 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOMI: Ultra-Fast EdgeAI platform for Event Cameras
Aug 18, 2025Event cameras offer significant advantages for edge robotics applications due to their asynchronous operation and sparse, event-driven output, making them well-suited for tasks requiring fast and efficient closed-loop control, such as gesture-based human-robot interaction. Despite this potential, existing event processing solutions remain limited, often lacking complete end-to-end implementations, exhibiting high latency, and insufficiently exploiting event data sparsity. In this paper, we present HOMI, an ultra-low latency, end-to-end edge AI platform comprising a Prophesee IMX636 event sensor chip with an Xilinx Zynq UltraScale+MPSoC FPGA chip, deploying an in-house developed AI accelerator. We have developed hardware-optimized pre-processing pipelines supporting both constant-time and constant-event modes for histogram accumulation, linear and exponential time surfaces. Our general-purpose implementation caters to both accuracy-driven and low-latency applications. HOMI achieves 94% accuracy on the DVS Gesture dataset as a use case when configured for high accuracy operation and provides a throughput of 1000 fps for low-latency configuration. The hardware-optimised pipeline maintains a compact memory footprint and utilises only 33% of the available LUT resources on the FPGA, leaving ample headroom for further latency reduction, model parallelisation, multi-task deployments, or integration of more complex architectures.
Neural Signal Compression using RAMAN tinyML Accelerator for BCI Applications
Apr 09, 2025High-quality, multi-channel neural recording is indispensable for neuroscience research and clinical applications. Large-scale brain recordings often produce vast amounts of data that must be wirelessly transmitted for subsequent offline analysis and decoding, especially in brain-computer interfaces (BCIs) utilizing high-density intracortical recordings with hundreds or thousands of electrodes. However, transmitting raw neural data presents significant challenges due to limited communication bandwidth and resultant excessive heating. To address this challenge, we propose a neural signal compression scheme utilizing Convolutional Autoencoders (CAEs), which achieves a compression ratio of up to 150 for compressing local field potentials (LFPs). The CAE encoder section is implemented on RAMAN, an energy-efficient tinyML accelerator designed for edge computing, and subsequently deployed on an Efinix Ti60 FPGA with 37.3k LUTs and 8.6k register utilization. RAMAN leverages sparsity in activation and weights through zero skipping, gating, and weight compression techniques. Additionally, we employ hardware-software co-optimization by pruning CAE encoder model parameters using a hardware-aware balanced stochastic pruning strategy, resolving workload imbalance issues and eliminating indexing overhead to reduce parameter storage requirements by up to 32.4%. Using the proposed compact depthwise separable convolutional autoencoder (DS-CAE) model, the compressed neural data from RAMAN is reconstructed offline with superior signal-to-noise and distortion ratios (SNDR) of 22.6 dB and 27.4 dB, along with R2 scores of 0.81 and 0.94, respectively, evaluated on two monkey neural recordings.
RAMAN: A Re-configurable and Sparse tinyML Accelerator for Inference on Edge
Jun 10, 2023


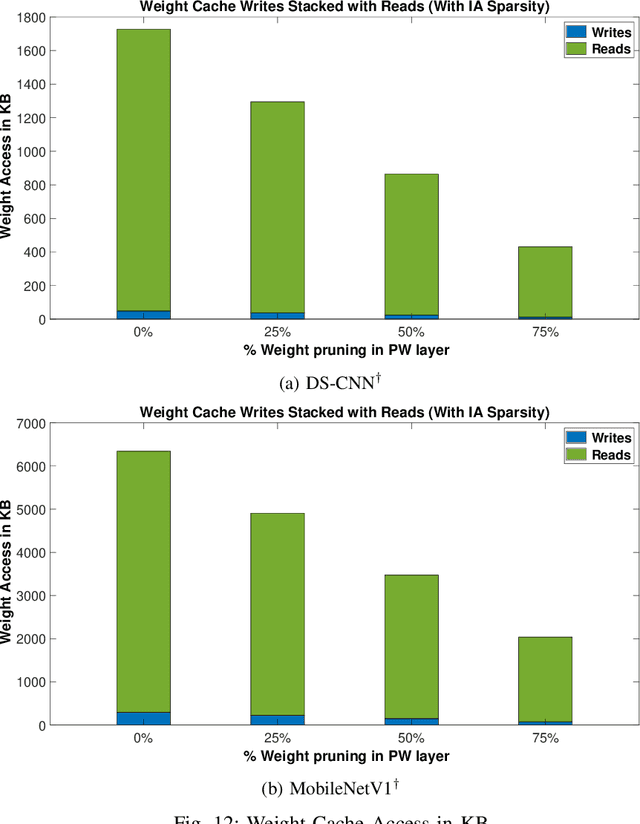
Deep Neural Network (DNN) based inference at the edge is challenging as these compute and data-intensive algorithms need to be implemented at low cost and low power while meeting the latency constraints of the target applications. Sparsity, in both activations and weights inherent to DNNs, is a key knob to leverage. In this paper, we present RAMAN, a Re-configurable and spArse tinyML Accelerator for infereNce on edge, architected to exploit the sparsity to reduce area (storage), power as well as latency. RAMAN can be configured to support a wide range of DNN topologies - consisting of different convolution layer types and a range of layer parameters (feature-map size and the number of channels). RAMAN can also be configured to support accuracy vs power/latency tradeoffs using techniques deployed at compile-time and run-time. We present the salient features of the architecture, provide implementation results and compare the same with the state-of-the-art. RAMAN employs novel dataflow inspired by Gustavson's algorithm that has optimal input activation (IA) and output activation (OA) reuse to minimize memory access and the overall data movement cost. The dataflow allows RAMAN to locally reduce the partial sum (Psum) within a processing element array to eliminate the Psum writeback traffic. Additionally, we suggest a method to reduce peak activation memory by overlapping IA and OA on the same memory space, which can reduce storage requirements by up to 50%. RAMAN was implemented on a low-power and resource-constrained Efinix Ti60 FPGA with 37.2K LUTs and 8.6K register utilization. RAMAN processes all layers of the MobileNetV1 model at 98.47 GOp/s/W and the DS-CNN model at 79.68 GOp/s/W by leveraging both weight and activation sparsity.
Source localization using particle filtering on FPGA for robotic navigation with imprecise binary measurement
Oct 22, 2020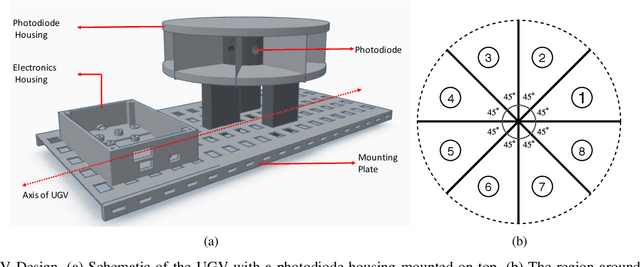
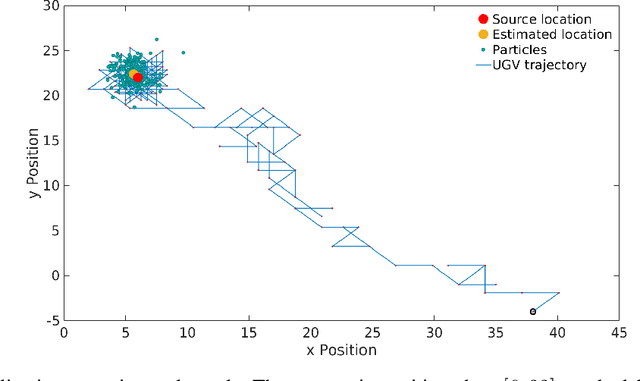
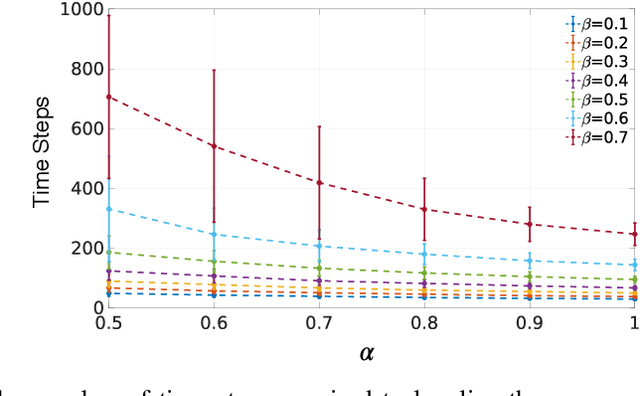
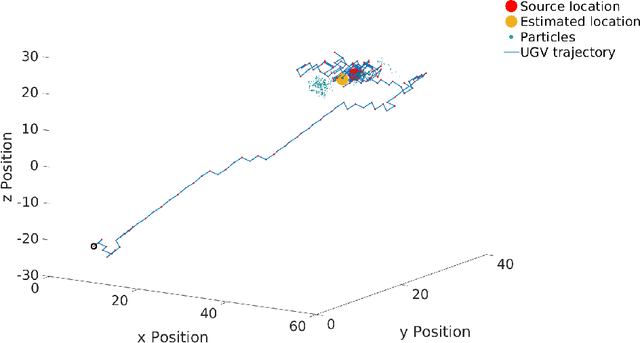
Particle filtering is a recursive Bayesian estimation technique that has gained popularity recently for tracking and localization applications. It uses Monte Carlo simulation and has proven to be a very reliable technique to model non-Gaussian and non-linear elements of physical systems. Particle filters outperform various other traditional filters like Kalman filters in non-Gaussian and non-linear settings due to their non-analytical and non-parametric nature. However, a significant drawback of particle filters is their computational complexity, which inhibits their use in real-time applications with conventional CPU or DSP based implementation schemes. This paper proposes a modification to the existing particle filter algorithm and presents a highspeed and dedicated hardware architecture. The architecture incorporates pipelining and parallelization in the design to reduce execution time considerably. The design is validated for a source localization problem wherein we estimate the position of a source in real-time using the particle filter algorithm implemented on hardware. The validation setup relies on an Unmanned Ground Vehicle (UGV) with a photodiode housing on top to sense and localize a light source. We have prototyped the design using Artix-7 field-programmable gate array (FPGA), and resource utilization for the proposed system is presented. Further, we show the execution time and estimation accuracy of the high-speed architecture and observe a significant reduction in computational time. Our implementation of particle filters on FPGA is scalable and modular, with a low execution time of about 5.62 us for processing 1024 particles and can be deployed for real-time applications.