 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Know When They Do Not Know: Calibration, Cascading, and Cleaning
Jan 12, 2026When a model knows when it does not know, many possibilities emerge. The first question is how to enable a model to recognize that it does not know. A promising approach is to use confidence, computed from the model's internal signals, to reflect its ignorance. Prior work in specific domains has shown that calibration can provide reliable confidence estimates. In this work, we propose a simple, effective, and universal training-free method that applies to both vision and language models, performing model calibration, cascading, and data cleaning to better exploit a model's ability to recognize when it does not know. We first highlight two key empirical observations: higher confidence corresponds to higher accuracy within a single model, and models calibrated on the validation set remain calibrated on a held-out test set. These findings empirically establish the reliability and comparability of calibrated confidence. Building on this, we introduce two applications: (1) model cascading with calibrated advantage routing and (2) data cleaning based on model ensemble. Using the routing signal derived from the comparability of calibrated confidences, we cascade large and small models to improve efficiency with almost no compromise in accuracy, and we further cascade two models of comparable scale to achieve performance beyond either model alone. Leveraging multiple experts and their calibrated confidences, we design a simple yet effective data-cleaning method that balances precision and detection rate to identify mislabeled samples in ImageNet and Massive Multitask Language Understanding (MMLU) datasets. Our results demonstrate that enabling models to recognize when they do not know is a practical step toward more efficient, reliable, and trustworthy AI.
Edge AI without Compromise: Efficient, Versatile and Accurate Neurocomputing in Resistive Random-Access Memory
Aug 17, 2021
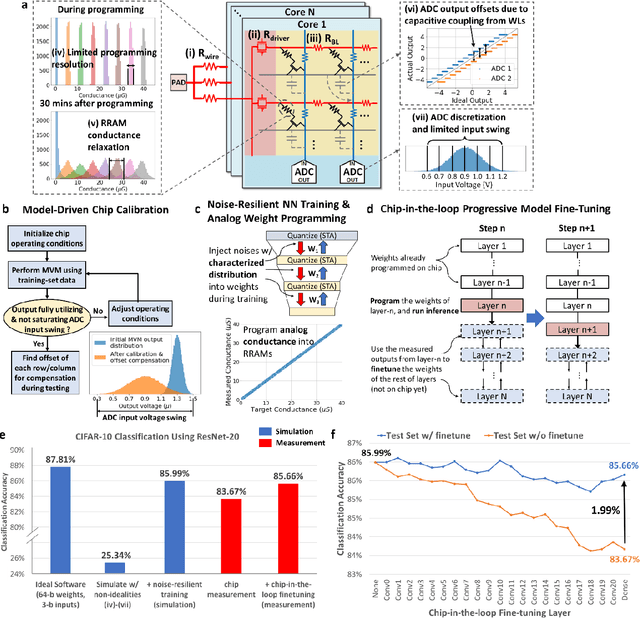
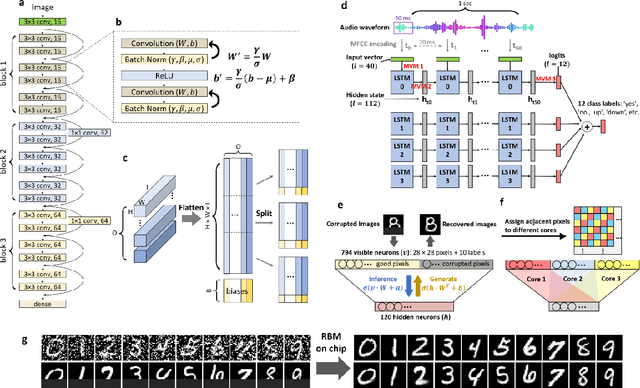
Realizing today's cloud-level artificial intelligence functionalities directly on devices distributed at the edge of the internet calls for edge hardware capable of processing multiple modalities of sensory data (e.g. video, audio) at unprecedented energy-efficiency. AI hardware architectures today cannot meet the demand due to a fundamental "memory wall": data movement between separate compute and memory units consumes large energy and incurs long latency. Resistive random-access memory (RRAM) based compute-in-memory (CIM) architectures promise to bring orders of magnitude energy-efficiency improvement by performing computation directly within memory. However, conventional approaches to CIM hardware design limit its functional flexibility necessary for processing diverse AI workloads, and must overcome hardware imperfections that degrade inference accuracy. Such trade-offs between efficiency, versatility and accuracy cannot be addressed by isolated improvements on any single level of the design. By co-optimizing across all hierarchies of the design from algorithms and architecture to circuits and devices, we present NeuRRAM - the first multimodal edge AI chip using RRAM CIM to simultaneously deliver a high degree of versatility for diverse model architectures, record energy-efficiency $5\times$ - $8\times$ better than prior art across various computational bit-precisions, and inference accuracy comparable to software models with 4-bit weights on all measured standard AI benchmarks including accuracy of 99.0% on MNIST and 85.7% on CIFAR-10 image classification, 84.7% accuracy on Google speech command recognition, and a 70% reduction in image reconstruction error on a Bayesian image recovery task. This work paves a way towards building highly efficient and reconfigurable edge AI hardware platforms for the more demanding and heterogeneous AI applications of the future.