 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-LSTM: An Unsupervised and Asynchronous Learning-based Representation for Event-based Data
Paper and Code
May 10, 2021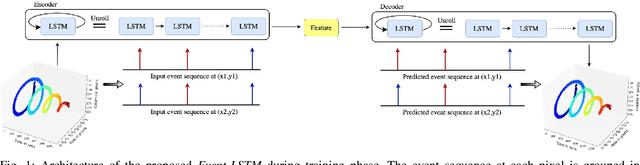
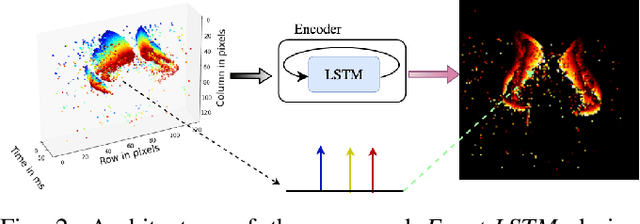
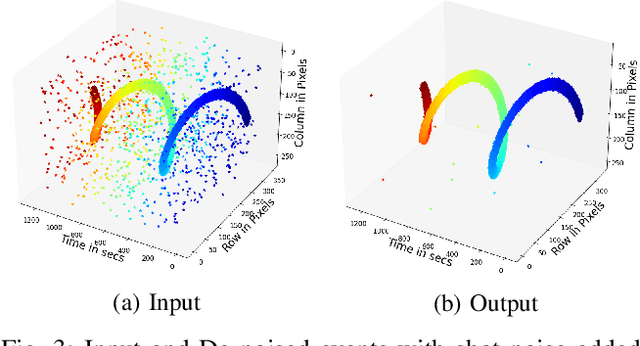
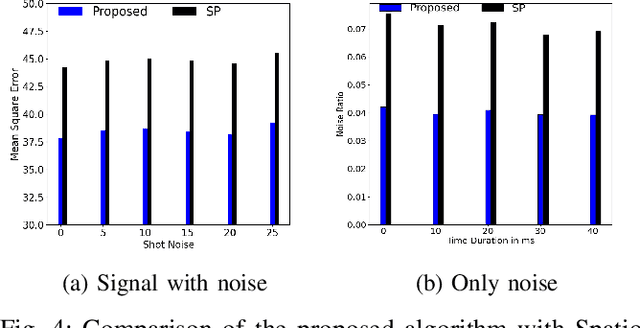
Event cameras are activity-driven bio-inspired vision sensors, thereby resulting in advantages such as sparsity,high temporal resolution, low latency, and power consumption. Given the different sensing modality of event camera and high quality of conventional vision paradigm, event processing is predominantly solved by transforming the sparse and asynchronous events into 2D grid and subsequently applying standard vision pipelines. Despite the promising results displayed by supervised learning approaches in 2D grid generation, these approaches treat the task in supervised manner. Labeled task specific ground truth event data is challenging to acquire. To overcome this limitation, we propose Event-LSTM, an unsupervised Auto-Encoder architecture made up of LSTM layers as a promising alternative to learn 2D grid representation from event sequence. Compared to competing supervised approaches, ours is a task-agnostic approach ideally suited for the event domain, where task specific labeled data is scarce. We also tailor the proposed solution to exploit asynchronous nature of event stream, which gives it desirable charateristics such as speed invariant and energy-efficient 2D grid generation. Besides, we also push state-of-the-art event de-noising forward by introducing memory into the de-noising process. Evaluations on activity recognition and gesture recognition demonstrate that our approach yields improvement over state-of-the-art approaches, while providing the flexibilty to learn from unlabelled data.