 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimaBench: A Benchmark Dataset For Climate Change Text Understanding in English
Jan 11, 2023



The topic of Climate Change (CC) has received limited attention in NLP despite its real world urgency. Activists and policy-makers need NLP tools in order to effectively process the vast and rapidly growing textual data produced on CC. Their utility, however, primarily depends on whether the current state-of-the-art models can generalize across various tasks in the CC domain. In order to address this gap, we introduce Climate Change Benchmark (ClimaBench), a benchmark collection of existing disparate datasets for evaluating model performance across a diverse set of CC NLU tasks systematically. Further, we enhance the benchmark by releasing two large-scale labelled text classification and question-answering datasets curated from publicly available environmental disclosures. Lastly, we provide an analysis of several generic and CC-oriented models answering whether fine-tuning on domain text offers any improvements across these tasks. We hope this work provides a standard assessment tool for research on CC text data.
Masked Measurement Prediction: Learning to Jointly Predict Quantities and Units from Textual Context
Dec 16, 2021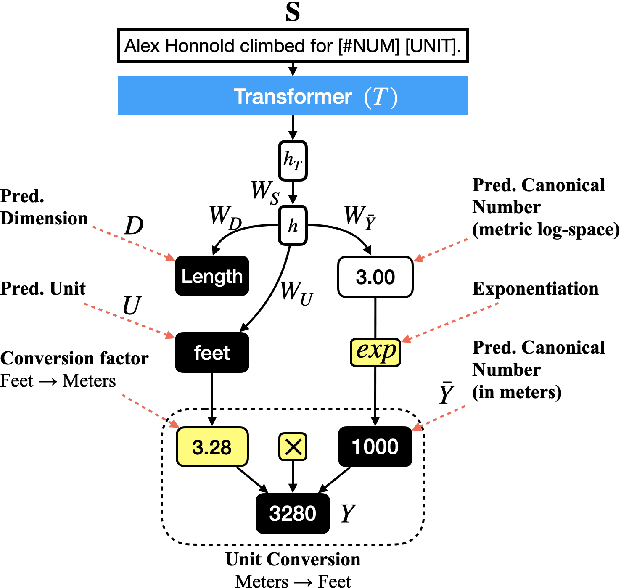
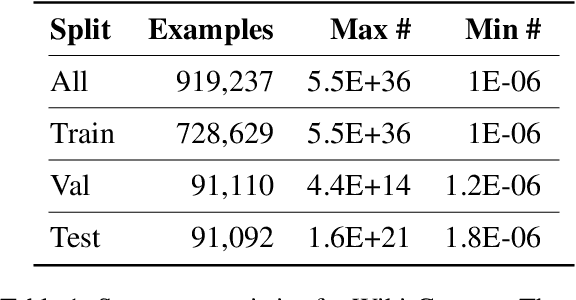
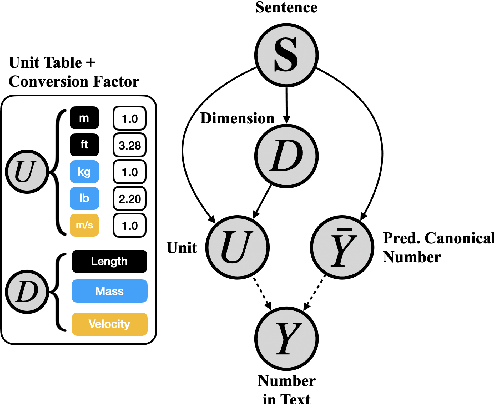
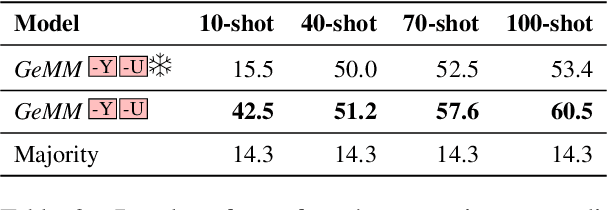
Physical measurements constitute a large portion of numbers in academic papers, engineering reports, and web tables. Current benchmarks fall short of properly evaluating numeracy of pretrained language models on measurements, hindering research on developing new methods and applying them to numerical tasks. To that end, we introduce a novel task, Masked Measurement Prediction (MMP), where a model learns to reconstruct a number together with its associated unit given masked text. MMP is useful for both training new numerically informed models as well as evaluating numeracy of existing systems. In order to address this task, we introduce a new Generative Masked Measurement (GeMM) model that jointly learns to predict numbers along with their units. We perform fine-grained analyses comparing our model with various ablations and baselines. We use linear probing of traditional pretrained transformer models (RoBERTa) to show that they significantly underperform jointly trained number-unit models, highlighting the difficulty of this new task and the benefits of our proposed pretraining approach. We hope this framework accelerates the progress towards building more robust numerical reasoning systems in the future.
Lagging Inference Networks and Posterior Collapse in Variational Autoencoders
Jan 28, 2019
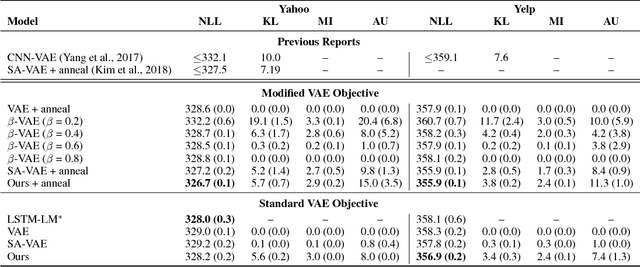
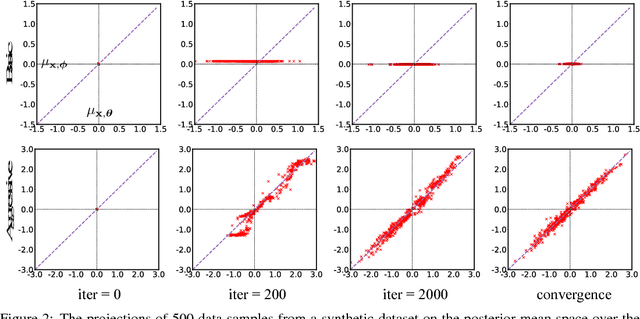
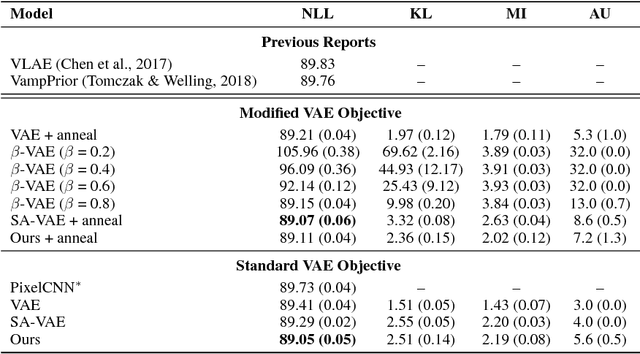
The variational autoencoder (VAE) is a popular combination of deep latent variable model and accompanying variational learning technique. By using a neural inference network to approximate the model's posterior on latent variables, VAEs efficiently parameterize a lower bound on marginal data likelihood that can be optimized directly via gradient methods. In practice, however, VAE training often results in a degenerate local optimum known as "posterior collapse" where the model learns to ignore the latent variable and the approximate posterior mimics the prior. In this paper, we investigate posterior collapse from the perspective of training dynamics. We find that during the initial stages of training the inference network fails to approximate the model's true posterior, which is a moving target. As a result, the model is encouraged to ignore the latent encoding and posterior collapse occurs. Based on this observation, we propose an extremely simple modification to VAE training to reduce inference lag: depending on the model's current mutual information between latent variable and observation, we aggressively optimize the inference network before performing each model update. Despite introducing neither new model components nor significant complexity over basic VAE, our approach is able to avoid the problem of collapse that has plagued a large amount of previous work. Empirically, our approach outperforms strong autoregressive baselines on text and image benchmarks in terms of held-out likelihood, and is competitive with more complex techniques for avoiding collapse while being substantially faster.