 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalNAS: Efficient Saliency-prediction Neural Architecture Search with self-knowledge distillation
Jul 29, 2024



Recent advancements in deep convolutional neural networks have significantly improved the performance of saliency prediction. However, the manual configuration of the neural network architectures requires domain knowledge expertise and can still be time-consuming and error-prone. To solve this, we propose a new Neural Architecture Search (NAS) framework for saliency prediction with two contributions. Firstly, a supernet for saliency prediction is built with a weight-sharing network containing all candidate architectures, by integrating a dynamic convolution into the encoder-decoder in the supernet, termed SalNAS. Secondly, despite the fact that SalNAS is highly efficient (20.98 million parameters), it can suffer from the lack of generalization. To solve this, we propose a self-knowledge distillation approach, termed Self-KD, that trains the student SalNAS with the weighted average information between the ground truth and the prediction from the teacher model. The teacher model, while sharing the same architecture, contains the best-performing weights chosen by cross-validation. Self-KD can generalize well without the need to compute the gradient in the teacher model, enabling an efficient training system. By utilizing Self-KD, SalNAS outperforms other state-of-the-art saliency prediction models in most evaluation rubrics across seven benchmark datasets while being a lightweight model. The code will be available at https://github.com/chakkritte/SalNAS
* Published in Engineering Applications of Artificial Intelligence
Explainable Knowledge Distillation for On-device Chest X-Ray Classification
May 10, 2023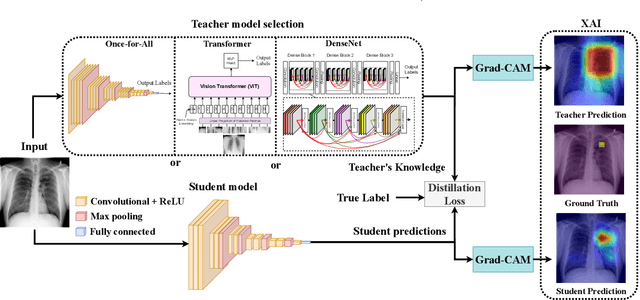

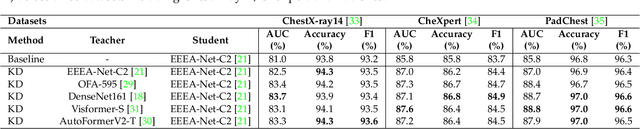
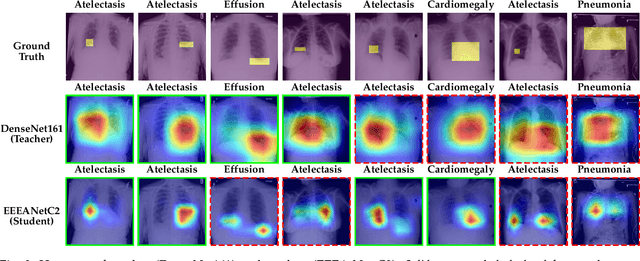
Automated multi-label chest X-rays (CXR) image classification has achieved substantial progress in clinical diagnosis via utilizing sophisticated deep learning approaches. However, most deep models have high computational demands, which makes them less feasible for compact devices with low computational requirements. To overcome this problem, we propose a knowledge distillation (KD) strategy to create the compact deep learning model for the real-time multi-label CXR image classification. We study different alternatives of CNNs and Transforms as the teacher to distill the knowledge to a smaller student. Then, we employed explainable artificial intelligence (XAI) to provide the visual explanation for the model decision improved by the KD. Our results on three benchmark CXR datasets show that our KD strategy provides the improved performance on the compact student model, thus being the feasible choice for many limited hardware platforms. For instance, when using DenseNet161 as the teacher network, EEEA-Net-C2 achieved an AUC of 83.7%, 87.1%, and 88.7% on the ChestX-ray14, CheXpert, and PadChest datasets, respectively, with fewer parameters of 4.7 million and computational cost of 0.3 billion FLOPS.
EEEA-Net: An Early Exit Evolutionary Neural Architecture Search
Aug 13, 2021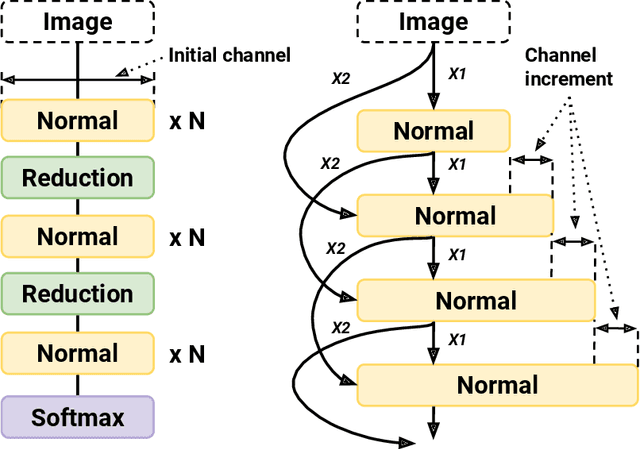

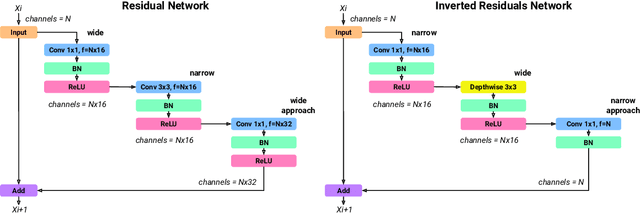
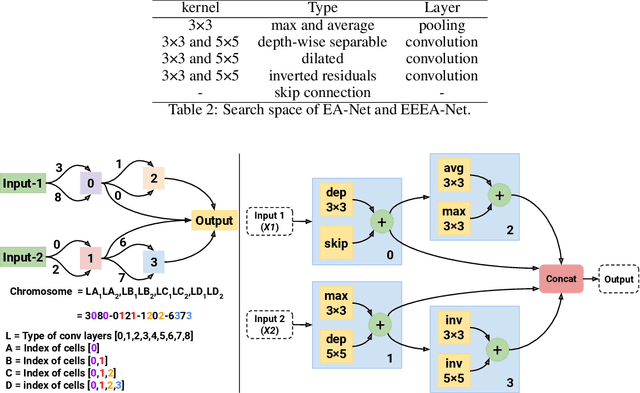
The goals of this research were to search for Convolutional Neural Network (CNN) architectures, suitable for an on-device processor with limited computing resources, performing at substantially lower Network Architecture Search (NAS) costs. A new algorithm entitled an Early Exit Population Initialisation (EE-PI) for Evolutionary Algorithm (EA) was developed to achieve both goals. The EE-PI reduces the total number of parameters in the search process by filtering the models with fewer parameters than the maximum threshold. It will look for a new model to replace those models with parameters more than the threshold. Thereby, reducing the number of parameters, memory usage for model storage and processing time while maintaining the same performance or accuracy. The search time was reduced to 0.52 GPU day. This is a huge and significant achievement compared to the NAS of 4 GPU days achieved using NSGA-Net, 3,150 GPU days by the AmoebaNet model, and the 2,000 GPU days by the NASNet model. As well, Early Exit Evolutionary Algorithm networks (EEEA-Nets) yield network architectures with minimal error and computational cost suitable for a given dataset as a class of network algorithms. Using EEEA-Net on CIFAR-10, CIFAR-100, and ImageNet datasets, our experiments showed that EEEA-Net achieved the lowest error rate among state-of-the-art NAS models, with 2.46% for CIFAR-10, 15.02% for CIFAR-100, and 23.8% for ImageNet dataset. Further, we implemented this image recognition architecture for other tasks, such as object detection, semantic segmentation, and keypoint detection tasks, and, in our experiments, EEEA-Net-C2 outperformed MobileNet-V3 on all of these various tasks. (The algorithm code is available at https://github.com/chakkritte/EEEA-Net).
* Published at Engineering Applications of Artificial Intelligence; Code and pretrained models available at https://github.com/chakkritte/EEEA-Net
NU-LiteNet: Mobile Landmark Recognition using Convolutional Neural Networks
Oct 02, 2018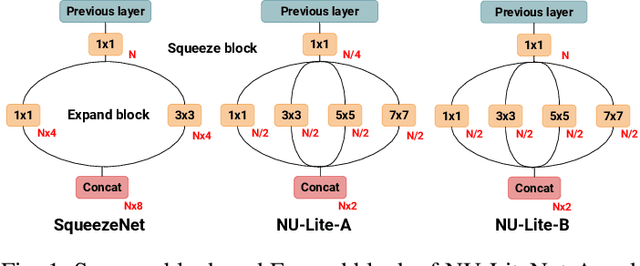


The growth of high-performance mobile devices has resulted in more research into on-device image recognition. The research problems are the latency and accuracy of automatic recognition, which remains obstacles to its real-world usage. Although the recently developed deep neural networks can achieve accuracy comparable to that of a human user, some of them still lack the necessary latency. This paper describes the development of the architecture of a new convolutional neural network model, NU-LiteNet. For this, SqueezeNet was developed to reduce the model size to a degree suitable for smartphones. The model size of NU-LiteNet is therefore 2.6 times smaller than that of SqueezeNet. The recognition accuracy of NU-LiteNet also compared favorably with other recently developed deep neural networks, when experiments were conducted on two standard landmark databases.