 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairGP: A Scalable and Fair Graph Transformer Using Graph Partitioning
Dec 14, 2024Recent studies have highlighted significant fairness issues in Graph Transformer (GT) models, particularly against subgroups defined by sensitive features. Additionally, GTs are computationally intensive and memory-demanding, limiting their application to large-scale graphs. Our experiments demonstrate that graph partitioning can enhance the fairness of GT models while reducing computational complexity. To understand this improvement, we conducted a theoretical investigation into the root causes of fairness issues in GT models. We found that the sensitive features of higher-order nodes disproportionately influence lower-order nodes, resulting in sensitive feature bias. We propose Fairness-aware scalable GT based on Graph Partitioning (FairGP), which partitions the graph to minimize the negative impact of higher-order nodes. By optimizing attention mechanisms, FairGP mitigates the bias introduced by global attention, thereby enhancing fairness. Extensive empirical evaluations on six real-world datasets validate the superior performance of FairGP in achieving fairness compared to state-of-the-art methods. The codes are available at https://github.com/LuoRenqiang/FairGP.
SalNAS: Efficient Saliency-prediction Neural Architecture Search with self-knowledge distillation
Jul 29, 2024



Recent advancements in deep convolutional neural networks have significantly improved the performance of saliency prediction. However, the manual configuration of the neural network architectures requires domain knowledge expertise and can still be time-consuming and error-prone. To solve this, we propose a new Neural Architecture Search (NAS) framework for saliency prediction with two contributions. Firstly, a supernet for saliency prediction is built with a weight-sharing network containing all candidate architectures, by integrating a dynamic convolution into the encoder-decoder in the supernet, termed SalNAS. Secondly, despite the fact that SalNAS is highly efficient (20.98 million parameters), it can suffer from the lack of generalization. To solve this, we propose a self-knowledge distillation approach, termed Self-KD, that trains the student SalNAS with the weighted average information between the ground truth and the prediction from the teacher model. The teacher model, while sharing the same architecture, contains the best-performing weights chosen by cross-validation. Self-KD can generalize well without the need to compute the gradient in the teacher model, enabling an efficient training system. By utilizing Self-KD, SalNAS outperforms other state-of-the-art saliency prediction models in most evaluation rubrics across seven benchmark datasets while being a lightweight model. The code will be available at https://github.com/chakkritte/SalNAS
* Published in Engineering Applications of Artificial Intelligence
Collaborative Team Recognition: A Core Plus Extension Structure
Jun 07, 2024
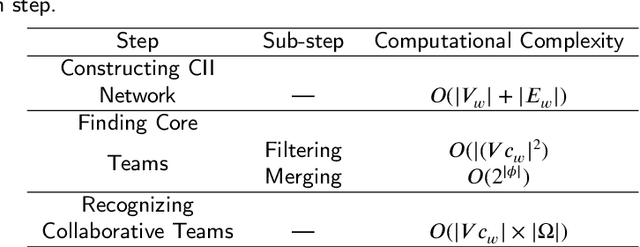
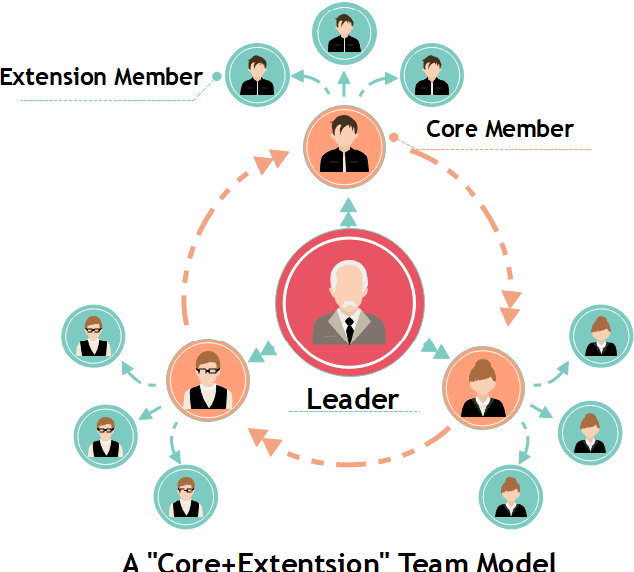
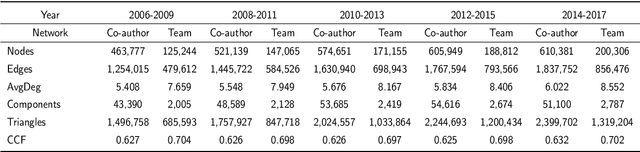
Scientific collaboration is a significant behavior in knowledge creation and idea exchange. To tackle large and complex research questions, a trend of team formation has been observed in recent decades. In this study, we focus on recognizing collaborative teams and exploring inner patterns using scholarly big graph data. We propose a collaborative team recognition (CORE) model with a "core + extension" team structure to recognize collaborative teams in large academic networks. In CORE, we combine an effective evaluation index called the collaboration intensity index with a series of structural features to recognize collaborative teams in which members are in close collaboration relationships. Then, CORE is used to guide the core team members to their extension members. CORE can also serve as the foundation for team-based research. The simulation results indicate that CORE reveals inner patterns of scientific collaboration: senior scholars have broad collaborative relationships and fixed collaboration patterns, which are the underlying mechanisms of team assembly. The experimental results demonstrate that CORE is promising compared with state-of-the-art methods.
Exploring the Relationship Between Model Architecture and In-Context Learning Ability
Oct 12, 2023

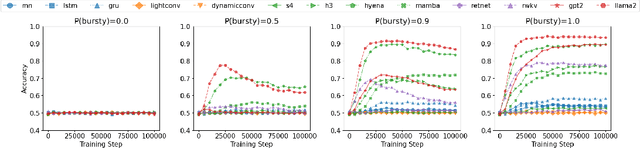

What is the relationship between model architecture and the ability to perform in-context learning? In this empirical study, we take the first steps towards answering this question. In particular, we evaluate fifteen model architectures across a suite of synthetic in-context learning tasks. The selected architectures represent a broad range of paradigms, including recurrent and convolution-based neural networks, transformers, and emerging attention alternatives. We discover that all considered architectures can perform in-context learning under certain conditions. However, contemporary architectures are found to be the best performing, especially as task complexity grows. Additionally, our follow-up experiments delve into various factors that influence in-context learning. We observe varied sensitivities among architectures with respect to hyperparameter settings. Our study of training dynamics reveals that certain architectures exhibit a smooth, progressive learning trajectory, while others demonstrate periods of stagnation followed by abrupt mastery of the task. Finally, and somewhat surprisingly, we find that several emerging attention alternatives are more robust in-context learners than transformers; since such approaches have constant-sized memory footprints at inference time, this result opens the future possibility of scaling up in-context learning to vastly larger numbers of in-context examples.
Explainable Knowledge Distillation for On-device Chest X-Ray Classification
May 10, 2023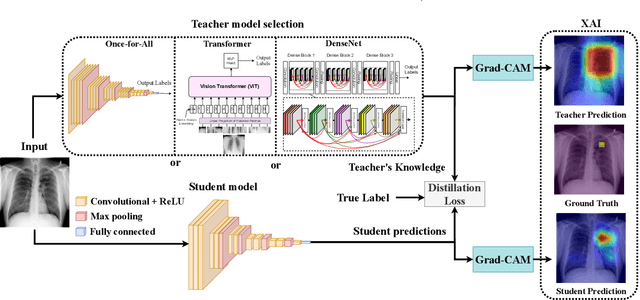

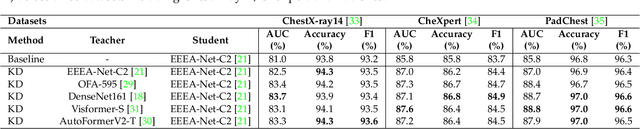
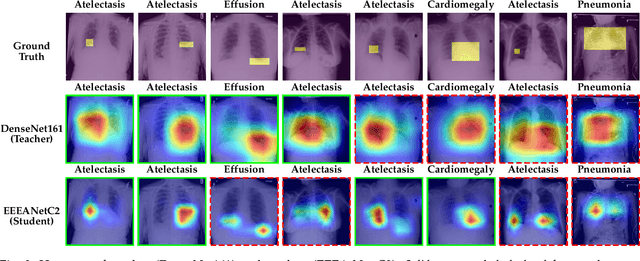
Automated multi-label chest X-rays (CXR) image classification has achieved substantial progress in clinical diagnosis via utilizing sophisticated deep learning approaches. However, most deep models have high computational demands, which makes them less feasible for compact devices with low computational requirements. To overcome this problem, we propose a knowledge distillation (KD) strategy to create the compact deep learning model for the real-time multi-label CXR image classification. We study different alternatives of CNNs and Transforms as the teacher to distill the knowledge to a smaller student. Then, we employed explainable artificial intelligence (XAI) to provide the visual explanation for the model decision improved by the KD. Our results on three benchmark CXR datasets show that our KD strategy provides the improved performance on the compact student model, thus being the feasible choice for many limited hardware platforms. For instance, when using DenseNet161 as the teacher network, EEEA-Net-C2 achieved an AUC of 83.7%, 87.1%, and 88.7% on the ChestX-ray14, CheXpert, and PadChest datasets, respectively, with fewer parameters of 4.7 million and computational cost of 0.3 billion FLOPS.
NEAR: Named Entity and Attribute Recognition of clinical concepts
Aug 30, 2022

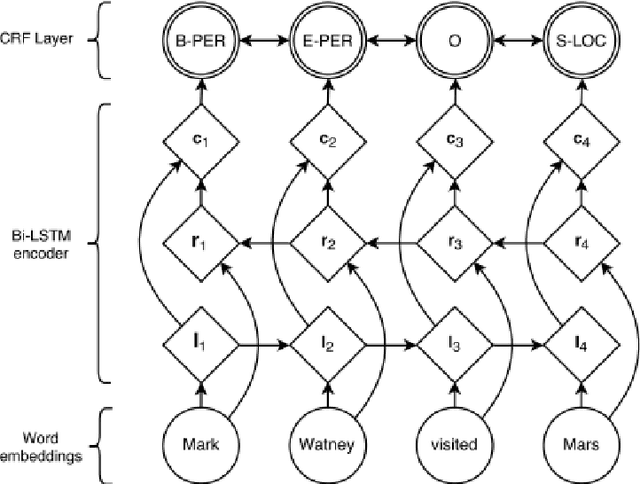
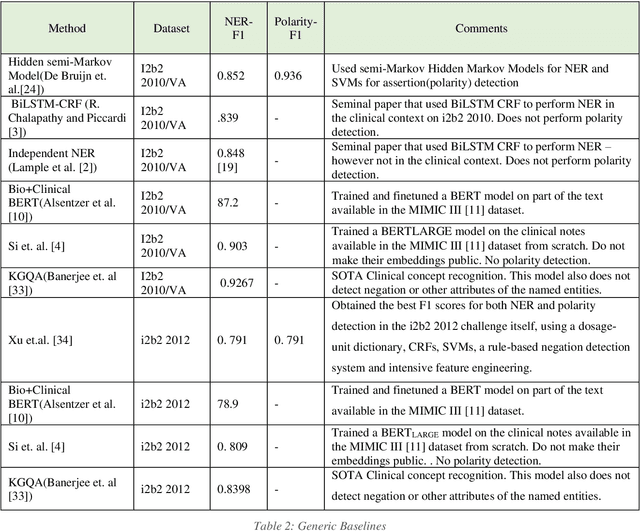
Named Entity Recognition (NER) or the extraction of concepts from clinical text is the task of identifying entities in text and slotting them into categories such as problems, treatments, tests, clinical departments, occurrences (such as admission and discharge) and others. NER forms a critical component of processing and leveraging unstructured data from Electronic Health Records (EHR). While identifying the spans and categories of concepts is itself a challenging task, these entities could also have attributes such as negation that pivot their meanings implied to the consumers of the named entities. There has been little research dedicated to identifying the entities and their qualifying attributes together. This research hopes to contribute to the area of detecting entities and their corresponding attributes by modelling the NER task as a supervised, multi-label tagging problem with each of the attributes assigned tagging sequence labels. In this paper, we propose 3 architectures to achieve this multi-label entity tagging: BiLSTM n-CRF, BiLSTM-CRF-Smax-TF and BiLSTM n-CRF-TF. We evaluate these methods on the 2010 i2b2/VA and the i2b2 2012 shared task datasets. Our different models obtain best NER F1 scores of 0. 894 and 0.808 on the i2b2 2010/VA and i2b2 2012 respectively. The highest span based micro-averaged F1 polarity scores obtained were 0.832 and 0.836 on the i2b2 2010/VA and i2b2 2012 datasets respectively, and the highest macro-averaged F1 polarity scores obtained were 0.924 and 0.888 respectively. The modality studies conducted on i2b2 2012 dataset revealed high scores of 0.818 and 0.501 for span based micro-averaged F1 and macro-averaged F1 respectively.
* 11 pages, 7 figures, 9 tables
CHIEF: Clustering with Higher-order Motifs in Big Networks
Apr 06, 2022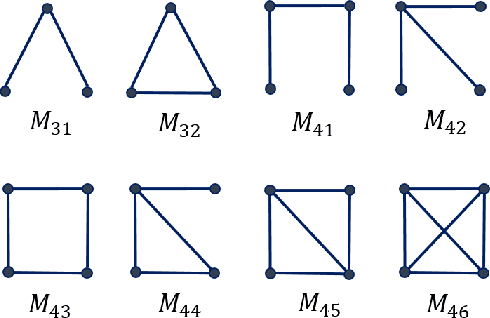

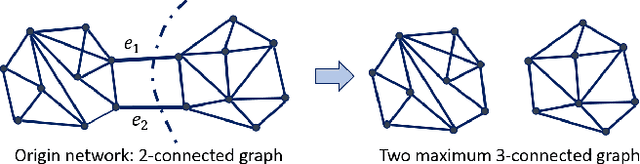
Clustering a group of vertices in networks facilitates applications across different domains, such as social computing and Internet of Things. However, challenges arises for clustering networks with increased scale. This paper proposes a solution which consists of two motif clustering techniques: standard acceleration CHIEF-ST and approximate acceleration CHIEF-AP. Both algorithms first find the maximal k-edge-connected subgraphs within the target networks to lower the network scale, then employ higher-order motifs in clustering. In the first procedure, we propose to lower the network scale by optimizing the network structure with maximal k-edge-connected subgraphs. For CHIEF-ST, we illustrate that all target motifs will be kept after this procedure when the minimum node degree of the target motif is equal or greater than k. For CHIEF-AP, we prove that the eigenvalues of the adjacency matrix and the Laplacian matrix are relatively stable after this step. That is, CHIEF-ST has no influence on motif clustering, whereas CHIEF-AP introduces limited yet acceptable impact. In the second procedure, we employ higher-order motifs, i.e., heterogeneous four-node motifs clustering in higher-order dense networks. The contributions of CHIEF are two-fold: (1) improved efficiency of motif clustering for big networks; (2) verification of higher-order motif significance. The proposed solutions are found to outperform baseline approaches according to experiments on real and synthetic networks, which demonstrates CHIEF's strength in large network analysis. Meanwhile, higher-order motifs are proved to perform better than traditional triangle motifs in clustering.
Web of Scholars: A Scholar Knowledge Graph
Feb 23, 2022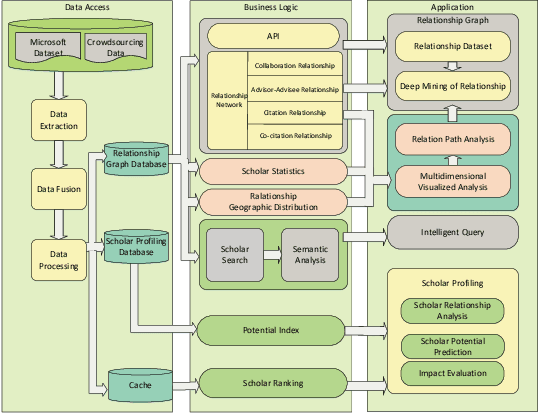


In this work, we demonstrate a novel system, namely Web of Scholars, which integrates state-of-the-art mining techniques to search, mine, and visualize complex networks behind scholars in the field of Computer Science. Relying on the knowledge graph, it provides services for fast, accurate, and intelligent semantic querying as well as powerful recommendations. In addition, in order to realize information sharing, it provides an open API to be served as the underlying architecture for advanced functions. Web of Scholars takes advantage of knowledge graph, which means that it will be able to access more knowledge if more search exist. It can be served as a useful and interoperable tool for scholars to conduct in-depth analysis within Science of Science.
Heterogeneous Graph Learning for Explainable Recommendation over Academic Networks
Feb 16, 2022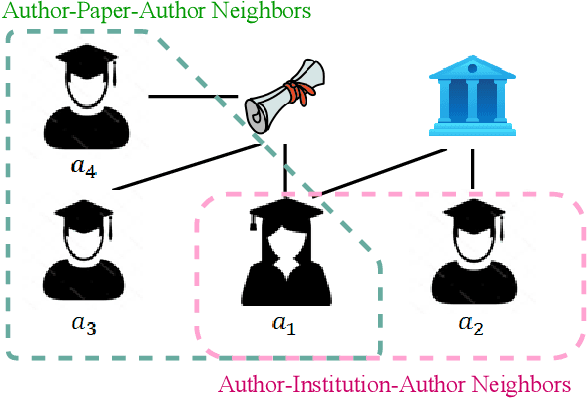



With the explosive growth of new graduates with research degrees every year, unprecedented challenges arise for early-career researchers to find a job at a suitable institution. This study aims to understand the behavior of academic job transition and hence recommend suitable institutions for PhD graduates. Specifically, we design a deep learning model to predict the career move of early-career researchers and provide suggestions. The design is built on top of scholarly/academic networks, which contains abundant information about scientific collaboration among scholars and institutions. We construct a heterogeneous scholarly network to facilitate the exploring of the behavior of career moves and the recommendation of institutions for scholars. We devise an unsupervised learning model called HAI (Heterogeneous graph Attention InfoMax) which aggregates attention mechanism and mutual information for institution recommendation. Moreover, we propose scholar attention and meta-path attention to discover the hidden relationships between several meta-paths. With these mechanisms, HAI provides ordered recommendations with explainability. We evaluate HAI upon a real-world dataset against baseline methods. Experimental results verify the effectiveness and efficiency of our approach.
* 8 pages, 5 figures
Masked Measurement Prediction: Learning to Jointly Predict Quantities and Units from Textual Context
Dec 16, 2021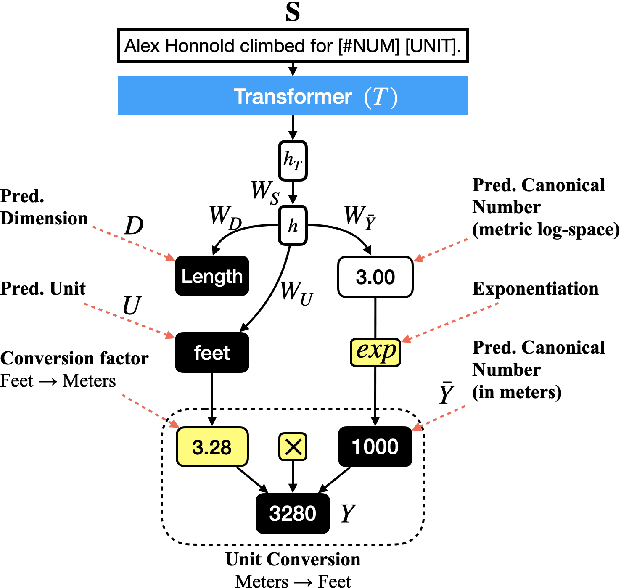
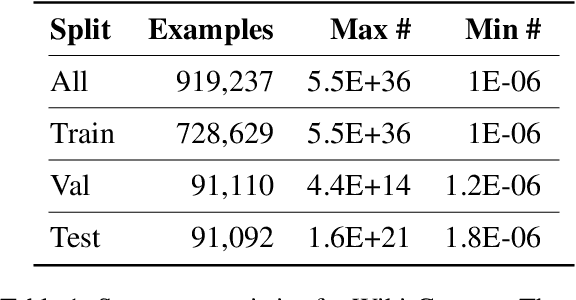
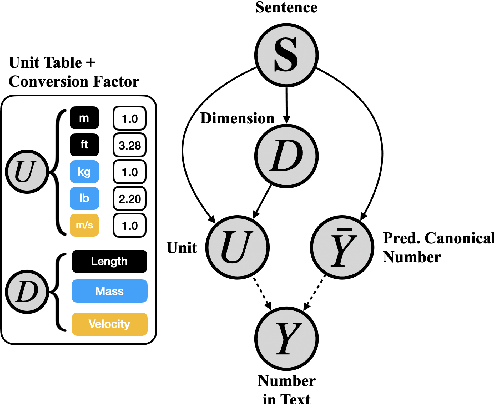
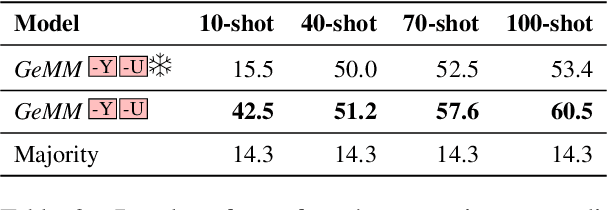
Physical measurements constitute a large portion of numbers in academic papers, engineering reports, and web tables. Current benchmarks fall short of properly evaluating numeracy of pretrained language models on measurements, hindering research on developing new methods and applying them to numerical tasks. To that end, we introduce a novel task, Masked Measurement Prediction (MMP), where a model learns to reconstruct a number together with its associated unit given masked text. MMP is useful for both training new numerically informed models as well as evaluating numeracy of existing systems. In order to address this task, we introduce a new Generative Masked Measurement (GeMM) model that jointly learns to predict numbers along with their units. We perform fine-grained analyses comparing our model with various ablations and baselines. We use linear probing of traditional pretrained transformer models (RoBERTa) to show that they significantly underperform jointly trained number-unit models, highlighting the difficulty of this new task and the benefits of our proposed pretraining approach. We hope this framework accelerates the progress towards building more robust numerical reasoning systems in the future.