 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Relationship Between Model Architecture and In-Context Learning Ability
Paper and Code


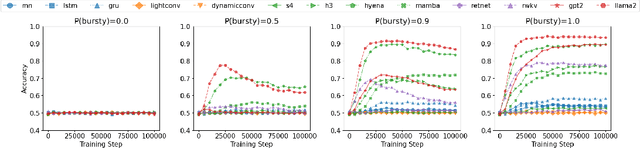

What is the relationship between model architecture and the ability to perform in-context learning? In this empirical study, we take the first steps towards answering this question. In particular, we evaluate fifteen model architectures across a suite of synthetic in-context learning tasks. The selected architectures represent a broad range of paradigms, including recurrent and convolution-based neural networks, transformers, and emerging attention alternatives. We discover that all considered architectures can perform in-context learning under certain conditions. However, contemporary architectures are found to be the best performing, especially as task complexity grows. Additionally, our follow-up experiments delve into various factors that influence in-context learning. We observe varied sensitivities among architectures with respect to hyperparameter settings. Our study of training dynamics reveals that certain architectures exhibit a smooth, progressive learning trajectory, while others demonstrate periods of stagnation followed by abrupt mastery of the task. Finally, and somewhat surprisingly, we find that several emerging attention alternatives are more robust in-context learners than transformers; since such approaches have constant-sized memory footprints at inference time, this result opens the future possibility of scaling up in-context learning to vastly larger numbers of in-context examples.