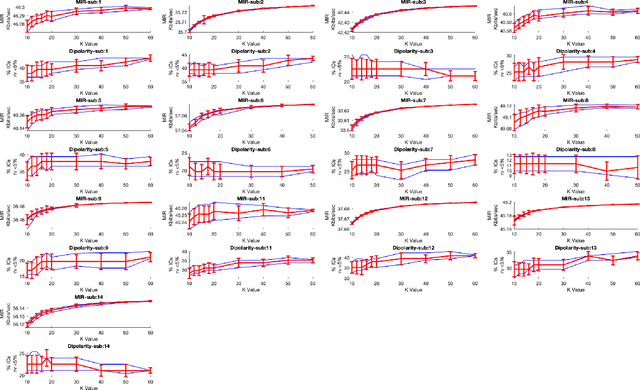


Independent Component Analysis (ICA) is an important step in EEG processing for a wide-ranging set of applications. However, ICA requires well-designed studies and data collection practices to yield optimal results. Past studies have focused on quantitative evaluation of the differences in quality produced by different ICA algorithms as well as different configurations of parameters for AMICA, a multimodal ICA algorithm that is considered the benchmark against which other algorithms are measured. Here, the effect of the data quantity versus the number of channels on decomposition quality is explored. AMICA decompositions were run on a 71 channel dataset with 13 subjects while randomly subsampling data to correspond to specific ratios of the number of frames in a dataset to the channel count. Decomposition quality was evaluated for the varying quantities of data using measures of mutual information reduction (MIR) and the near dipolarity of components. We also note that an asymptotic trend can be seen in the increase of MIR and a general increasing trend in near dipolarity with increasing data, but no definitive plateau in these metrics was observed, suggesting that the benefits of collecting additional EEG data may extend beyond common heuristic thresholds and continue to enhance decomposition quality.
ON-OFF Neuromorphic ISING Machines using Fowler-Nordheim Annealers
Jun 07, 2024We introduce NeuroSA, a neuromorphic architecture specifically designed to ensure asymptotic convergence to the ground state of an Ising problem using an annealing process that is governed by the physics of quantum mechanical tunneling using Fowler-Nordheim (FN). The core component of NeuroSA consists of a pair of asynchronous ON-OFF neurons, which effectively map classical simulated annealing (SA) dynamics onto a network of integrate-and-fire (IF) neurons. The threshold of each ON-OFF neuron pair is adaptively adjusted by an FN annealer which replicates the optimal escape mechanism and convergence of SA, particularly at low temperatures. To validate the effectiveness of our neuromorphic Ising machine, we systematically solved various benchmark MAX-CUT combinatorial optimization problems. Across multiple runs, NeuroSA consistently generates solutions that approach the state-of-the-art level with high accuracy (greater than 99%), and without any graph-specific hyperparameter tuning. For practical illustration, we present results from an implementation of NeuroSA on the SpiNNaker2 platform, highlighting the feasibility of mapping our proposed architecture onto a standard neuromorphic accelerator platform.
Energy-efficiency Limits on Training AI Systems using Learning-in-Memory
Feb 21, 2024Learning-in-memory (LIM) is a recently proposed paradigm to overcome fundamental memory bottlenecks in training machine learning systems. While compute-in-memory (CIM) approaches can address the so-called memory-wall (i.e. energy dissipated due to repeated memory read access) they are agnostic to the energy dissipated due to repeated memory writes at the precision required for training (the update-wall), and they don't account for the energy dissipated when transferring information between short-term and long-term memories (the consolidation-wall). The LIM paradigm proposes that these bottlenecks, too, can be overcome if the energy barrier of physical memories is adaptively modulated such that the dynamics of memory updates and consolidation match the Lyapunov dynamics of gradient-descent training of an AI model. In this paper, we derive new theoretical lower bounds on energy dissipation when training AI systems using different LIM approaches. The analysis presented here is model-agnostic and highlights the trade-off between energy efficiency and the speed of training. The resulting non-equilibrium energy-efficiency bounds have a similar flavor as that of Landauer's energy-dissipation bounds. We also extend these limits by taking into account the number of floating-point operations (FLOPs) used for training, the size of the AI model, and the precision of the training parameters. Our projections suggest that the energy-dissipation lower-bound to train a brain scale AI system (comprising of $10^{15}$ parameters) using LIM is $10^8 \sim 10^9$ Joules, which is on the same magnitude the Landauer's adiabatic lower-bound and $6$ to $7$ orders of magnitude lower than the projections obtained using state-of-the-art AI accelerator hardware lower-bounds.
Towards Chip-in-the-loop Spiking Neural Network Training via Metropolis-Hastings Sampling
Feb 09, 2024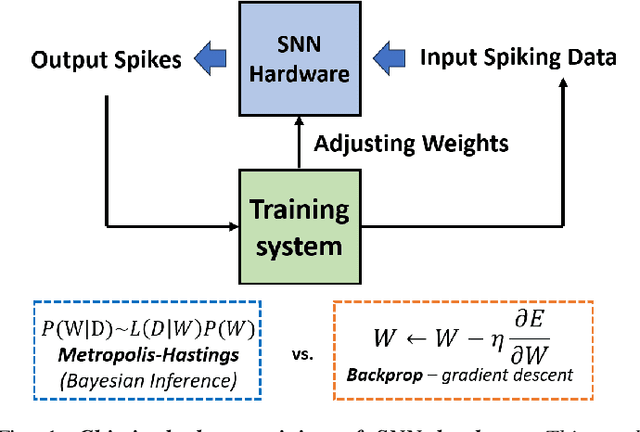
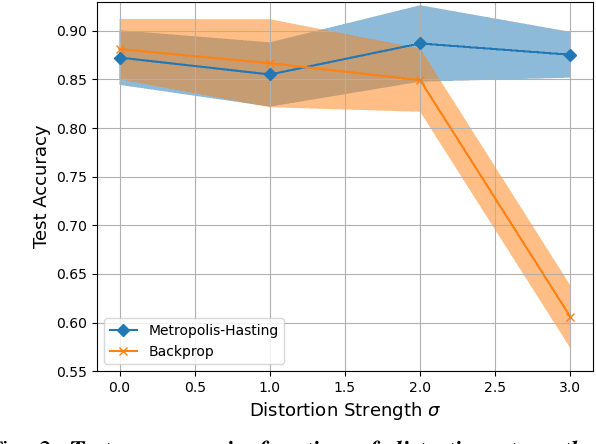
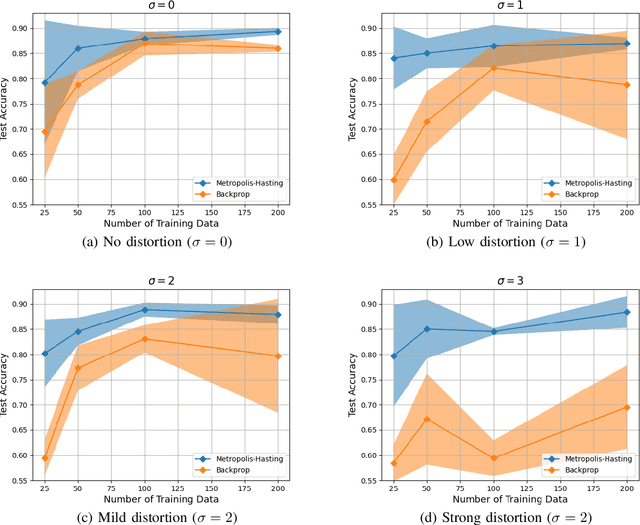
This paper studies the use of Metropolis-Hastings sampling for training Spiking Neural Network (SNN) hardware subject to strong unknown non-idealities, and compares the proposed approach to the common use of the backpropagation of error (backprop) algorithm and surrogate gradients, widely used to train SNNs in literature. Simulations are conducted within a chip-in-the-loop training context, where an SNN subject to unknown distortion must be trained to detect cancer from measurements, within a biomedical application context. Our results show that the proposed approach strongly outperforms the use of backprop by up to $27\%$ higher accuracy when subject to strong hardware non-idealities. Furthermore, our results also show that the proposed approach outperforms backprop in terms of SNN generalization, needing $>10 \times$ less training data for achieving effective accuracy. These findings make the proposed training approach well-suited for SNN implementations in analog subthreshold circuits and other emerging technologies where unknown hardware non-idealities can jeopardize backprop.
Multi-level, Forming Free, Bulk Switching Trilayer RRAM for Neuromorphic Computing at the Edge
Oct 20, 2023Resistive memory-based reconfigurable systems constructed by CMOS-RRAM integration hold great promise for low energy and high throughput neuromorphic computing. However, most RRAM technologies relying on filamentary switching suffer from variations and noise leading to computational accuracy loss, increased energy consumption, and overhead by expensive program and verify schemes. Low ON-state resistance of filamentary RRAM devices further increases the energy consumption due to high-current read and write operations, and limits the array size and parallel multiply & accumulate operations. High-forming voltages needed for filamentary RRAM are not compatible with advanced CMOS technology nodes. To address all these challenges, we developed a forming-free and bulk switching RRAM technology based on a trilayer metal-oxide stack. We systematically engineered a trilayer metal-oxide RRAM stack and investigated the switching characteristics of RRAM devices with varying thicknesses and oxygen vacancy distributions across the trilayer to achieve reliable bulk switching without any filament formation. We demonstrated bulk switching operation at megaohm regime with high current nonlinearity and programmed up to 100 levels without compliance current. We developed a neuromorphic compute-in-memory platform based on trilayer bulk RRAM crossbars by combining energy-efficient switched-capacitor voltage sensing circuits with differential encoding of weights to experimentally demonstrate high-accuracy matrix-vector multiplication. We showcased the computational capability of bulk RRAM crossbars by implementing a spiking neural network model for an autonomous navigation/racing task. Our work addresses challenges posed by existing RRAM technologies and paves the way for neuromorphic computing at the edge under strict size, weight, and power constraints.