 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding data augmentation for classification: when to warp?
Paper and Code
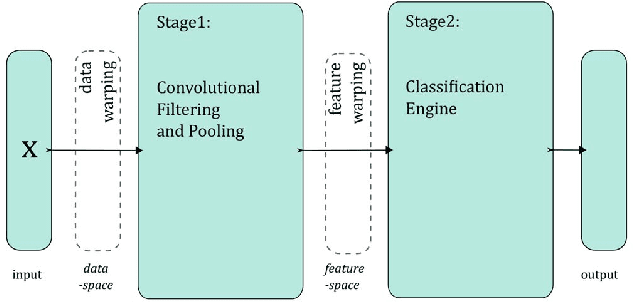

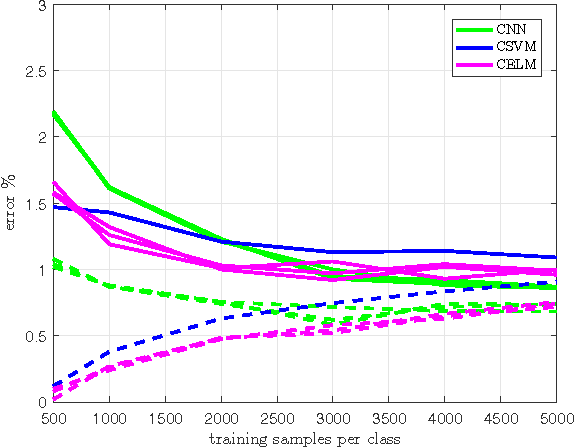
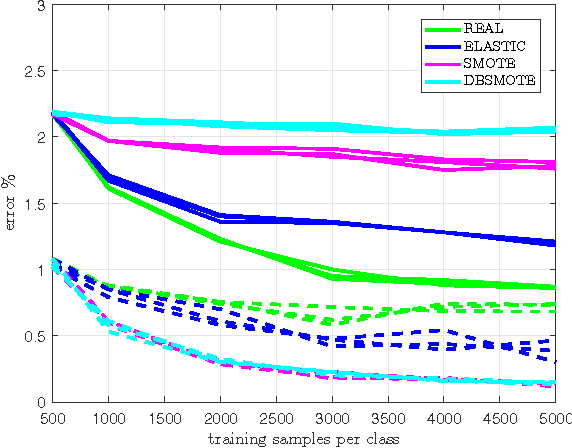
In this paper we investigate the benefit of augmenting data with synthetically created samples when training a machine learning classifier. Two approaches for creating additional training samples are data warping, which generates additional samples through transformations applied in the data-space, and synthetic over-sampling, which creates additional samples in feature-space. We experimentally evaluate the benefits of data augmentation for a convolutional backpropagation-trained neural network, a convolutional support vector machine and a convolutional extreme learning machine classifier, using the standard MNIST handwritten digit dataset. We found that while it is possible to perform generic augmentation in feature-space, if plausible transforms for the data are known then augmentation in data-space provides a greater benefit for improving performance and reducing overfitting.