 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDWCL: Dual-Weighted Contrastive Learning for Multi-View Clustering
Nov 26, 2024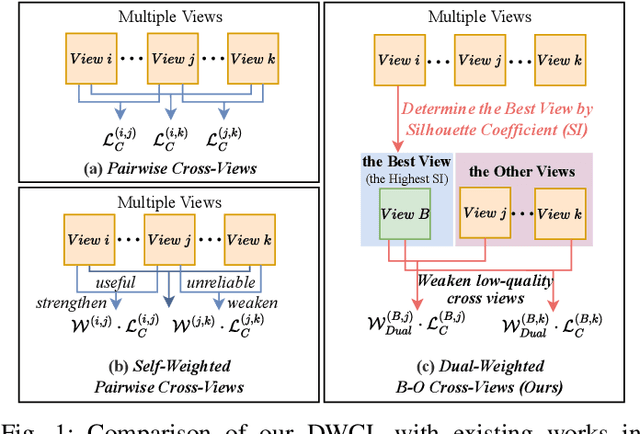
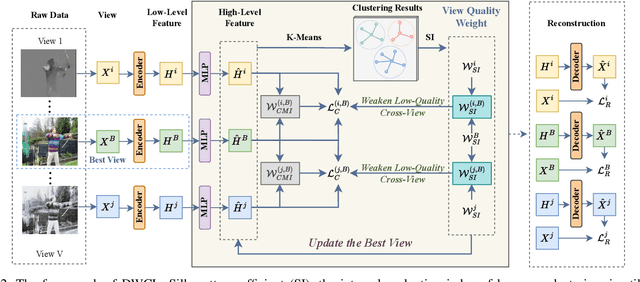
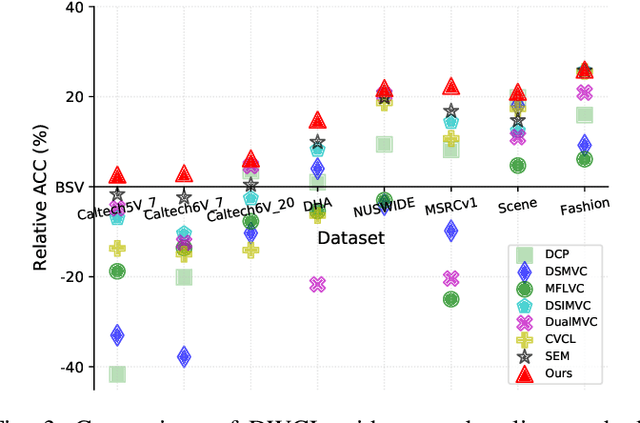
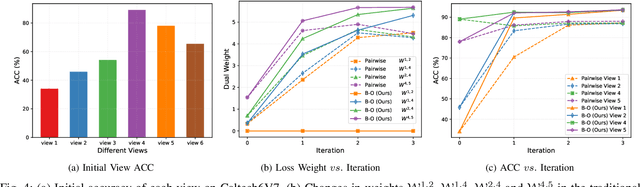
Multi-view contrastive clustering (MVCC) has gained significant attention for generating consistent clustering structures from multiple views through contrastive learning. However, most existing MVCC methods create cross-views by combining any two views, leading to a high volume of unreliable pairs. Furthermore, these approaches often overlook discrepancies in multi-view representations, resulting in representation degeneration. To address these challenges, we introduce a novel model called Dual-Weighted Contrastive Learning (DWCL) for Multi-View Clustering. Specifically, to reduce the impact of unreliable cross-views, we introduce an innovative Best-Other (B-O) contrastive mechanism that enhances the representation of individual views at a low computational cost. Furthermore, we develop a dual weighting strategy that combines a view quality weight, reflecting the quality of each view, with a view discrepancy weight. This approach effectively mitigates representation degeneration by downplaying cross-views that are both low in quality and high in discrepancy. We theoretically validate the efficiency of the B-O contrastive mechanism and the effectiveness of the dual weighting strategy. Extensive experiments demonstrate that DWCL outperforms previous methods across eight multi-view datasets, showcasing superior performance and robustness in MVCC. Specifically, our method achieves absolute accuracy improvements of 5.4\% and 5.6\% compared to state-of-the-art methods on the Caltech6V7 and MSRCv1 datasets, respectively.
Graph Spatiotemporal Process for Multivariate Time Series Anomaly Detection with Missing Values
Jan 11, 2024



The detection of anomalies in multivariate time series data is crucial for various practical applications, including smart power grids, traffic flow forecasting, and industrial process control. However, real-world time series data is usually not well-structured, posting significant challenges to existing approaches: (1) The existence of missing values in multivariate time series data along variable and time dimensions hinders the effective modeling of interwoven spatial and temporal dependencies, resulting in important patterns being overlooked during model training; (2) Anomaly scoring with irregularly-sampled observations is less explored, making it difficult to use existing detectors for multivariate series without fully-observed values. In this work, we introduce a novel framework called GST-Pro, which utilizes a graph spatiotemporal process and anomaly scorer to tackle the aforementioned challenges in detecting anomalies on irregularly-sampled multivariate time series. Our approach comprises two main components. First, we propose a graph spatiotemporal process based on neural controlled differential equations. This process enables effective modeling of multivariate time series from both spatial and temporal perspectives, even when the data contains missing values. Second, we present a novel distribution-based anomaly scoring mechanism that alleviates the reliance on complete uniform observations. By analyzing the predictions of the graph spatiotemporal process, our approach allows anomalies to be easily detected. Our experimental results show that the GST-Pro method can effectively detect anomalies in time series data and outperforms state-of-the-art methods, regardless of whether there are missing values present in the data. Our code is available: https://github.com/huankoh/GST-Pro.
Correlation-aware Spatial-Temporal Graph Learning for Multivariate Time-series Anomaly Detection
Jul 17, 2023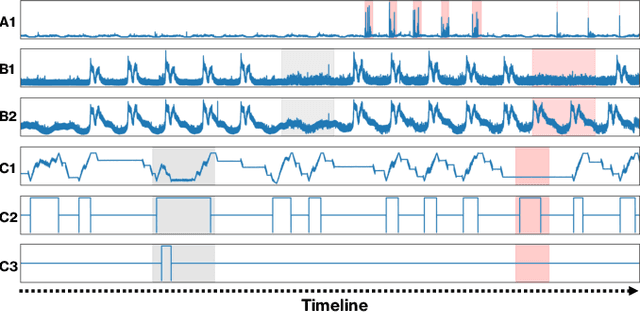
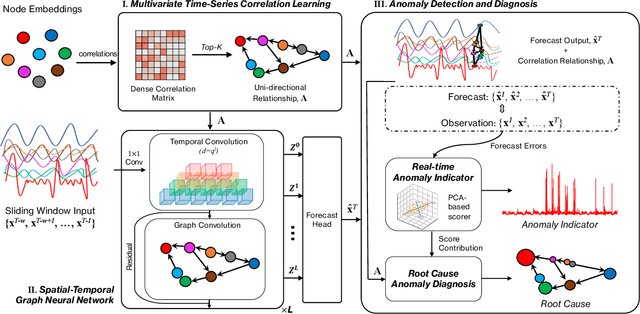


Multivariate time-series anomaly detection is critically important in many applications, including retail, transportation, power grid, and water treatment plants. Existing approaches for this problem mostly employ either statistical models which cannot capture the non-linear relations well or conventional deep learning models (e.g., CNN and LSTM) that do not explicitly learn the pairwise correlations among variables. To overcome these limitations, we propose a novel method, correlation-aware spatial-temporal graph learning (termed CST-GL), for time series anomaly detection. CST-GL explicitly captures the pairwise correlations via a multivariate time series correlation learning module based on which a spatial-temporal graph neural network (STGNN) can be developed. Then, by employing a graph convolution network that exploits one- and multi-hop neighbor information, our STGNN component can encode rich spatial information from complex pairwise dependencies between variables. With a temporal module that consists of dilated convolutional functions, the STGNN can further capture long-range dependence over time. A novel anomaly scoring component is further integrated into CST-GL to estimate the degree of an anomaly in a purely unsupervised manner. Experimental results demonstrate that CST-GL can detect anomalies effectively in general settings as well as enable early detection across different time delays.
eX-ViT: A Novel eXplainable Vision Transformer for Weakly Supervised Semantic Segmentation
Jul 12, 2022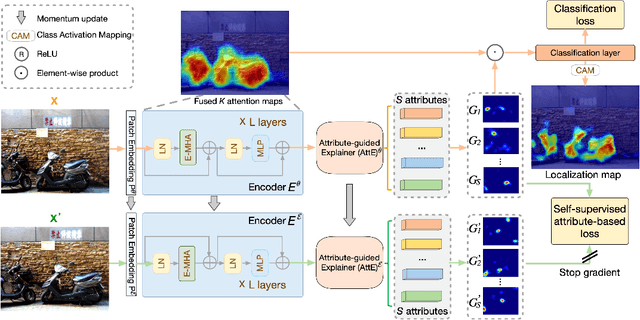



Recently vision transformer models have become prominent models for a range of vision tasks. These models, however, are usually opaque with weak feature interpretability. Moreover, there is no method currently built for an intrinsically interpretable transformer, which is able to explain its reasoning process and provide a faithful explanation. To close these crucial gaps, we propose a novel vision transformer dubbed the eXplainable Vision Transformer (eX-ViT), an intrinsically interpretable transformer model that is able to jointly discover robust interpretable features and perform the prediction. Specifically, eX-ViT is composed of the Explainable Multi-Head Attention (E-MHA) module, the Attribute-guided Explainer (AttE) module and the self-supervised attribute-guided loss. The E-MHA tailors explainable attention weights that are able to learn semantically interpretable representations from local patches in terms of model decisions with noise robustness. Meanwhile, AttE is proposed to encode discriminative attribute features for the target object through diverse attribute discovery, which constitutes faithful evidence for the model's predictions. In addition, a self-supervised attribute-guided loss is developed for our eX-ViT, which aims at learning enhanced representations through the attribute discriminability mechanism and attribute diversity mechanism, to localize diverse and discriminative attributes and generate more robust explanations. As a result, we can uncover faithful and robust interpretations with diverse attributes through the proposed eX-ViT.
Web of Scholars: A Scholar Knowledge Graph
Feb 23, 2022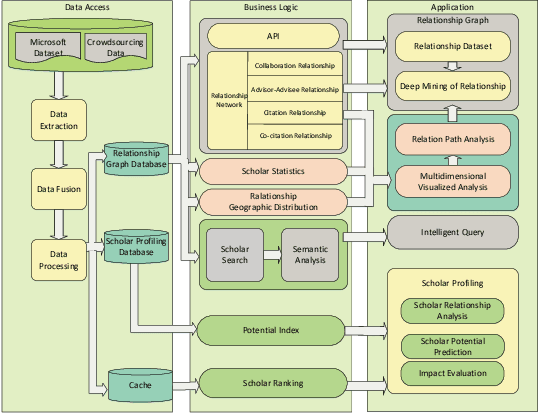


In this work, we demonstrate a novel system, namely Web of Scholars, which integrates state-of-the-art mining techniques to search, mine, and visualize complex networks behind scholars in the field of Computer Science. Relying on the knowledge graph, it provides services for fast, accurate, and intelligent semantic querying as well as powerful recommendations. In addition, in order to realize information sharing, it provides an open API to be served as the underlying architecture for advanced functions. Web of Scholars takes advantage of knowledge graph, which means that it will be able to access more knowledge if more search exist. It can be served as a useful and interoperable tool for scholars to conduct in-depth analysis within Science of Science.
From Unsupervised to Few-shot Graph Anomaly Detection: A Multi-scale Contrastive Learning Approach
Feb 11, 2022Anomaly detection from graph data is an important data mining task in many applications such as social networks, finance, and e-commerce. Existing efforts in graph anomaly detection typically only consider the information in a single scale (view), thus inevitably limiting their capability in capturing anomalous patterns in complex graph data. To address this limitation, we propose a novel framework, graph ANomaly dEtection framework with Multi-scale cONtrastive lEarning (ANEMONE in short). By using a graph neural network as a backbone to encode the information from multiple graph scales (views), we learn better representation for nodes in a graph. In maximizing the agreements between instances at both the patch and context levels concurrently, we estimate the anomaly score of each node with a statistical anomaly estimator according to the degree of agreement from multiple perspectives. To further exploit a handful of ground-truth anomalies (few-shot anomalies) that may be collected in real-life applications, we further propose an extended algorithm, ANEMONE-FS, to integrate valuable information in our method. We conduct extensive experiments under purely unsupervised settings and few-shot anomaly detection settings, and we demonstrate that the proposed method ANEMONE and its variant ANEMONE-FS consistently outperform state-of-the-art algorithms on six benchmark datasets.
Generative and Contrastive Self-Supervised Learning for Graph Anomaly Detection
Aug 23, 2021

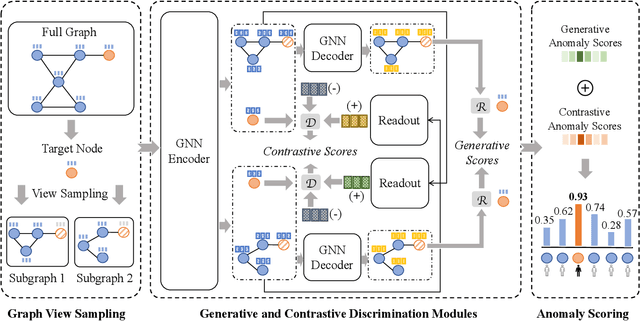
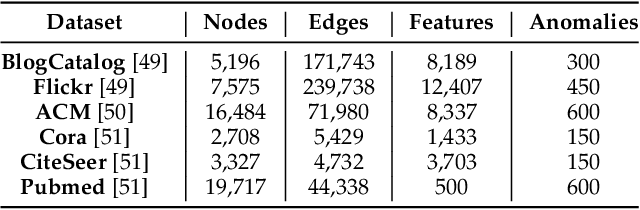
Anomaly detection from graph data has drawn much attention due to its practical significance in many critical applications including cybersecurity, finance, and social networks. Existing data mining and machine learning methods are either shallow methods that could not effectively capture the complex interdependency of graph data or graph autoencoder methods that could not fully exploit the contextual information as supervision signals for effective anomaly detection. To overcome these challenges, in this paper, we propose a novel method, Self-Supervised Learning for Graph Anomaly Detection (SL-GAD). Our method constructs different contextual subgraphs (views) based on a target node and employs two modules, generative attribute regression and multi-view contrastive learning for anomaly detection. While the generative attribute regression module allows us to capture the anomalies in the attribute space, the multi-view contrastive learning module can exploit richer structure information from multiple subgraphs, thus abling to capture the anomalies in the structure space, mixing of structure, and attribute information. We conduct extensive experiments on six benchmark datasets and the results demonstrate that our method outperforms state-of-the-art methods by a large margin.
End-to-end Network for Twitter Geolocation Prediction and Hashing
Oct 13, 2017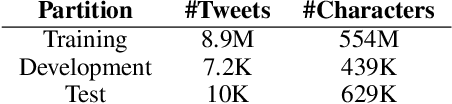
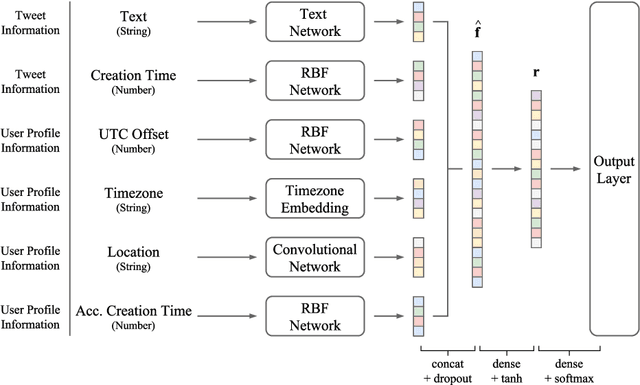
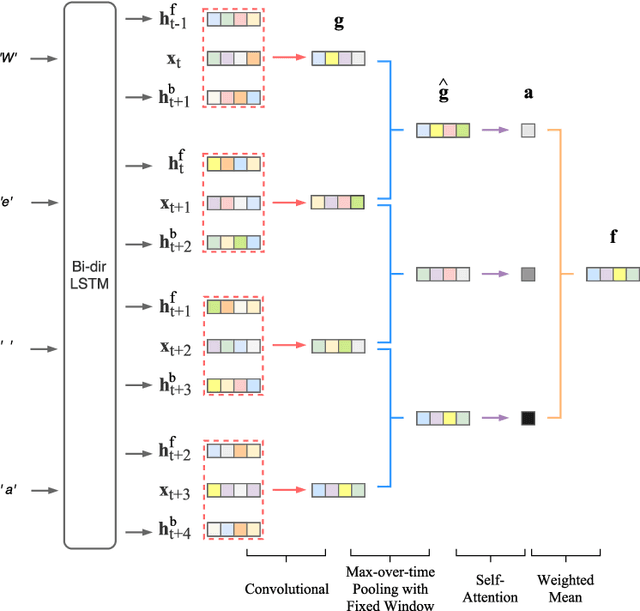
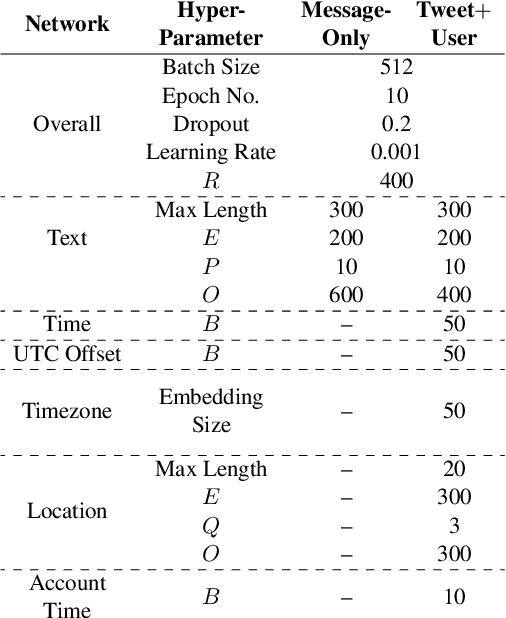
We propose an end-to-end neural network to predict the geolocation of a tweet. The network takes as input a number of raw Twitter metadata such as the tweet message and associated user account information. Our model is language independent, and despite minimal feature engineering, it is interpretable and capable of learning location indicative words and timing patterns. Compared to state-of-the-art systems, our model outperforms them by 2%-6%. Additionally, we propose extensions to the model to compress representation learnt by the network into binary codes. Experiments show that it produces compact codes compared to benchmark hashing algorithms. An implementation of the model is released publicly.