 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrack Everything: Limiting Prior Knowledge in Online Multi-Object Recognition
Apr 21, 2017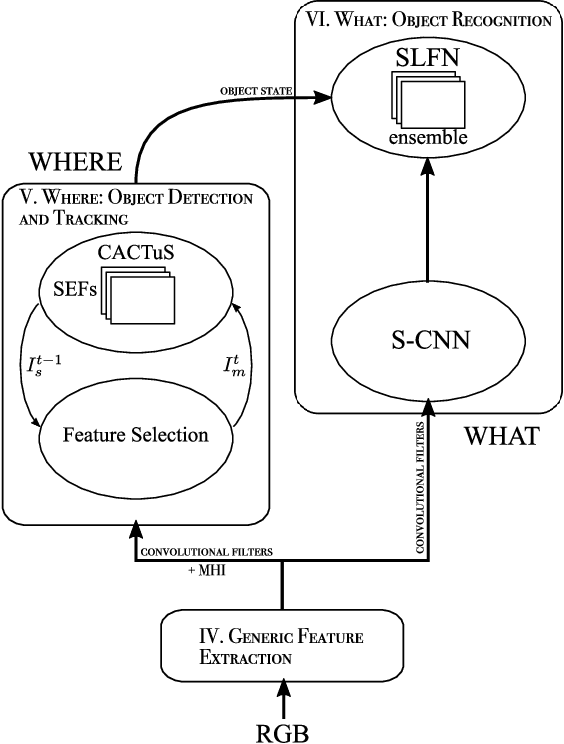
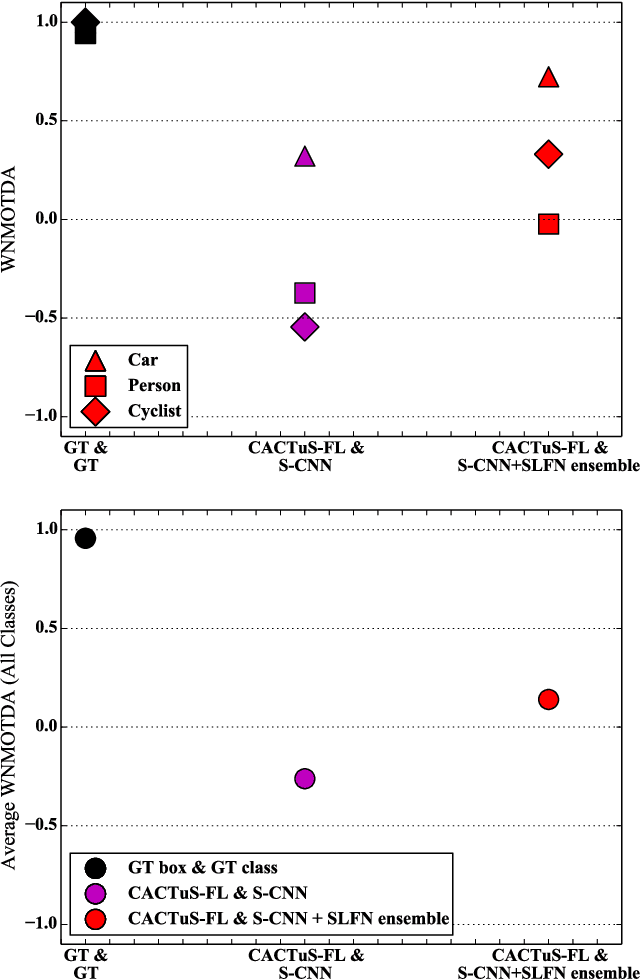


This paper addresses the problem of online tracking and classification of multiple objects in an image sequence. Our proposed solution is to first track all objects in the scene without relying on object-specific prior knowledge, which in other systems can take the form of hand-crafted features or user-based track initialization. We then classify the tracked objects with a fast-learning image classifier that is based on a shallow convolutional neural network architecture and demonstrate that object recognition improves when this is combined with object state information from the tracking algorithm. We argue that by transferring the use of prior knowledge from the detection and tracking stages to the classification stage we can design a robust, general purpose object recognition system with the ability to detect and track a variety of object types. We describe our biologically inspired implementation, which adaptively learns the shape and motion of tracked objects, and apply it to the Neovision2 Tower benchmark data set, which contains multiple object types. An experimental evaluation demonstrates that our approach is competitive with state-of-the-art video object recognition systems that do make use of object-specific prior knowledge in detection and tracking, while providing additional practical advantages by virtue of its generality.
Understanding data augmentation for classification: when to warp?
Nov 26, 2016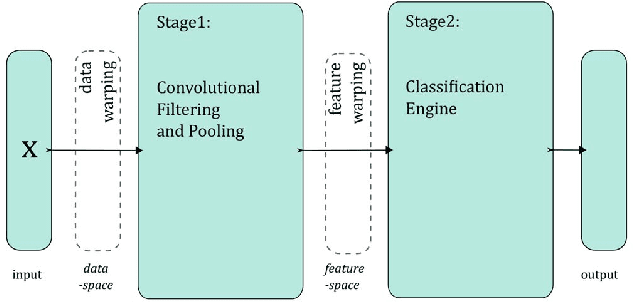

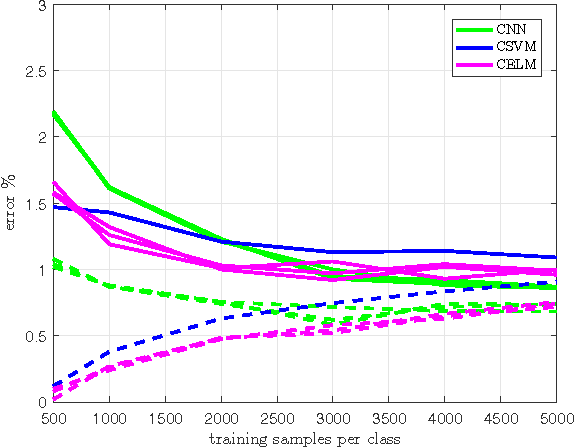
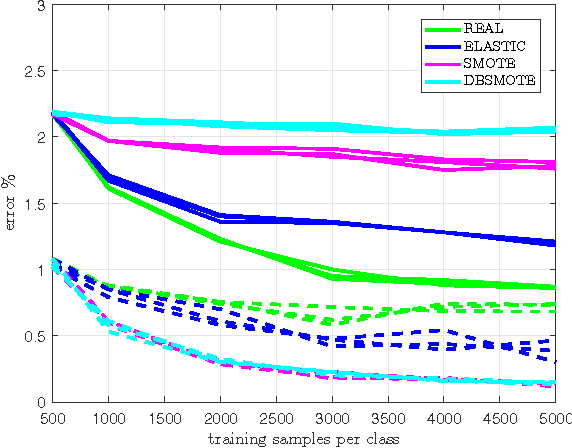
In this paper we investigate the benefit of augmenting data with synthetically created samples when training a machine learning classifier. Two approaches for creating additional training samples are data warping, which generates additional samples through transformations applied in the data-space, and synthetic over-sampling, which creates additional samples in feature-space. We experimentally evaluate the benefits of data augmentation for a convolutional backpropagation-trained neural network, a convolutional support vector machine and a convolutional extreme learning machine classifier, using the standard MNIST handwritten digit dataset. We found that while it is possible to perform generic augmentation in feature-space, if plausible transforms for the data are known then augmentation in data-space provides a greater benefit for improving performance and reducing overfitting.