 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-FSM: Scaling Large Language Models for Finite-State Reasoning in RTL Code Generation
Feb 03, 2026Finite-state reasoning, the ability to understand and implement state-dependent behavior, is central to hardware design. In this paper, we present LLM-FSM, a benchmark that evaluates how well large language models (LLMs) can recover finite-state machine (FSM) behavior from natural-language specifications and translate it into correct register transfer-level (RTL) implementations. Unlike prior specification-to-RTL benchmarks that rely on manually constructed examples, LLM-FSM is built through a fully automated pipeline. LLM-FSM first constructs FSM with configurable state counts and constrained transition structures. It then prompts LLMs to express each FSM in a structured YAML format with an application context, and to further convert that YAML into a natural-language (NL) specification. From the same YAML, our pipeline synthesizes the reference RTL and testbench in a correct-by-construction manner. All 1,000 problems are verified using LLM-based and SAT-solver-based checks, with human review on a subset. Our experiments show that even the strongest LLMs exhibit sharply declining accuracy as FSM complexity increases. We further demonstrate that training-time scaling via supervised fine-tuning (SFT) generalizes effectively to out-of-distribution (OOD) tasks, while increasing test-time compute improves reasoning reliability. Finally, LLM-FSM remains extensible by allowing its FSM complexity to scale with future model capabilities.
Edge AI without Compromise: Efficient, Versatile and Accurate Neurocomputing in Resistive Random-Access Memory
Aug 17, 2021
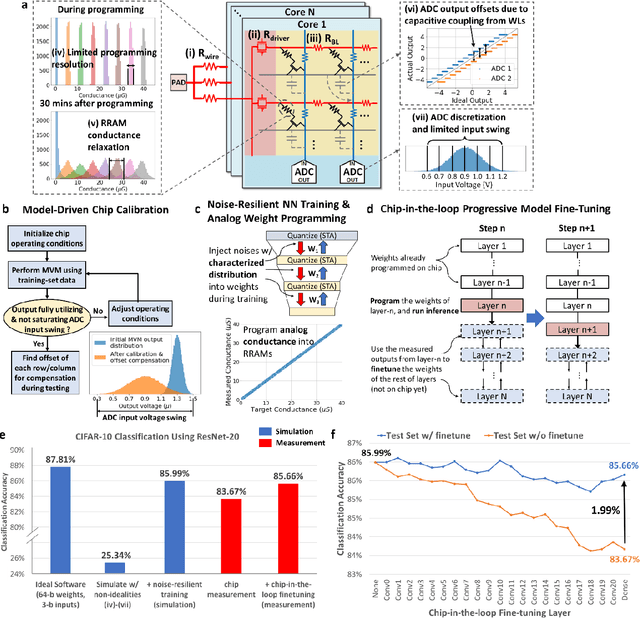
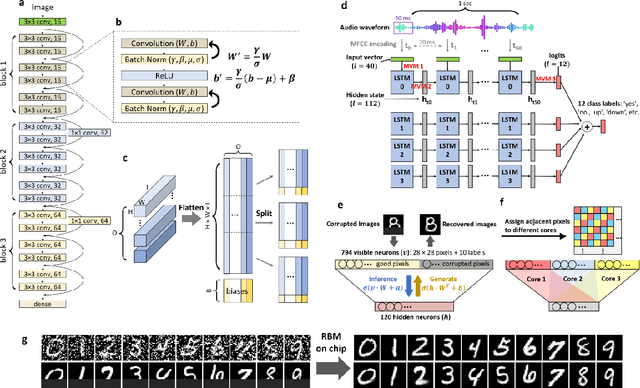
Realizing today's cloud-level artificial intelligence functionalities directly on devices distributed at the edge of the internet calls for edge hardware capable of processing multiple modalities of sensory data (e.g. video, audio) at unprecedented energy-efficiency. AI hardware architectures today cannot meet the demand due to a fundamental "memory wall": data movement between separate compute and memory units consumes large energy and incurs long latency. Resistive random-access memory (RRAM) based compute-in-memory (CIM) architectures promise to bring orders of magnitude energy-efficiency improvement by performing computation directly within memory. However, conventional approaches to CIM hardware design limit its functional flexibility necessary for processing diverse AI workloads, and must overcome hardware imperfections that degrade inference accuracy. Such trade-offs between efficiency, versatility and accuracy cannot be addressed by isolated improvements on any single level of the design. By co-optimizing across all hierarchies of the design from algorithms and architecture to circuits and devices, we present NeuRRAM - the first multimodal edge AI chip using RRAM CIM to simultaneously deliver a high degree of versatility for diverse model architectures, record energy-efficiency $5\times$ - $8\times$ better than prior art across various computational bit-precisions, and inference accuracy comparable to software models with 4-bit weights on all measured standard AI benchmarks including accuracy of 99.0% on MNIST and 85.7% on CIFAR-10 image classification, 84.7% accuracy on Google speech command recognition, and a 70% reduction in image reconstruction error on a Bayesian image recovery task. This work paves a way towards building highly efficient and reconfigurable edge AI hardware platforms for the more demanding and heterogeneous AI applications of the future.
Automating Vitiligo Skin Lesion Segmentation Using Convolutional Neural Networks
Dec 16, 2019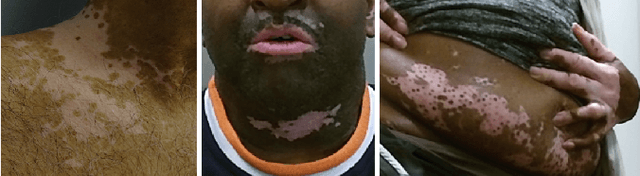
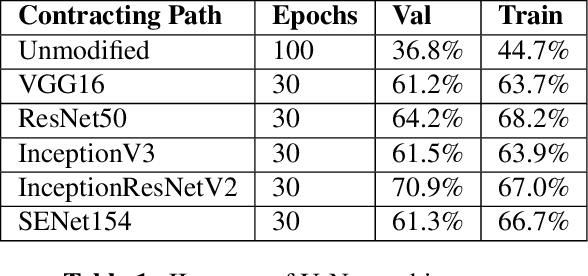
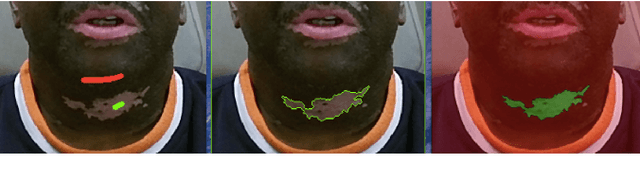
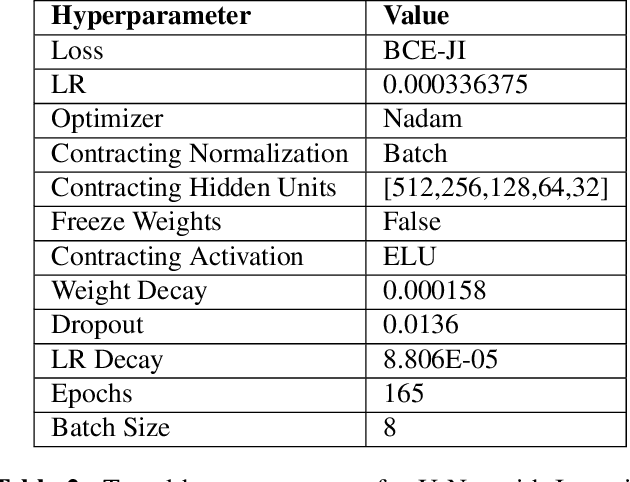
For several skin conditions such as vitiligo, accurate segmentation of lesions from skin images is the primary measure of disease progression and severity. Existing methods for vitiligo lesion segmentation require manual intervention. Unfortunately, manual segmentation is time and labor-intensive, as well as irreproducible between physicians. We introduce a convolutional neural network (CNN) that quickly and robustly performs vitiligo skin lesion segmentation. Our CNN has a U-Net architecture with a modified contracting path. We use the CNN to generate an initial segmentation of the lesion, then refine it by running the watershed algorithm on high-confidence pixels. We train the network on 247 images with a variety of lesion sizes, complexity, and anatomical sites. The network with our modifications noticeably outperforms the state-of-the-art U-Net, with a Jaccard Index (JI) score of 73.6% (compared to 36.7%). Moreover, our method requires only a few seconds for segmentation, in contrast with the previously proposed semi-autonomous watershed approach, which requires 2-29 minutes per image.