 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Convolutional Neural Networks using their Spectral Response
Oct 08, 2018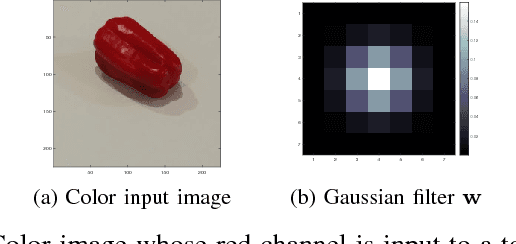

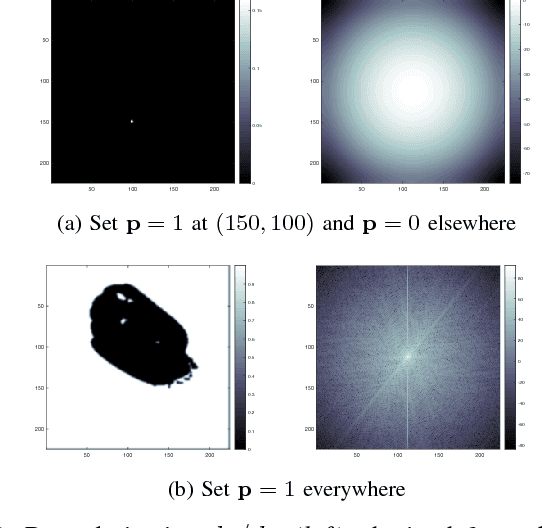

Convolutional Neural Networks (CNNs) are a class of artificial neural networks whose computational blocks use convolution, together with other linear and non-linear operations, to perform classification or regression. This paper explores the spectral response of CNNs and its potential use in diagnosing problems with their training. We measure the gain of CNNs trained for image classification on ImageNet and observe that the best models are also the most sensitive to perturbations of their input. Further, we perform experiments on MNIST and CIFAR-10 to find that the gain rises as the network learns and then saturates as the network converges. Moreover, we find that strong gain fluctuations can point to overfitting and learning problems caused by a poor choice of learning rate. We argue that the gain of CNNs can act as a diagnostic tool and potential replacement for the validation loss when hold-out validation data are not available.
Automatic Ground Truths: Projected Image Annotations for Omnidirectional Vision
Sep 12, 2017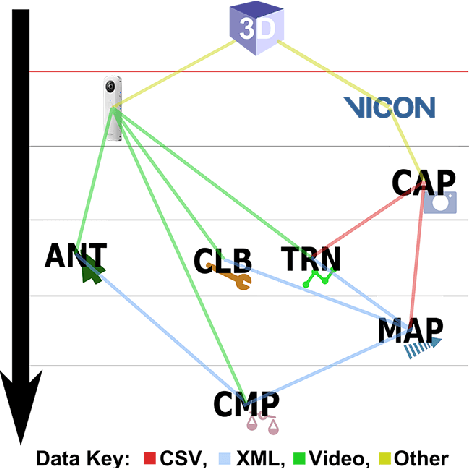



We present a novel data set made up of omnidirectional video of multiple objects whose centroid positions are annotated automatically. Omnidirectional vision is an active field of research focused on the use of spherical imagery in video analysis and scene understanding, involving tasks such as object detection, tracking and recognition. Our goal is to provide a large and consistently annotated video data set that can be used to train and evaluate new algorithms for these tasks. Here we describe the experimental setup and software environment used to capture and map the 3D ground truth positions of multiple objects into the image. Furthermore, we estimate the expected systematic error on the mapped positions. In addition to final data products, we release publicly the software tools and raw data necessary to re-calibrate the camera and/or redo this mapping. The software also provides a simple framework for comparing the results of standard image annotation tools or visual tracking systems against our mapped ground truth annotations.
Track Everything: Limiting Prior Knowledge in Online Multi-Object Recognition
Apr 21, 2017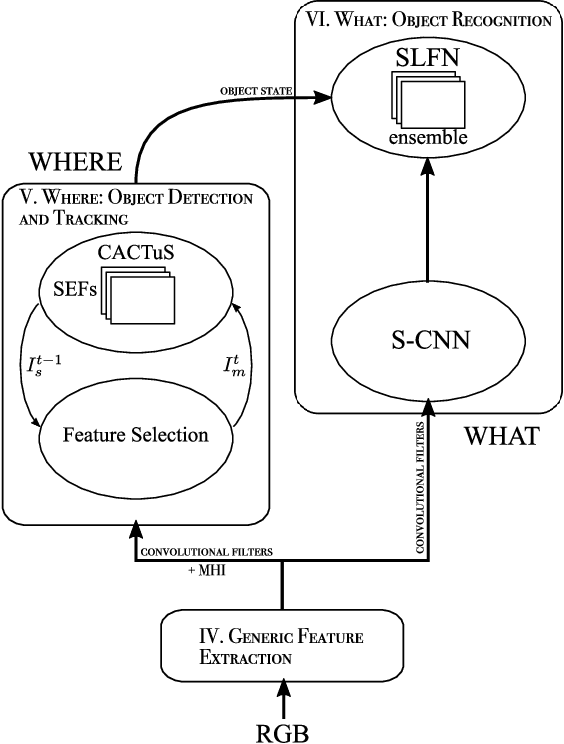
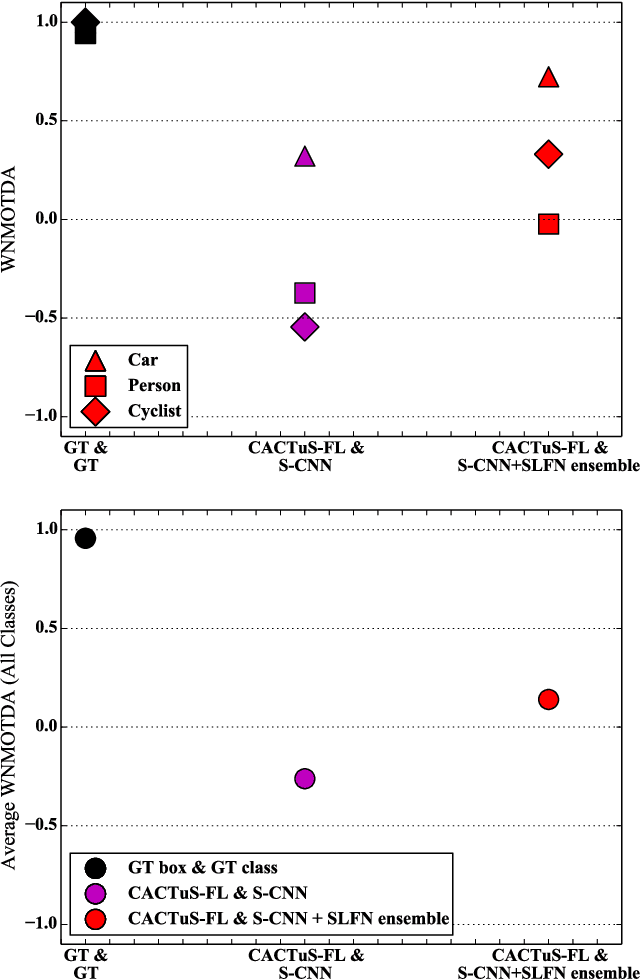


This paper addresses the problem of online tracking and classification of multiple objects in an image sequence. Our proposed solution is to first track all objects in the scene without relying on object-specific prior knowledge, which in other systems can take the form of hand-crafted features or user-based track initialization. We then classify the tracked objects with a fast-learning image classifier that is based on a shallow convolutional neural network architecture and demonstrate that object recognition improves when this is combined with object state information from the tracking algorithm. We argue that by transferring the use of prior knowledge from the detection and tracking stages to the classification stage we can design a robust, general purpose object recognition system with the ability to detect and track a variety of object types. We describe our biologically inspired implementation, which adaptively learns the shape and motion of tracked objects, and apply it to the Neovision2 Tower benchmark data set, which contains multiple object types. An experimental evaluation demonstrates that our approach is competitive with state-of-the-art video object recognition systems that do make use of object-specific prior knowledge in detection and tracking, while providing additional practical advantages by virtue of its generality.
A data set for evaluating the performance of multi-class multi-object video tracking
Apr 21, 2017One of the challenges in evaluating multi-object video detection, tracking and classification systems is having publically available data sets with which to compare different systems. However, the measures of performance for tracking and classification are different. Data sets that are suitable for evaluating tracking systems may not be appropriate for classification. Tracking video data sets typically only have ground truth track IDs, while classification video data sets only have ground truth class-label IDs. The former identifies the same object over multiple frames, while the latter identifies the type of object in individual frames. This paper describes an advancement of the ground truth meta-data for the DARPA Neovision2 Tower data set to allow both the evaluation of tracking and classification. The ground truth data sets presented in this paper contain unique object IDs across 5 different classes of object (Car, Bus, Truck, Person, Cyclist) for 24 videos of 871 image frames each. In addition to the object IDs and class labels, the ground truth data also contains the original bounding box coordinates together with new bounding boxes in instances where un-annotated objects were present. The unique IDs are maintained during occlusions between multiple objects or when objects re-enter the field of view. This will provide: a solid foundation for evaluating the performance of multi-object tracking of different types of objects, a straightforward comparison of tracking system performance using the standard Multi Object Tracking (MOT) framework, and classification performance using the Neovision2 metrics. These data have been hosted publically.
Understanding data augmentation for classification: when to warp?
Nov 26, 2016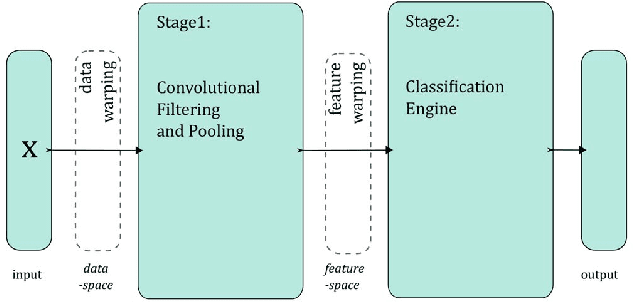

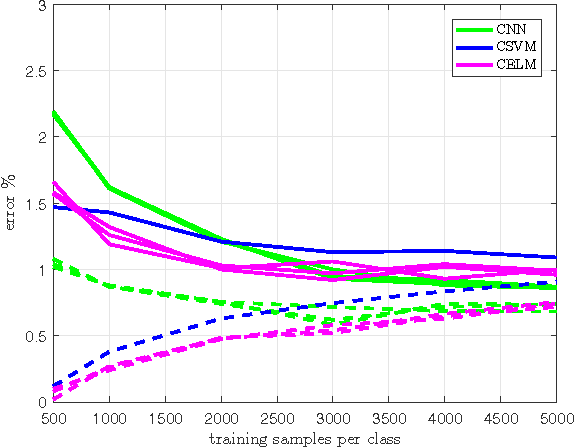
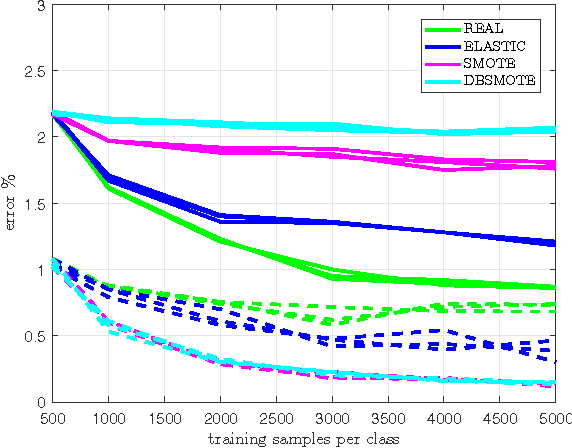
In this paper we investigate the benefit of augmenting data with synthetically created samples when training a machine learning classifier. Two approaches for creating additional training samples are data warping, which generates additional samples through transformations applied in the data-space, and synthetic over-sampling, which creates additional samples in feature-space. We experimentally evaluate the benefits of data augmentation for a convolutional backpropagation-trained neural network, a convolutional support vector machine and a convolutional extreme learning machine classifier, using the standard MNIST handwritten digit dataset. We found that while it is possible to perform generic augmentation in feature-space, if plausible transforms for the data are known then augmentation in data-space provides a greater benefit for improving performance and reducing overfitting.