 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventSSEG: Event-driven Self-Supervised Segmentation with Probabilistic Attention
Aug 20, 2025Road segmentation is pivotal for autonomous vehicles, yet achieving low latency and low compute solutions using frame based cameras remains a challenge. Event cameras offer a promising alternative. To leverage their low power sensing, we introduce EventSSEG, a method for road segmentation that uses event only computing and a probabilistic attention mechanism. Event only computing poses a challenge in transferring pretrained weights from the conventional camera domain, requiring abundant labeled data, which is scarce. To overcome this, EventSSEG employs event-based self supervised learning, eliminating the need for extensive labeled data. Experiments on DSEC-Semantic and DDD17 show that EventSSEG achieves state of the art performance with minimal labeled events. This approach maximizes event cameras capabilities and addresses the lack of labeled events.
Theroretical Insight into Batch Normalization: Data Dependant Auto-Tuning of Regularization Rate
Sep 15, 2022


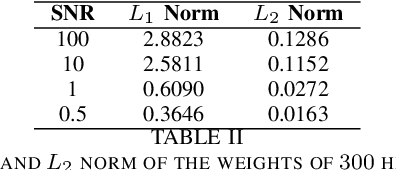
Batch normalization is widely used in deep learning to normalize intermediate activations. Deep networks suffer from notoriously increased training complexity, mandating careful initialization of weights, requiring lower learning rates, etc. These issues have been addressed by Batch Normalization (\textbf{BN}), by normalizing the inputs of activations to zero mean and unit standard deviation. Making this batch normalization part of the training process dramatically accelerates the training process of very deep networks. A new field of research has been going on to examine the exact theoretical explanation behind the success of \textbf{BN}. Most of these theoretical insights attempt to explain the benefits of \textbf{BN} by placing them on its influence on optimization, weight scale invariance, and regularization. Despite \textbf{BN} undeniable success in accelerating generalization, the gap of analytically relating the effect of \textbf{BN} to the regularization parameter is still missing. This paper aims to bring out the data-dependent auto-tuning of the regularization parameter by \textbf{BN} with analytical proofs. We have posed \textbf{BN} as a constrained optimization imposed on non-\textbf{BN} weights through which we demonstrate its data statistics dependant auto-tuning of regularization parameter. We have also given analytical proof for its behavior under a noisy input scenario, which reveals the signal vs. noise tuning of the regularization parameter. We have also substantiated our claim with empirical results from the MNIST dataset experiments.
Event-LSTM: An Unsupervised and Asynchronous Learning-based Representation for Event-based Data
May 10, 2021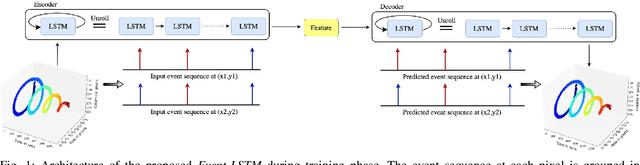
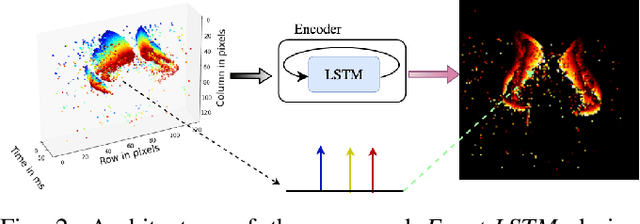
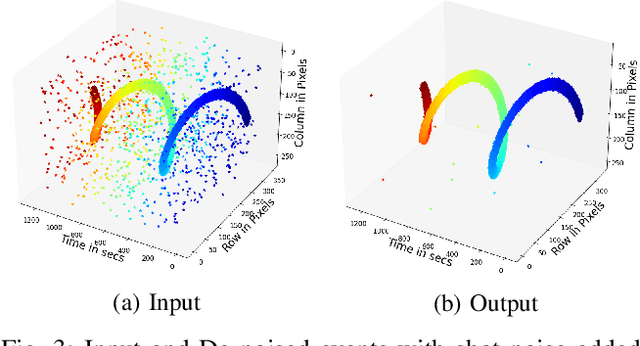
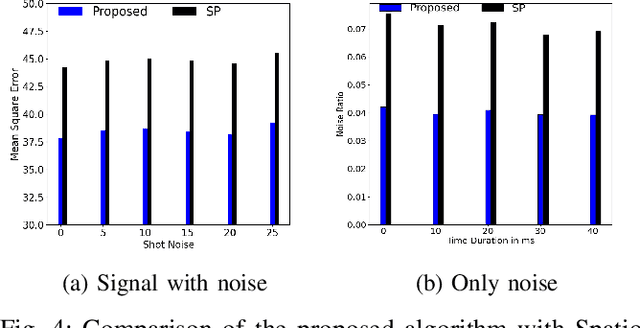
Event cameras are activity-driven bio-inspired vision sensors, thereby resulting in advantages such as sparsity,high temporal resolution, low latency, and power consumption. Given the different sensing modality of event camera and high quality of conventional vision paradigm, event processing is predominantly solved by transforming the sparse and asynchronous events into 2D grid and subsequently applying standard vision pipelines. Despite the promising results displayed by supervised learning approaches in 2D grid generation, these approaches treat the task in supervised manner. Labeled task specific ground truth event data is challenging to acquire. To overcome this limitation, we propose Event-LSTM, an unsupervised Auto-Encoder architecture made up of LSTM layers as a promising alternative to learn 2D grid representation from event sequence. Compared to competing supervised approaches, ours is a task-agnostic approach ideally suited for the event domain, where task specific labeled data is scarce. We also tailor the proposed solution to exploit asynchronous nature of event stream, which gives it desirable charateristics such as speed invariant and energy-efficient 2D grid generation. Besides, we also push state-of-the-art event de-noising forward by introducing memory into the de-noising process. Evaluations on activity recognition and gesture recognition demonstrate that our approach yields improvement over state-of-the-art approaches, while providing the flexibilty to learn from unlabelled data.
EvAn: Neuromorphic Event-based Anomaly Detection
Nov 21, 2019
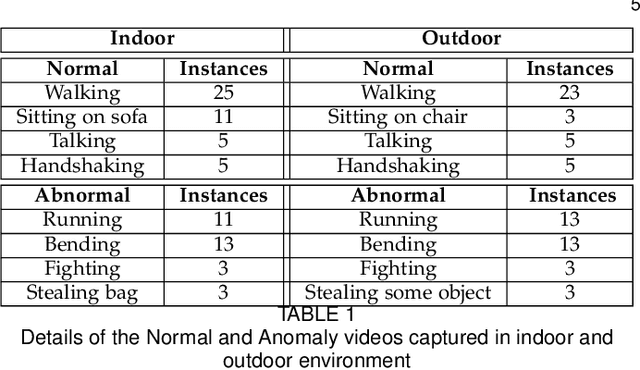


Event-based cameras are bio-inspired novel sensors that asynchronously record changes in illumination in the form of events, thus resulting in significant advantages over conventional cameras in terms of low power utilization, high dynamic range, and no motion blur. Moreover, such cameras, by design, encode only the relative motion between the scene and the sensor (and not the static background) to yield a very sparse data structure, which can be utilized for various motion analytics tasks. In this paper, for the first time in event data analytics community, we leverage these advantages of an event camera towards a critical vision application - video anomaly detection. We propose to model the motion dynamics in the event domain with dual discriminator conditional Generative adversarial Network (cGAN) built on state-of-the-art architectures. To adapt event data for using as input to cGAN, we also put forward a deep learning solution to learn a novel representation of event data, which retains the sparsity of the data as well as encode the temporal information readily available from these sensors. Since there is no existing dataset for anomaly detection in event domain, we also provide an anomaly detection event dataset with an exhaustive set of anomalies. We empirically validate different components of our architecture on this proposed dataset as well as validate the benefits of our event data representation over state-of-the-art event data representations on video anomaly detection application.