 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGA: Second-Order Gradient Alignment for Catastrophic Forgetting Mitigation in GFSCIL
Apr 18, 2025Graph Few-Shot Class-Incremental Learning (GFSCIL) enables models to continually learn from limited samples of novel tasks after initial training on a large base dataset. Existing GFSCIL approaches typically utilize Prototypical Networks (PNs) for metric-based class representations and fine-tune the model during the incremental learning stage. However, these PN-based methods oversimplify learning via novel query set fine-tuning and fail to integrate Graph Continual Learning (GCL) techniques due to architectural constraints. To address these challenges, we propose a more rigorous and practical setting for GFSCIL that excludes query sets during the incremental training phase. Building on this foundation, we introduce Model-Agnostic Meta Graph Continual Learning (MEGA), aimed at effectively alleviating catastrophic forgetting for GFSCIL. Specifically, by calculating the incremental second-order gradient during the meta-training stage, we endow the model to learn high-quality priors that enhance incremental learning by aligning its behaviors across both the meta-training and incremental learning stages. Extensive experiments on four mainstream graph datasets demonstrate that MEGA achieves state-of-the-art results and enhances the effectiveness of various GCL methods in GFSCIL. We believe that our proposed MEGA serves as a model-agnostic GFSCIL paradigm, paving the way for future research.
DWCL: Dual-Weighted Contrastive Learning for Multi-View Clustering
Nov 26, 2024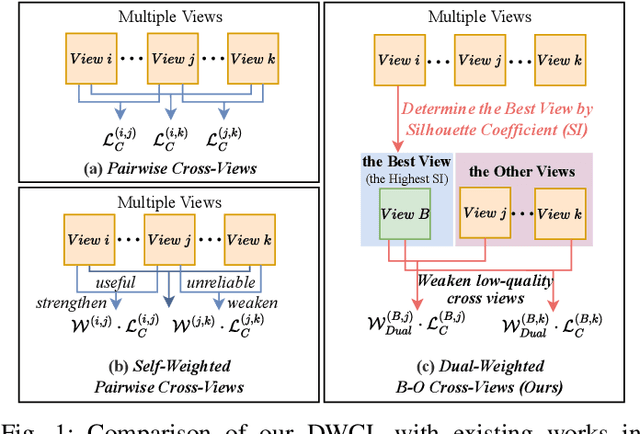
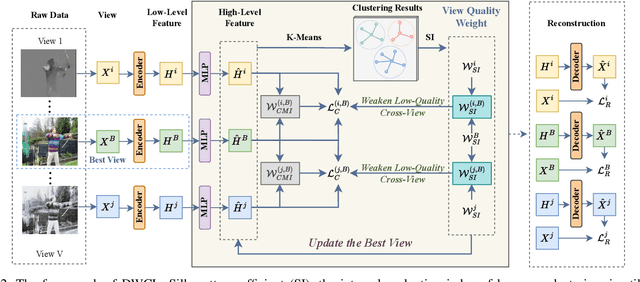
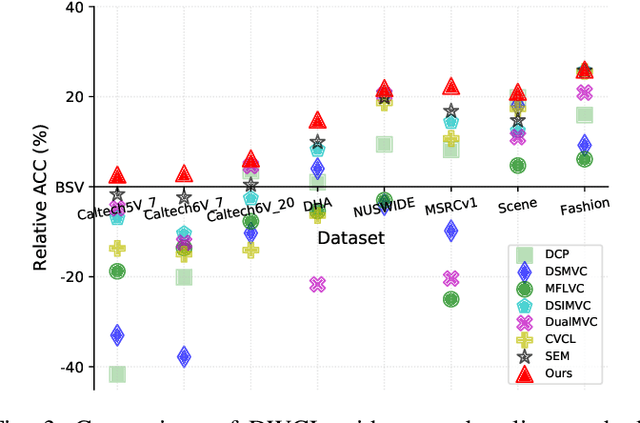
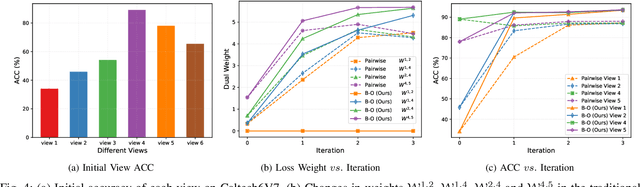
Multi-view contrastive clustering (MVCC) has gained significant attention for generating consistent clustering structures from multiple views through contrastive learning. However, most existing MVCC methods create cross-views by combining any two views, leading to a high volume of unreliable pairs. Furthermore, these approaches often overlook discrepancies in multi-view representations, resulting in representation degeneration. To address these challenges, we introduce a novel model called Dual-Weighted Contrastive Learning (DWCL) for Multi-View Clustering. Specifically, to reduce the impact of unreliable cross-views, we introduce an innovative Best-Other (B-O) contrastive mechanism that enhances the representation of individual views at a low computational cost. Furthermore, we develop a dual weighting strategy that combines a view quality weight, reflecting the quality of each view, with a view discrepancy weight. This approach effectively mitigates representation degeneration by downplaying cross-views that are both low in quality and high in discrepancy. We theoretically validate the efficiency of the B-O contrastive mechanism and the effectiveness of the dual weighting strategy. Extensive experiments demonstrate that DWCL outperforms previous methods across eight multi-view datasets, showcasing superior performance and robustness in MVCC. Specifically, our method achieves absolute accuracy improvements of 5.4\% and 5.6\% compared to state-of-the-art methods on the Caltech6V7 and MSRCv1 datasets, respectively.
ESC-MISR: Enhancing Spatial Correlations for Multi-Image Super-Resolution in Remote Sensing
Nov 07, 2024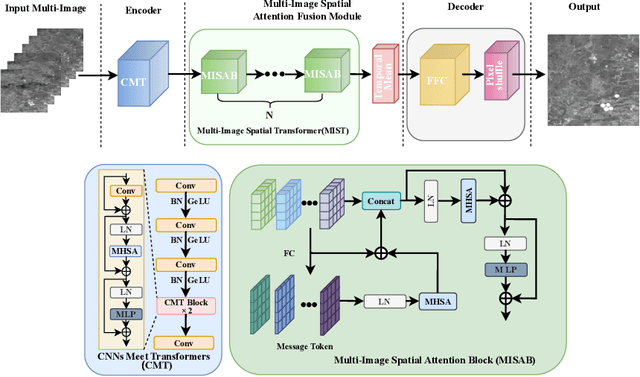
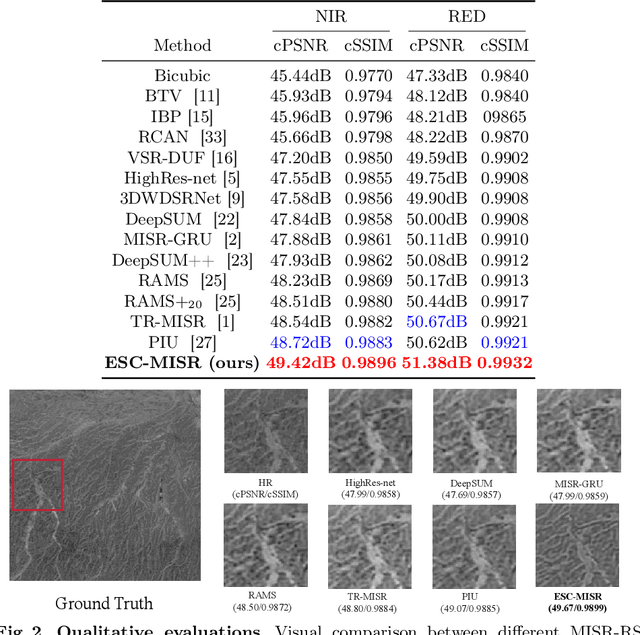
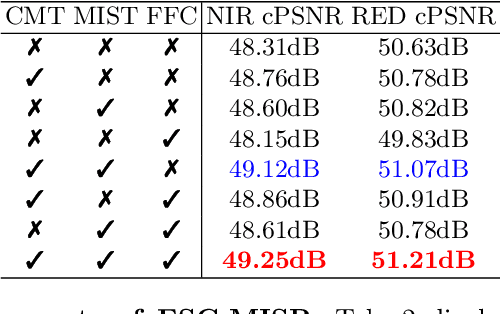

Multi-Image Super-Resolution (MISR) is a crucial yet challenging research task in the remote sensing community. In this paper, we address the challenging task of Multi-Image Super-Resolution in Remote Sensing (MISR-RS), aiming to generate a High-Resolution (HR) image from multiple Low-Resolution (LR) images obtained by satellites. Recently, the weak temporal correlations among LR images have attracted increasing attention in the MISR-RS task. However, existing MISR methods treat the LR images as sequences with strong temporal correlations, overlooking spatial correlations and imposing temporal dependencies. To address this problem, we propose a novel end-to-end framework named Enhancing Spatial Correlations in MISR (ESC-MISR), which fully exploits the spatial-temporal relations of multiple images for HR image reconstruction. Specifically, we first introduce a novel fusion module named Multi-Image Spatial Transformer (MIST), which emphasizes parts with clearer global spatial features and enhances the spatial correlations between LR images. Besides, we perform a random shuffle strategy for the sequential inputs of LR images to attenuate temporal dependencies and capture weak temporal correlations in the training stage. Compared with the state-of-the-art methods, our ESC-MISR achieves 0.70dB and 0.76dB cPSNR improvements on the two bands of the PROBA-V dataset respectively, demonstrating the superiority of our method.
SA-GDA: Spectral Augmentation for Graph Domain Adaptation
Aug 17, 2024Graph neural networks (GNNs) have achieved impressive impressions for graph-related tasks. However, most GNNs are primarily studied under the cases of signal domain with supervised training, which requires abundant task-specific labels and is difficult to transfer to other domains. There are few works focused on domain adaptation for graph node classification. They mainly focused on aligning the feature space of the source and target domains, without considering the feature alignment between different categories, which may lead to confusion of classification in the target domain. However, due to the scarcity of labels of the target domain, we cannot directly perform effective alignment of categories from different domains, which makes the problem more challenging. In this paper, we present the \textit{Spectral Augmentation for Graph Domain Adaptation (\method{})} for graph node classification. First, we observe that nodes with the same category in different domains exhibit similar characteristics in the spectral domain, while different classes are quite different. Following the observation, we align the category feature space of different domains in the spectral domain instead of aligning the whole features space, and we theoretical proof the stability of proposed \method{}. Then, we develop a dual graph convolutional network to jointly exploits local and global consistency for feature aggregation. Last, we utilize a domain classifier with an adversarial learning submodule to facilitate knowledge transfer between different domain graphs. Experimental results on a variety of publicly available datasets reveal the effectiveness of our \method{}.
FTF-ER: Feature-Topology Fusion-Based Experience Replay Method for Continual Graph Learning
Jul 28, 2024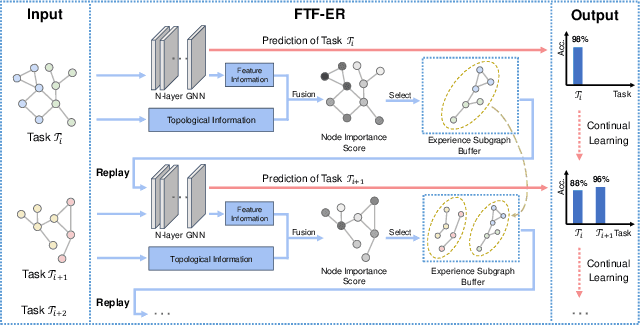
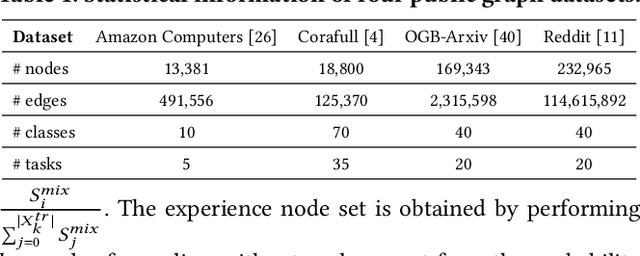
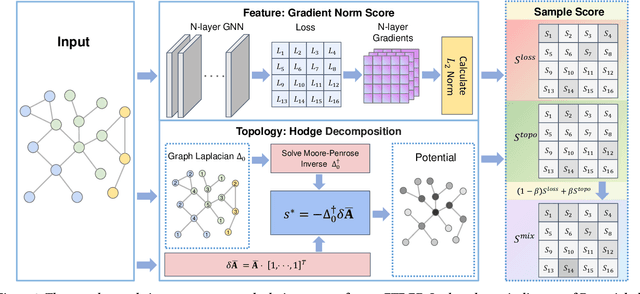
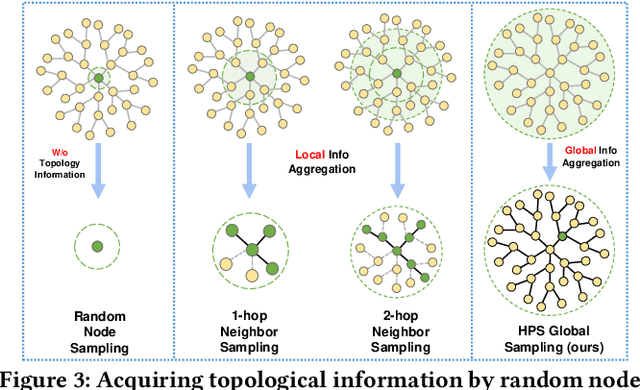
Continual graph learning (CGL) is an important and challenging task that aims to extend static GNNs to dynamic task flow scenarios. As one of the mainstream CGL methods, the experience replay (ER) method receives widespread attention due to its superior performance. However, existing ER methods focus on identifying samples by feature significance or topological relevance, which limits their utilization of comprehensive graph data. In addition, the topology-based ER methods only consider local topological information and add neighboring nodes to the buffer, which ignores the global topological information and increases memory overhead. To bridge these gaps, we propose a novel method called Feature-Topology Fusion-based Experience Replay (FTF-ER) to effectively mitigate the catastrophic forgetting issue with enhanced efficiency. Specifically, from an overall perspective to maximize the utilization of the entire graph data, we propose a highly complementary approach including both feature and global topological information, which can significantly improve the effectiveness of the sampled nodes. Moreover, to further utilize global topological information, we propose Hodge Potential Score (HPS) as a novel module to calculate the topological importance of nodes. HPS derives a global node ranking via Hodge decomposition on graphs, providing more accurate global topological information compared to neighbor sampling. By excluding neighbor sampling, HPS significantly reduces buffer storage costs for acquiring topological information and simultaneously decreases training time. Compared with state-of-the-art methods, FTF-ER achieves a significant improvement of 3.6% in AA and 7.1% in AF on the OGB-Arxiv dataset, demonstrating its superior performance in the class-incremental learning setting.
WOC: A Handy Webcam-based 3D Online Chatroom
Sep 02, 2022

We develop WOC, a webcam-based 3D virtual online chatroom for multi-person interaction, which captures the 3D motion of users and drives their individual 3D virtual avatars in real-time. Compared to the existing wearable equipment-based solution, WOC offers convenient and low-cost 3D motion capture with a single camera. To promote the immersive chat experience, WOC provides high-fidelity virtual avatar manipulation, which also supports the user-defined characters. With the distributed data flow service, the system delivers highly synchronized motion and voice for all users. Deployed on the website and no installation required, users can freely experience the virtual online chat at https://yanch.cloud.