 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePremonition: Using Generative Models to Preempt Future Data Changes in Continual Learning
Mar 12, 2024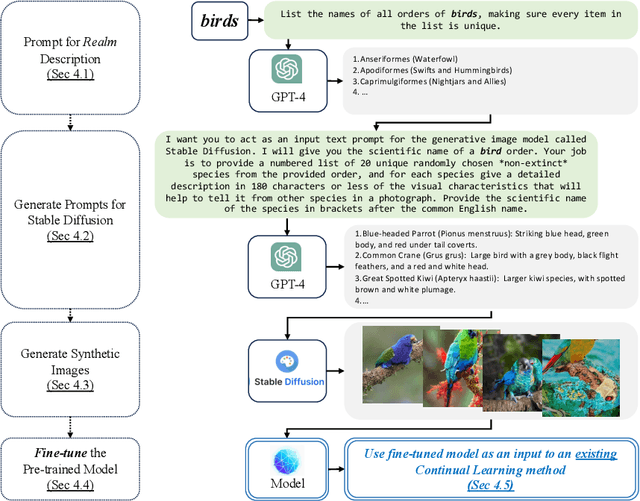


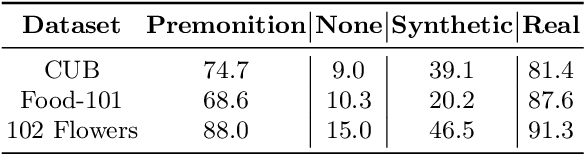
Continual learning requires a model to adapt to ongoing changes in the data distribution, and often to the set of tasks to be performed. It is rare, however, that the data and task changes are completely unpredictable. Given a description of an overarching goal or data theme, which we call a realm, humans can often guess what concepts are associated with it. We show here that the combination of a large language model and an image generation model can similarly provide useful premonitions as to how a continual learning challenge might develop over time. We use the large language model to generate text descriptions of semantically related classes that might potentially appear in the data stream in future. These descriptions are then rendered using Stable Diffusion to generate new labelled image samples. The resulting synthetic dataset is employed for supervised pre-training, but is discarded prior to commencing continual learning, along with the pre-training classification head. We find that the backbone of our pre-trained networks can learn representations useful for the downstream continual learning problem, thus becoming a valuable input to any existing continual learning method. Although there are complexities arising from the domain gap between real and synthetic images, we show that pre-training models in this manner improves multiple Class Incremenal Learning (CIL) methods on fine-grained image classification benchmarks. Supporting code can be found at https://github.com/cl-premonition/premonition.
RanPAC: Random Projections and Pre-trained Models for Continual Learning
Jul 05, 2023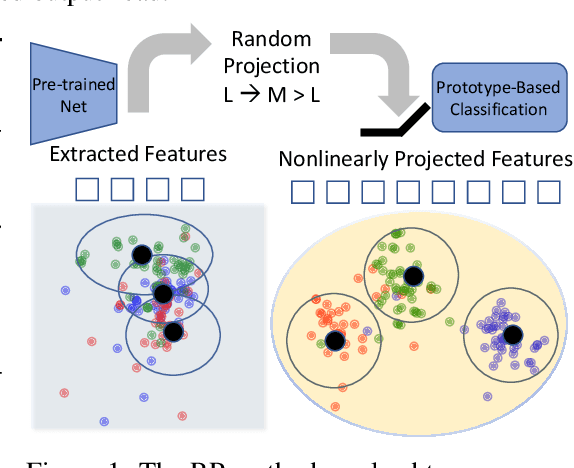
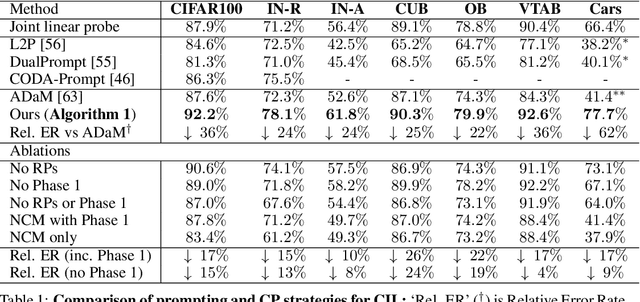
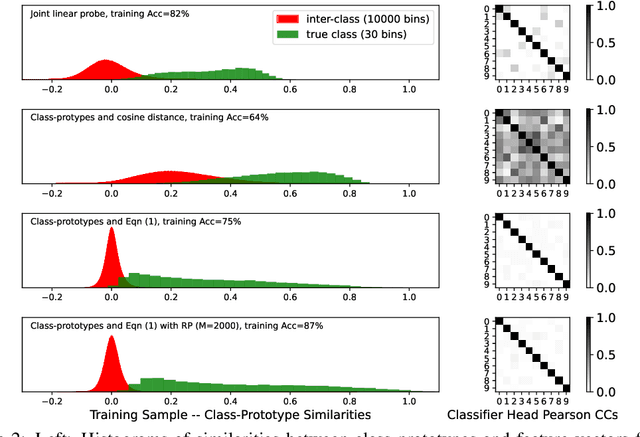

Continual learning (CL) aims to incrementally learn different tasks (such as classification) in a non-stationary data stream without forgetting old ones. Most CL works focus on tackling catastrophic forgetting under a learning-from-scratch paradigm. However, with the increasing prominence of foundation models, pre-trained models equipped with informative representations have become available for various downstream requirements. Several CL methods based on pre-trained models have been explored, either utilizing pre-extracted features directly (which makes bridging distribution gaps challenging) or incorporating adaptors (which may be subject to forgetting). In this paper, we propose a concise and effective approach for CL with pre-trained models. Given that forgetting occurs during parameter updating, we contemplate an alternative approach that exploits training-free random projectors and class-prototype accumulation, which thus bypasses the issue. Specifically, we inject a frozen Random Projection layer with nonlinear activation between the pre-trained model's feature representations and output head, which captures interactions between features with expanded dimensionality, providing enhanced linear separability for class-prototype-based CL. We also demonstrate the importance of decorrelating the class-prototypes to reduce the distribution disparity when using pre-trained representations. These techniques prove to be effective and circumvent the problem of forgetting for both class- and domain-incremental continual learning. Compared to previous methods applied to pre-trained ViT-B/16 models, we reduce final error rates by between 10\% and 62\% on seven class-incremental benchmark datasets, despite not using any rehearsal memory. We conclude that the full potential of pre-trained models for simple, effective, and fast continual learning has not hitherto been fully tapped.
Single-bit-per-weight deep convolutional neural networks without batch-normalization layers for embedded systems
Jul 22, 2019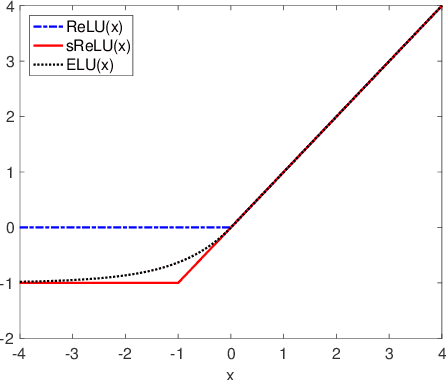
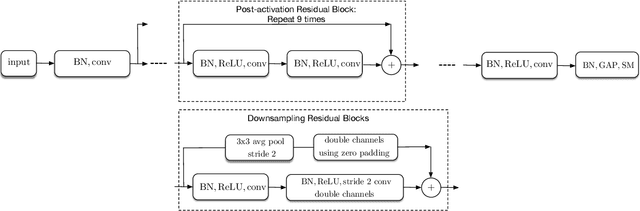
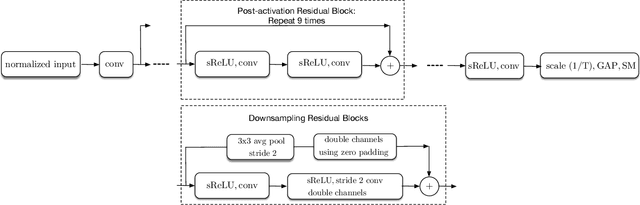
Batch-normalization (BN) layers are thought to be an integrally important layer type in today's state-of-the-art deep convolutional neural networks for computer vision tasks such as classification and detection. However, BN layers introduce complexity and computational overheads that are highly undesirable for training and/or inference on low-power custom hardware implementations of real-time embedded vision systems such as UAVs, robots and Internet of Things (IoT) devices. They are also problematic when batch sizes need to be very small during training, and innovations such as residual connections introduced more recently than BN layers could potentially have lessened their impact. In this paper we aim to quantify the benefits BN layers offer in image classification networks, in comparison with alternative choices. In particular, we study networks that use shifted-ReLU layers instead of BN layers. We found, following experiments with wide residual networks applied to the ImageNet, CIFAR 10 and CIFAR 100 image classification datasets, that BN layers do not consistently offer a significant advantage. We found that the accuracy margin offered by BN layers depends on the data set, the network size, and the bit-depth of weights. We conclude that in situations where BN layers are undesirable due to speed, memory or complexity costs, that using shifted-ReLU layers instead should be considered; we found they can offer advantages in all these areas, and often do not impose a significant accuracy cost.
Diagnosing Convolutional Neural Networks using their Spectral Response
Oct 08, 2018


Convolutional Neural Networks (CNNs) are a class of artificial neural networks whose computational blocks use convolution, together with other linear and non-linear operations, to perform classification or regression. This paper explores the spectral response of CNNs and its potential use in diagnosing problems with their training. We measure the gain of CNNs trained for image classification on ImageNet and observe that the best models are also the most sensitive to perturbations of their input. Further, we perform experiments on MNIST and CIFAR-10 to find that the gain rises as the network learns and then saturates as the network converges. Moreover, we find that strong gain fluctuations can point to overfitting and learning problems caused by a poor choice of learning rate. We argue that the gain of CNNs can act as a diagnostic tool and potential replacement for the validation loss when hold-out validation data are not available.
Training wide residual networks for deployment using a single bit for each weight
Feb 23, 2018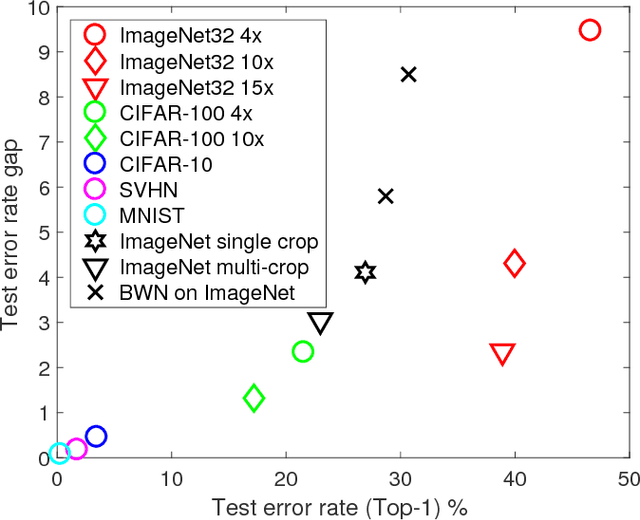
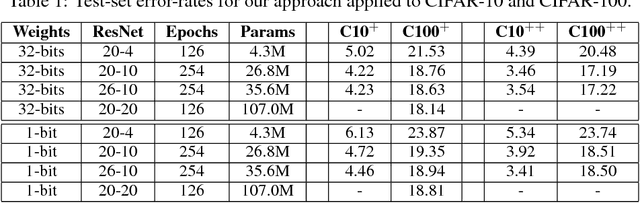

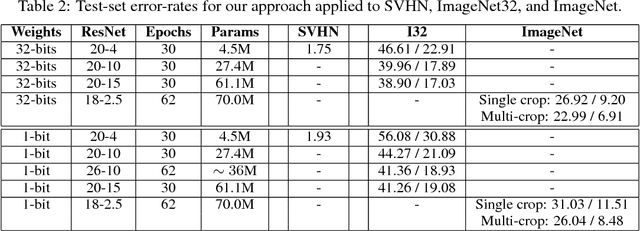
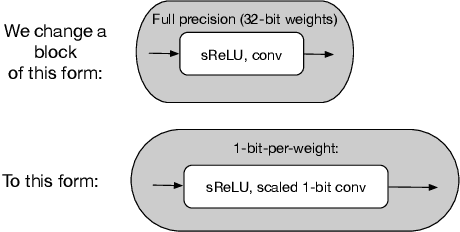
For fast and energy-efficient deployment of trained deep neural networks on resource-constrained embedded hardware, each learned weight parameter should ideally be represented and stored using a single bit. Error-rates usually increase when this requirement is imposed. Here, we report large improvements in error rates on multiple datasets, for deep convolutional neural networks deployed with 1-bit-per-weight. Using wide residual networks as our main baseline, our approach simplifies existing methods that binarize weights by applying the sign function in training; we apply scaling factors for each layer with constant unlearned values equal to the layer-specific standard deviations used for initialization. For CIFAR-10, CIFAR-100 and ImageNet, and models with 1-bit-per-weight requiring less than 10 MB of parameter memory, we achieve error rates of 3.9%, 18.5% and 26.0% / 8.5% (Top-1 / Top-5) respectively. We also considered MNIST, SVHN and ImageNet32, achieving 1-bit-per-weight test results of 0.27%, 1.9%, and 41.3% / 19.1% respectively. For CIFAR, our error rates halve previously reported values, and are within about 1% of our error-rates for the same network with full-precision weights. For networks that overfit, we also show significant improvements in error rate by not learning batch normalization scale and offset parameters. This applies to both full precision and 1-bit-per-weight networks. Using a warm-restart learning-rate schedule, we found that training for 1-bit-per-weight is just as fast as full-precision networks, with better accuracy than standard schedules, and achieved about 98%-99% of peak performance in just 62 training epochs for CIFAR-10/100. For full training code and trained models in MATLAB, Keras and PyTorch see https://github.com/McDonnell-Lab/1-bit-per-weight/ .
* Published as a conference paper at ICLR 2018
Track Everything: Limiting Prior Knowledge in Online Multi-Object Recognition
Apr 21, 2017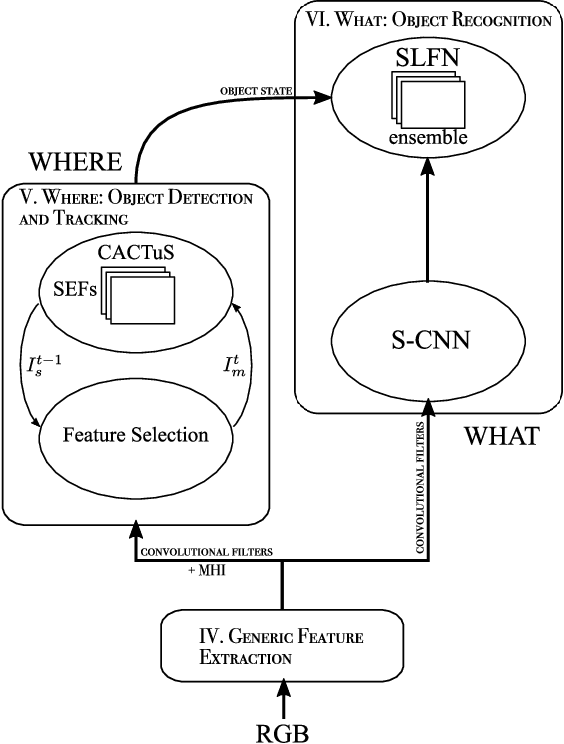
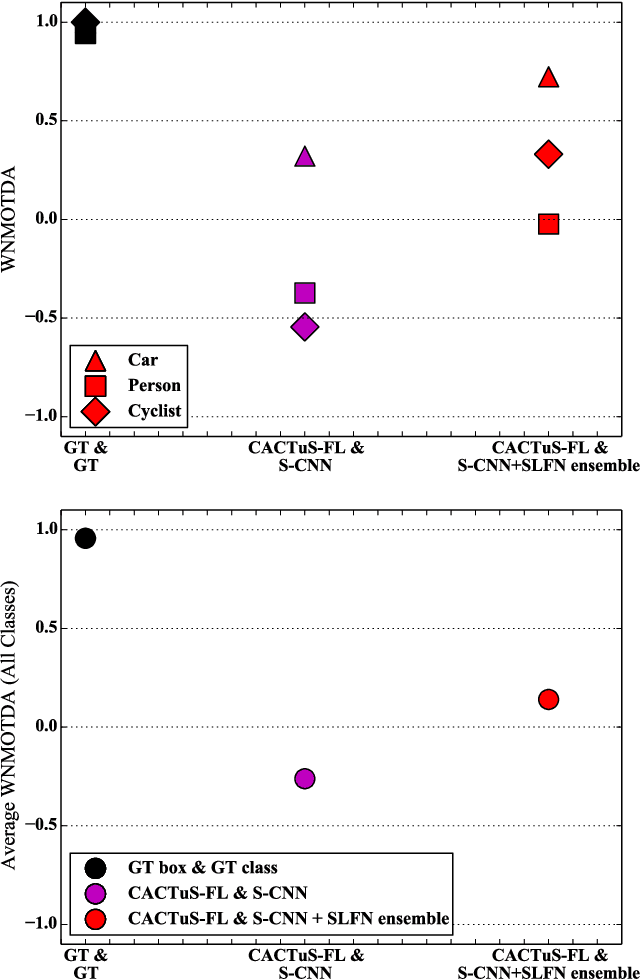


This paper addresses the problem of online tracking and classification of multiple objects in an image sequence. Our proposed solution is to first track all objects in the scene without relying on object-specific prior knowledge, which in other systems can take the form of hand-crafted features or user-based track initialization. We then classify the tracked objects with a fast-learning image classifier that is based on a shallow convolutional neural network architecture and demonstrate that object recognition improves when this is combined with object state information from the tracking algorithm. We argue that by transferring the use of prior knowledge from the detection and tracking stages to the classification stage we can design a robust, general purpose object recognition system with the ability to detect and track a variety of object types. We describe our biologically inspired implementation, which adaptively learns the shape and motion of tracked objects, and apply it to the Neovision2 Tower benchmark data set, which contains multiple object types. An experimental evaluation demonstrates that our approach is competitive with state-of-the-art video object recognition systems that do make use of object-specific prior knowledge in detection and tracking, while providing additional practical advantages by virtue of its generality.
Understanding data augmentation for classification: when to warp?
Nov 26, 2016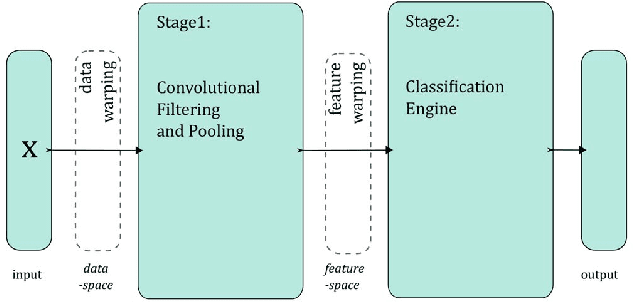

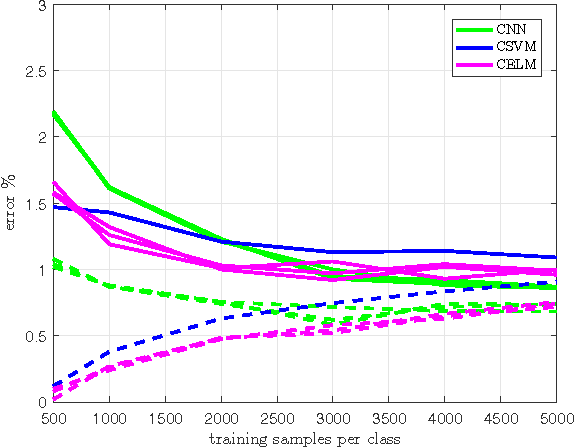
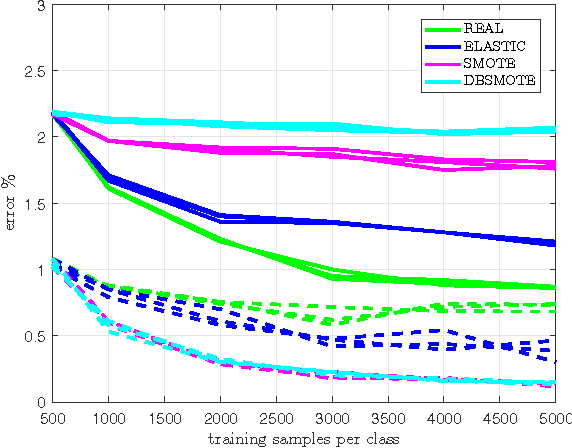
In this paper we investigate the benefit of augmenting data with synthetically created samples when training a machine learning classifier. Two approaches for creating additional training samples are data warping, which generates additional samples through transformations applied in the data-space, and synthetic over-sampling, which creates additional samples in feature-space. We experimentally evaluate the benefits of data augmentation for a convolutional backpropagation-trained neural network, a convolutional support vector machine and a convolutional extreme learning machine classifier, using the standard MNIST handwritten digit dataset. We found that while it is possible to perform generic augmentation in feature-space, if plausible transforms for the data are known then augmentation in data-space provides a greater benefit for improving performance and reducing overfitting.
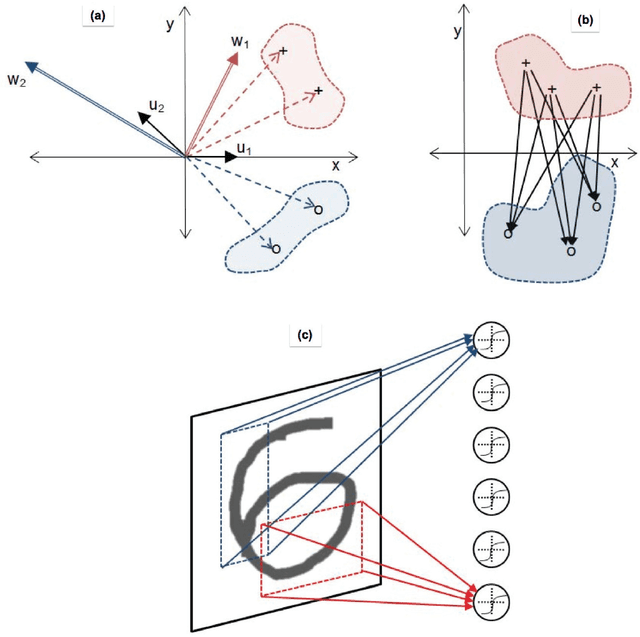
Enhanced Image Classification With a Fast-Learning Shallow Convolutional Neural Network
Aug 15, 2015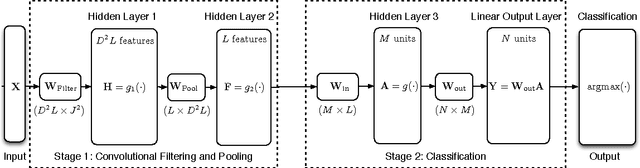

We present a neural network architecture and training method designed to enable very rapid training and low implementation complexity. Due to its training speed and very few tunable parameters, the method has strong potential for applications requiring frequent retraining or online training. The approach is characterized by (a) convolutional filters based on biologically inspired visual processing filters, (b) randomly-valued classifier-stage input weights, (c) use of least squares regression to train the classifier output weights in a single batch, and (d) linear classifier-stage output units. We demonstrate the efficacy of the method by applying it to image classification. Our results match existing state-of-the-art results on the MNIST (0.37% error) and NORB-small (2.2% error) image classification databases, but with very fast training times compared to standard deep network approaches. The network's performance on the Google Street View House Number (SVHN) (4% error) database is also competitive with state-of-the art methods.
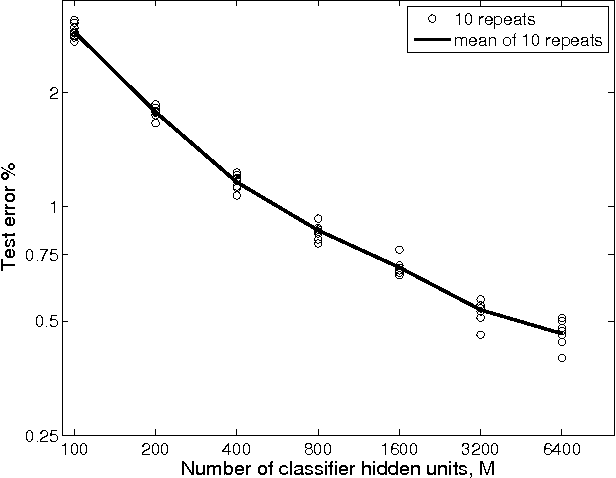
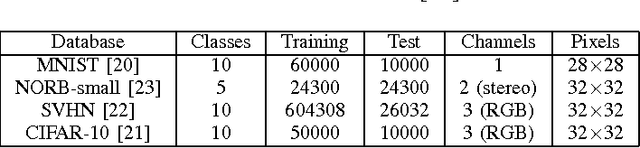
Fast, simple and accurate handwritten digit classification by training shallow neural network classifiers with the 'extreme learning machine' algorithm
Jul 22, 2015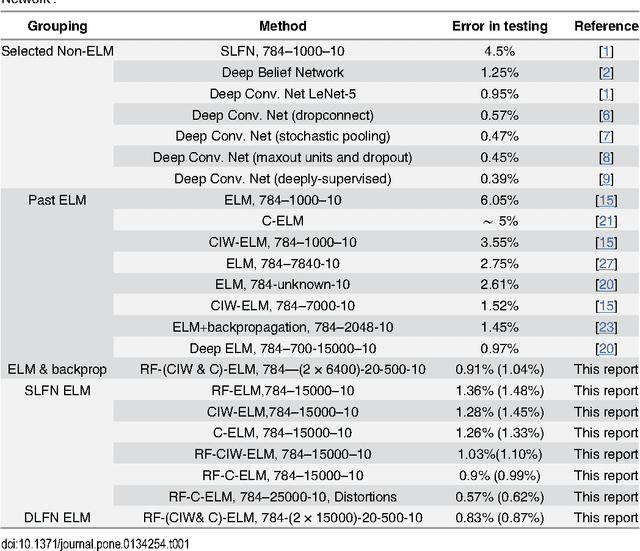
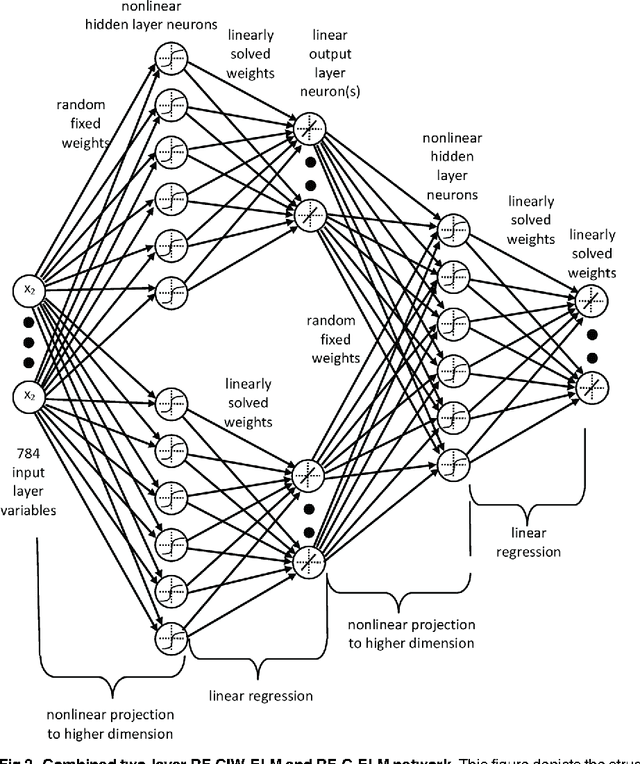
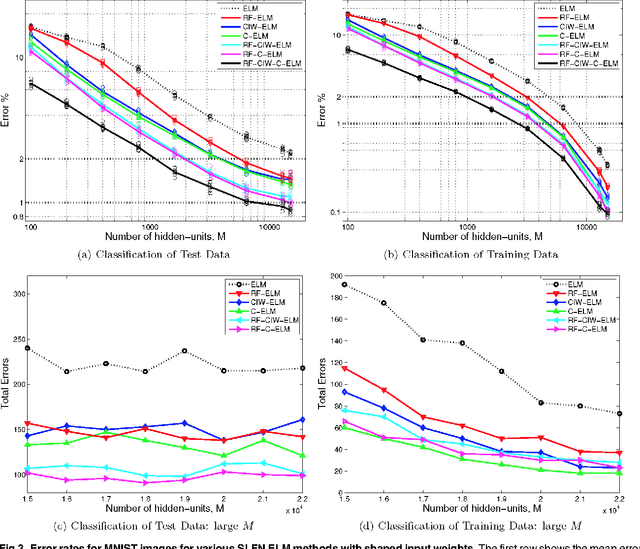
Recent advances in training deep (multi-layer) architectures have inspired a renaissance in neural network use. For example, deep convolutional networks are becoming the default option for difficult tasks on large datasets, such as image and speech recognition. However, here we show that error rates below 1% on the MNIST handwritten digit benchmark can be replicated with shallow non-convolutional neural networks. This is achieved by training such networks using the 'Extreme Learning Machine' (ELM) approach, which also enables a very rapid training time (~10 minutes). Adding distortions, as is common practise for MNIST, reduces error rates even further. Our methods are also shown to be capable of achieving less than 5.5% error rates on the NORB image database. To achieve these results, we introduce several enhancements to the standard ELM algorithm, which individually and in combination can significantly improve performance. The main innovation is to ensure each hidden-unit operates only on a randomly sized and positioned patch of each image. This form of random `receptive field' sampling of the input ensures the input weight matrix is sparse, with about 90% of weights equal to zero. Furthermore, combining our methods with a small number of iterations of a single-batch backpropagation method can significantly reduce the number of hidden-units required to achieve a particular performance. Our close to state-of-the-art results for MNIST and NORB suggest that the ease of use and accuracy of the ELM algorithm for designing a single-hidden-layer neural network classifier should cause it to be given greater consideration either as a standalone method for simpler problems, or as the final classification stage in deep neural networks applied to more difficult problems.