 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeX-ViT: A Novel eXplainable Vision Transformer for Weakly Supervised Semantic Segmentation
Jul 12, 2022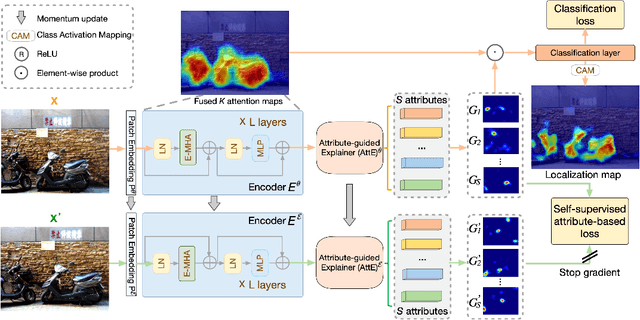



Recently vision transformer models have become prominent models for a range of vision tasks. These models, however, are usually opaque with weak feature interpretability. Moreover, there is no method currently built for an intrinsically interpretable transformer, which is able to explain its reasoning process and provide a faithful explanation. To close these crucial gaps, we propose a novel vision transformer dubbed the eXplainable Vision Transformer (eX-ViT), an intrinsically interpretable transformer model that is able to jointly discover robust interpretable features and perform the prediction. Specifically, eX-ViT is composed of the Explainable Multi-Head Attention (E-MHA) module, the Attribute-guided Explainer (AttE) module and the self-supervised attribute-guided loss. The E-MHA tailors explainable attention weights that are able to learn semantically interpretable representations from local patches in terms of model decisions with noise robustness. Meanwhile, AttE is proposed to encode discriminative attribute features for the target object through diverse attribute discovery, which constitutes faithful evidence for the model's predictions. In addition, a self-supervised attribute-guided loss is developed for our eX-ViT, which aims at learning enhanced representations through the attribute discriminability mechanism and attribute diversity mechanism, to localize diverse and discriminative attributes and generate more robust explanations. As a result, we can uncover faithful and robust interpretations with diverse attributes through the proposed eX-ViT.