 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAKESET: A Large-Scale, High-Reynolds Number Flow Dataset for Machine Learning of Turbulent Wake Dynamics
Feb 01, 2026Machine learning (ML) offers transformative potential for computational fluid dynamics (CFD), promising to accelerate simulations, improve turbulence modelling, and enable real-time flow prediction and control-capabilities that could fundamentally change how engineers approach fluid dynamics problems. However, the exploration of ML in fluid dynamics is critically hampered by the scarcity of large, diverse, and high-fidelity datasets suitable for training robust models. This limitation is particularly acute for highly turbulent flows, which dominate practical engineering applications yet remain computationally prohibitive to simulate at scale. High-Reynolds number turbulent datasets are essential for ML models to learn the complex, multi-scale physics characteristic of real-world flows, enabling generalisation beyond the simplified, low-Reynolds number regimes often represented in existing datasets. This paper introduces WAKESET, a novel, large-scale CFD dataset of highly turbulent flows, designed to address this critical gap. The dataset captures the complex hydrodynamic interactions during the underwater recovery of an autonomous underwater vehicle by a larger extra-large uncrewed underwater vehicle. It comprises 1,091 high-fidelity Reynolds-Averaged Navier-Stokes simulations, augmented to 4,364 instances, covering a wide operational envelope of speeds (up to Reynolds numbers of 1.09 x 10^8) and turning angles. This work details the motivation for this new dataset by reviewing existing resources, outlines the hydrodynamic modelling and validation underpinning its creation, and describes its structure. The dataset's focus on a practical engineering problem, its scale, and its high turbulence characteristics make it a valuable resource for developing and benchmarking ML models for flow field prediction, surrogate modelling, and autonomous navigation in complex underwater environments.
A generalised novel loss function for computational fluid dynamics
Nov 26, 2024



Computational fluid dynamics (CFD) simulations are crucial in automotive, aerospace, maritime and medical applications, but are limited by the complexity, cost and computational requirements of directly calculating the flow, often taking days of compute time. Machine-learning architectures, such as controlled generative adversarial networks (cGANs) hold significant potential in enhancing or replacing CFD investigations, due to cGANs ability to approximate the underlying data distribution of a dataset. Unlike traditional cGAN applications, where the entire image carries information, CFD data contains small regions of highly variant data, immersed in a large context of low variance that is of minimal importance. This renders most existing deep learning techniques that give equal importance to every portion of the data during training, inefficient. To mitigate this, a novel loss function is proposed called Gradient Mean Squared Error (GMSE) which automatically and dynamically identifies the regions of importance on a field-by-field basis, assigning appropriate weights according to the local variance. To assess the effectiveness of the proposed solution, three identical networks were trained; optimised with Mean Squared Error (MSE) loss, proposed GMSE loss and a dynamic variant of GMSE (DGMSE). The novel loss function resulted in faster loss convergence, correlating to reduced training time, whilst also displaying an 83.6% reduction in structural similarity error between the generated field and ground truth simulations, a 76.6% higher maximum rate of loss and an increased ability to fool a discriminator network. It is hoped that this loss function will enable accelerated machine learning within computational fluid dynamics.
Automatic Ground Truths: Projected Image Annotations for Omnidirectional Vision
Sep 12, 2017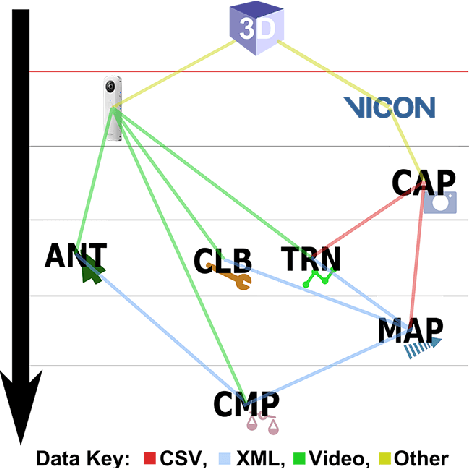



We present a novel data set made up of omnidirectional video of multiple objects whose centroid positions are annotated automatically. Omnidirectional vision is an active field of research focused on the use of spherical imagery in video analysis and scene understanding, involving tasks such as object detection, tracking and recognition. Our goal is to provide a large and consistently annotated video data set that can be used to train and evaluate new algorithms for these tasks. Here we describe the experimental setup and software environment used to capture and map the 3D ground truth positions of multiple objects into the image. Furthermore, we estimate the expected systematic error on the mapped positions. In addition to final data products, we release publicly the software tools and raw data necessary to re-calibrate the camera and/or redo this mapping. The software also provides a simple framework for comparing the results of standard image annotation tools or visual tracking systems against our mapped ground truth annotations.